The autonomous turn in information behaviour
Michael Ridley
Introduction. Autonomous, intelligent information systems and agents are becoming ubiquitous and appear to engage in information behaviours that constitute a new model or framework.
Methods. By examining the nature of artificial intelligence systems and their algorithmic basis, a description of autonomous information behaviour is proposed.
Analysis. While autonomous and human information behaviours utilize both similar and different strategies, they share the same objectives with respect to information need and use.
Results. A preliminary model of autonomous information behaviour is proposed, and selected features of that model are compared with existing human behaviour models.
Conclusion. Autonomous, intelligent agents and systems engage in new forms of information behaviour. Creating information behaviour models or frameworks from these systems will not only contribute to their understanding but also facilitate the development of more effective and equitable systems.
Introduction
Autonomous, intelligent systems or agents (artificial intelligence) are challenging notions of information behaviour. Models of information behaviour or practice are typically human-centric (Bates, 2010; Case and Given, 2016; Fisher, Erdelez and McKechnie, 2005; Wilson, 2010). The autonomous turn recognizes that artificial intelligences (or more specifically autonomous, intelligent algorithms) share the same characteristics as human information behaviour models. As with humans, artificial intelligences ‘need, seek, manage, give, and use information in different contexts’.
Autonomous information behaviour describes the manner in which artificial intelligence engage in a relevant information space. The preliminary considerations presented here attempt to outline how autonomous and human information behaviours are both similar and different.
The user turn in information behaviour research shifted focus from information systems to ‘human beings as actively constructing rather than passively processing information’ (Dervin and Nilan, 1986). This user focus, and the socially constructed view of information behaviour that followed, rebalanced the field integrating people, social and contextual concerns, systems, and information (Savolainen, 1995). A digital turn occurred as researchers explored the impact of digital technologies and tools (Jaeger and Burnett, 2010; Savolainen and Kari, 2004). The cognitive turn, particularly as represented by the Mediator Model (Ingwersen, 1992; Ingwersen and Järvelin, 2005), explored the idea of an intelligent agent in information behaviour, albeit restricted to the information retrieval domain and never implemented as an operational system.
Autonomous information behaviour is neither a return to a system focus nor a privileging of the digital format. While an artificial intelligence is clearly a digital information system, its information behaviour is unique because of its autonomous capacity, thereby realizing in a wider domain Ingwersen’s concepts. Autonomous information behaviour acknowledges the agency of artificial intelligence (Latour, 2005; Malafouris, 2013). They are, in Floridi’s assessment, ‘inforgs’ (informational organisms) (Floridi, 2011). These characteristics cause researchers to regard artificial intelligences not as systems or tools but as agents, partners, colleagues, and for libraries, even ‘a new kind of patron’ (Bourg, 2017; Nass, Moon, Morkes, Kim and Fogg, 1997).
As autonomous, intelligent systems proliferate, formulating an autonomous information behaviour model is important for understanding of how these systems operate and impact society. More urgently, there is concern and evidence that these algorithms exhibit bias, inequity, and lack of fairness that compromise their effectiveness (Eubanks, 2018; Noble, 2018; O’Neil, 2016; Pasquale, 2015). Developing and validating an autonomous information behaviour model will further attempts to create more equitable artificial intelligences.
The autonomous model
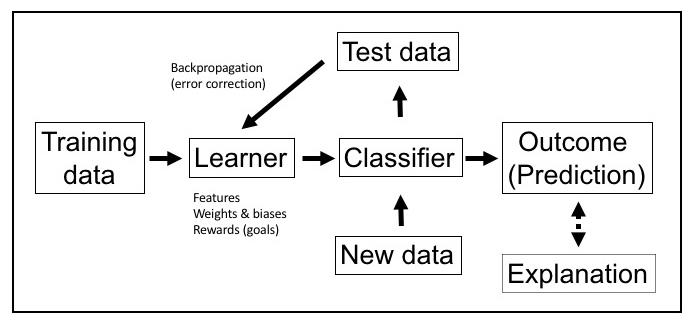
Figure 1: Autonomous information behaviour model
This simplified schematic of a machine learning model identifies the key components and their interrelationships and represents a preliminary description of autonomous information behaviour. Training data is collected in as much volume as possible with ~30% of that data set aside as test data to be used later for validation. The learner, with its goals implemented as features, weights, biases, and rewards, ingests and analyses the training data. The classifier represents the various policies or models that operate on the learned data and determines the outcome (prediction).
Test data is used in error correction. Backpropagation explores the error rates between the training data and the test data with respect to the outcome (prediction). Reducing the error rate (i.e. getting closer to optimal performance) is accomplished by a combination of ingesting more data, tuning the learner through the hand engineering (i.e. human intervention) of features, weights, and biases, and by increasing the size of the classifier (e.g. a larger neural network). When the error rate is deemed acceptable, the model is annealed and used with new data to generate outcomes.
For supervised and unsupervised learning, the model is fixed at this point. A significant difference in reinforcement learning is that the learner and the classifier are combined into one model (with limited or no hand engineering) and tasked with continuous learning and prediction. Lastly, since both unsupervised learning and reinforcement learning are opaque, an explanation is often needed to explain the outcome or prediction to a human user/subject.
