Vol. 11 No. 2, January 2006
| Vol. 11 No. 2, January 2006 | ||||
Introduction. Specialised subject gateways have become an essential tool for locating and accessing digital information resources, with the added value of organisation and previous evaluation catering for the needs of the varying communities using these. Within the framework of a research project on the subject, a software tool has been developed that enables subject gateways to be developed and managed.
Method. General guidelines for the work were established which set out the main principles for the technical aspects of the application, on one hand, and on aspects of the treatment and management of information, on the other. All this has been integrated into a prototype model for developing software tools.
Analysis. The needs analysis established the conditions to be fulfilled by the application. A detailed study of the available options for the treatment of information on metadata proved that the best option was to use the Dublin Core, and that the metadata set should be included, in turn, in RDF tags, or in tags based on XML.
Results. The project has resulted in the development of two versions of an application called Potnia (versions 1 and 2), which fulfil the requirements set out in the main principles, and which have been tested by users in real application environments.
Conclusion. The tagging layout found to be the best, and the one used by the writers, is based on integrating the Dublin Core metadata set within the Topic Maps paradigm, formatted in XTM.
The tools for retrieving and accessing information available on the Internet to answer users’ needs take three main forms, namely search engines, subject gateways and vertical portals. Among these, the subject gateways are gaining in popularity and importance as a source of digital information that has been chosen and assessed, and which is being provided with added value services, as described by Navarro & Tramullas (2005). This type of information service, by which is understood the structures proposed by Colomb (2002), is based on sets of documents which are browsed by the user with the aid of auxiliary information structures. Koch proposed the following definition, which is widely accepted:
Subject gateways are Internet services which support systematic resource discovery. They provide links to resources (documents, objects, sites or services), predominantly accessible via the Internet. The service is based on resource description. Browsing access to the resources via a subject structure is an important feature. (Koch 2000: 24-25)
Therefore, they are areas of information designed for a user to discover relevant information for a given need (Pitschmann 2001). Although the engines and portals have received a great deal of attention in the bibliography, this is not the case with specialised gateways, in spite of their importance as a tool for searching for and retrieving information (Robinson & Bawden 1999; Bawden & Robinson 2002). Only in Britain, thanks to the excellent development of the Resource Description Network (RDN), can one talk of high quality subject gateways.
The undertaking of a research project on subject gateways in the libraries of Spanish universities by a research group, to which the writers of this article belong, had among its objectives the creation of a software tool which, with minimum technical requirements and applying the basic principles of digital information management, would enable the rapid start-up of a specialised subject gateway A set of guidelines was established for the purpose, which would have to be adhered to both during development and for the final tool:
Bearing in mind the above, and the need for the tool to be able to evolve in line with future developments of information treatment in XML environments, in addition to new techniques for displaying large amounts of information, a free software tool was designed and implemented, called Potnia (Garrido & Tramullas 2005), distributed under a Mozilla Public License.
In line with the basic concepts mentioned above, the structure of the resource description of information conforms to standard ISO 15836 Dublin Core. However, this structure for description based on metadata reaches its full potential when it is integrated into XML coding schemes. For the digital information resource description, Dublin Core was embedded within the Resource Description Framework (RDF), with the aim of boosting its description capacity and its (future) use in the semantic web framework. Projects following this structure can be found in the literature , for example Berry & Browne (1999), Chakrabarti (2002), Firestone (2003) and Michalak (2005).
However, one of the objectives set for the Potnia tool is to develop interfaces based on visual metaphors, which will complement the usual presentation of a list of replies. The most suitable paradigm for this is to combine DC/RDF with Topic Maps (Lacher & Decker 2001), a paradigm which is contained within standard ISO 13250 (2002; Park 2003). Topic Maps have been formatted as XTM (2001) through the use of XML notation. Once the connection point has been introduced and studied in depth, it would be advisable to integrate the Dublin Core and Topic Maps. As demonstrated by Bowers ( 2000) in a study of superimposed information based on models, there are many similarities between the structural layers found in XML, RDF and Topic Maps. Therefore, it is perfectly possible, and right, to represent the majority of RDF structures through the use of syntax for topic maps, and vice-versa (Freese 2003). However, in the latter direction (representing topic maps with RDF structures) part of the semantics is lost. Since the main objective of the application is provide a greater degree of precision in the results of searches, such a loss of semantics is detrimental, and therefore it was decided to use the structure and syntax of topic maps, since these are a more modern, flexible and abstract paradigm.
In addition, topic maps have been repeatedly put forward for other projects as an extremely suitable tool for classifying and organising information. Classification tools, such as taxonomies, thesauri, ontology or faceted metadata can be integrated into topic maps, as demonstrated by Garshol (2004). In the same way, they are also more complex and allow for the development of richer, more complex information structures than the widely-used conceptual maps, which can also be integrated into XTM (Garrido & Tramullas 2004). The many examples of proprietary software tools for displaying information through topic maps, and the fact that there are open source development packages, make it possible to say that the paradigm of topic maps is the information tagging environment that offers the highest number of opportunities for developing metadata-rich digital information products, presented through graphic interfaces.
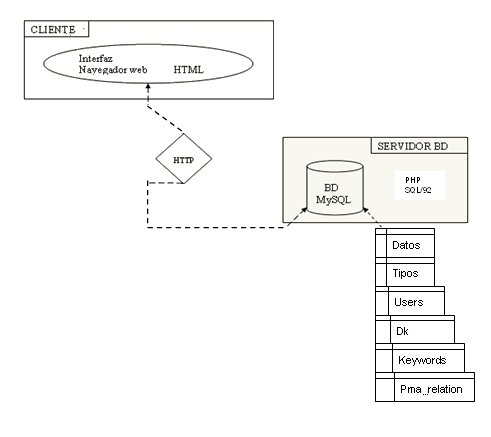
The needs analysis before the development of Potnia showed that it would be of most use on a personal or departmental level, answering the needs of special interest groups or communities. The prototype for development had very specific characteristics and was much more manageable than if a structure of specialised subject gateways had been used, such as those used by general gateways like Yahoo! or dmoz. The first objective of the design was to have the simplest possible search system, which would reduce the problem of over-complicated interfaces for novice users, and would reply faster with information in greater detail, and be more agile. The second design objective was for the users themselves from a specific discipline to gradually fill the data base supporting the information resource. The initial architecture for the application planned for this project is shown in the figure below:
The following guidelines were set for working on the development of the first version:
The technology chosen to implement this was:
Eventually, the final product was given the name Potnia. A test application can be found at http://imhotep.unizar.es/potnia. The application is distributed as open source on the following servers:
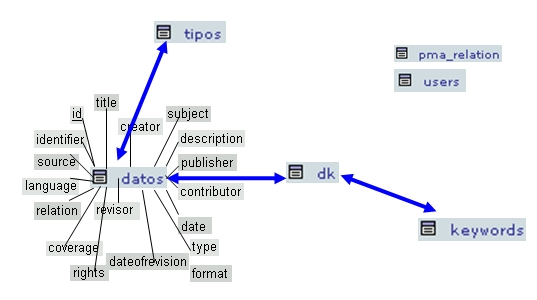
The resulting relational scheme consists of six tables: data, types, users, data-keyword relations (dk), keywords and pma_relation (Figure 1 above). This last relation proves essential when working with this version of MySQL in order to enable the database management system to interpret the relations with many-to-many cardinality. The users table remains apart from the scheme and not related to the other tables, as its only task is to centre on administering the various types of users who access the application. Tables for managing the information from the resources are the types, dk, keywords and data tables, which bear the weight of the application. When these tables are implemented, the Dublín Core Metadata Set (simple) can be used in a database relational structure.
The search process differentiates between a simple search and an advanced search, following the most common search layout interface found at present in the technology for web-based information resource gateways. As a relational database management system with textual information is being used, the recovery model needed is boolean, whose main feature is the consideration of relevance that is purely binary. This was achieved by embedding SQL code within PHP programming, which, in turn, included Javascripts and HTML code. The following figures show examples of SQL embedded code needed to execute searches:

As shown below, some decisions taken in implementation, the technology used and suggestions from persons or groups who have used Potnia, have motivated a series of decisions to be taken that have gradually affected the architecture of the application, and caused the appearance of several versions of the tool throughout its lifespan. The advantage of this idea lay in the wish to re-design Potnia. Once the first version was in operation, checked for any faults and accepted by the various groups using it, it was suggested that a second version should be developed. The first version of Potnia had been evaluated partly from suggestions and comments sent in by e-mail from various groups and individuals who had downloaded the application from Sourceforge or Freshmeat; and partly because the team working on the development were well aware that some aspects had not been included in the first version. Important among these lacks was the need to incorporate sessions, to improve the perception and running of searches by the end user, and the extension of the Dublin Core metadata set, in order to be able to use the qualified set.
Once the usefulness of the project had been evaluated, re-designing was approached by incorporating a set of improvements to different design aspects centred on the user, such as information retrieval and security. In order to fulfil these objectives, several markup languages were considered for prior representation of the information. Among these were OWL (Ontology Web Language), XML (eXtensible Markup Language) and XTM (XML Topic Maps), all highly suitable markup languages for the treatment of metadata, and which offered powerful new options to combat the deficiencies and limitations in the usual text access to digital information resources. Integration of OWL into XTM has been proven (Vatant 2004). These languages can be stored in some of the different types of information repository found on the market, such as: SGBDR, BDOO, BD natives in XML or hybrid systems. This approach can provide higher performance treatment to meta-information saved in the database and formatted to ISO 15386 standard requirements, and, obviously, to improve the display interface for the information in the not too distant future. This main objective will centre on replacing the simple interface of a text list of static replies and thus be able to use a language which is capable of representing the semantics inherent in the inter-relations targeted among the objectives (Hofmann 1999). Lastly, from the point of view of security, the application was to be improved by including sessions, a modification that will directly affect the design and programming of the user's graphic interface.
This was achieved by taking a new look at the initial design of the whole project (see work hypothesis), and incorporating XTM Topic Maps (ISO 13250) and a Hybrid Database (SGBR working with an XML manager) into its design:
Relating to the first point, integrating XTM to the resource description for digital information studied should mean that a DTD had had to be used in the first place to enable the topic map paradigms to be read by a computer (see figure 5), followed by the process of describing the information already stored in the MySQL database with the corresponding metadata, in compliance with the ISO 13250 standard. Thus, due to the flexibility of XTM and to the fact that the descriptive information of the resources has been treated previously according to ISO 15386, a simple process is used to enable an information exchange with other tools using mark-up languages such as RDF, making later development possible in the framework of semantic web technology (Beckett 2002).


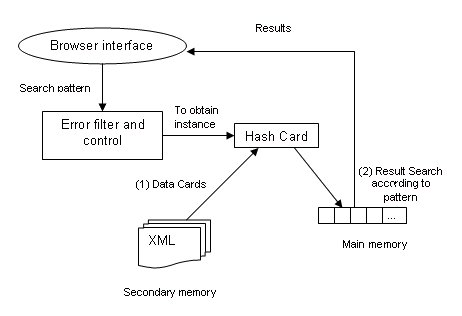
As for the second point, which involves the changeover of a purely relational database manager to a hybrid database manager (Thuraisingham 2002), it must be emphasised that the process of introducing a digital information resource within the application remains the same as in the first version, as far as the end user is concerned. However, in the internal architecture, the user opens with a validation session as the authorised user of the system, and proceeds to include the description of a resource, and, after having passed through an error control filter, passes on the process of instantiation. In this process, part of the information is instantiated in the tablespaces data and keywords, created in MySQL for the purpose, and a parallel instantiation process appears, which stores the metadata in a structure called a description file. This description file saves the data in XML in a secondary memory, thus comprising the XML manager which works with the relational database at all times. As a complement, part of the description file is stored in a hash table, in the main memory, in order to make more rapid and efficient searches. This change in the architecture has, in turn, forced a change in the architecture of the search system, with the search process being structured as shown in Figure 6.
The development of tools for information management needs to have an inter-disciplinary approach that will ensure the quality of the resulting products. The project described here was aimed at the needs for information management of the end users, and has determined the main features on the Potnia application. Technical problems were solved by using the topic maps paradigm to provide the information with semantics (Rath 2001). This enables the search processes to be refined and adjusted, as they establish points of contact between the keywords which were ignored by the traditional process of treatment and retrieval of information used initially. In addition, the greater advantages obtained by incorporating a hybrid manager into the application has improved the speed of reply on the search engine
However, one of the drawbacks that may arise from this new version is the use of an XML manager, since this does not allow for the most suitable treatment for textual information in the case of more complex searches. For this reason, the use of soft-computing techniques is being analysed to solve problems arising from this type of retrieval.
The future development of Potnia will take the following aspects into account:
| Find other papers on this subject. |
|||
© the authors, 2006. Last updated: 17 December, 2005 |
|