As with the processes of human information behaviour, the mechanisms or mechanics of autonomous information behaviour (i.e. the learners and the classifiers) are both contextual and evolving. The specific prediction and classifier models used by artificial intelligence (e.g. artificial neural networks, convolutional neural networks, generative adversarial networks, decision trees, rules, and many others) have individual strengths and weaknesses, and are selected and tuned for particular tasks (e.g. image analysis, speech recognition, text comprehension) (Goodfellow, Bengio and Courville, 2016). These different contexts engage specific models or even ensembles where multiple approaches are used. Information seeking and use models differ for such objectives as game tactics, drug discovery or recommendation systems.
These models are clustered into two general strategies: supervised learning, where training data and defined outcomes direct the model (e.g. show the model lots of cats so it can recognize a cat in the future), and unsupervised learning, where a trial and error approach allows the model to explore the data more independently (e.g. give the model only basic rules or guidance and allow it to explore and test options on its own).
Need and opacity
Human information behaviour models typically originate with some sort of gap, uncertainty or need (Belkin, 1980; Dervin, 2003; Kuhlthau, 1991). In autonomous systems, gaps, uncertainties or needs are best understood as problem definitions provided explicitly by the system designers for the particular requirement. While in this example humans are integral features of the overall autonomous information behaviour (in their role as establishing the need and receiving the prediction or outcome), increasingly artificial intelligences are defining their own need or gap, with the output of one artificial intelligence providing the input to another (Gil, Greaves, Hendler and Hirsh, 2014).
The opacity of advanced artificial intelligence models such as deep learning, a form of neural network (LeCun, Bengio and Hinton, 2015), presents a significant barrier to understanding and defining autonomous information behaviour. As Geoffrey Hinton notes: ‘a deep-learning system doesn’t have any explanatory power. The more powerful the deep-learning system becomes, the more opaque it can become’ (Mukherjee, 2017, p. 53). A deep learning system can be inscrutable, and resist attempts at transparency and explainability. Research on explainable artificial intelligence is attempting to develop processes and strategies to make algorithmic systems interpretable and to provide methods for human-level explanations (DARPA, 2016).
Overfitting and dimensionality
To better understand the nature of autonomous information behaviour, it is useful to examine two typical aspects of human models and identify comparators in an autonomous model. Concluding an information search prematurely is a feature of human models. This rush to judgement is an inadequate exploration of the information space resulting in a conclusion that precludes the use of potentially relevant information. A similar characteristic appears in an autonomous model. Overfitting is the term used to describe artificial intelligences that make a decision or prediction based on a limited amount of data (Buduma, 2017). Further exploration of the information space would have (or might have) identified additional information that would have altered the prediction. Autonomous systems use various randomizing techniques and feature weightings as means to prevent overfitting.
Another feature of human information behaviour is information overload. In this case, too much information is gathered (or is available) resulting in an inability to synthesize and come to a satisfactory conclusion. In autonomous models, this situation is characterized as an exponentially expanding information space and is referred to as the curse of dimensionality (Domingos, 2015). Even with advanced computational power, the size and complexity of the space is too large to manage in a reasonable timeframe. AlphaGo Zero navigated the Go information space (very large and complex) but it required 40 days and 29 million training games to do so (Silver et al., 2017). Autonomous systems manage this by constructing higher level models (approximations), auditing features with low value, and techniques like chunking and pruning which penalize overly complex models.
The most obvious characteristics that differentiate autonomous from human information behaviours are the underlying statistical models and computational substrates required to process them. Artificial intelligence systems are statistically driven (Domingos, 2015; Goodfellow et al., 2016). The features of the data elements used in learning and classifying are essentially weights, values, and computations of them. Understanding information behaviour as a statistical process is at the core of the autonomous model.
Conclusion
A crucial divide in the artificial intelligence community is whether the overarching objective is to replicate human intelligence or create a different type of intelligence (Boden, 2016). In assessing autonomous information behaviour there is tendency to establish human performance as the appropriate benchmark even when greater than or different than human performance may be indicated or achievable. Much of artificial intelligence is modelled on human cognition (artificial neural networks were inspired by human neurology), but performance levels are in some cases greater. Fazi suggests that autonomous machines are capable of new ideas not by imitating human cognition (i.e. simulation) but by allowing machines to fully exploit their computational advantage (even if that results in ‘alien thought’) (Fazi, 2018). While the similarities between autonomous and human information behaviours is instructive, it is the differences that may point towards new methods of information use. As DeepMind founder Demis Hassabis noted, in its game play AlphaGo Zero was ‘creative’ and ‘no longer constrained by the limits of human knowledge’ (Knapton, 2017).
There is considerable debate, within the artificial intelligence community and beyond, about the generalizability of a system’s autonomy and intelligence (Marcus, 2018). Performance levels at or beyond those of humans are typically in very specific and restricted knowledge domains. Much of what is called artificial intelligence is often conventional statistical manipulation with little or no autonomy (Bogost, 2017). However, even with those caveats, it is clear that artificial intelligence can ‘need, seek, manage, give, and use information in different contexts’ and thereby reflect distinct information behaviours. While intentionality may remain in question, the autonomous systems in operation and in development open new avenues for investigation and mark an autonomous turn in information behaviour. Future research needs to examine more closely the various learner and classifier models to determine if differences among them constitute different behaviour models or if they can be integrated into a single framework.
Acknowledgements
The author thanks the two anonymous reviewers for helpful and probing comments, and valuable recommendations.
About the author
Michael Ridley is a PhD student, Faculty of Information and Media Studies (FIMS), Western University. His research interests are artificial intelligence, information behaviour, and literacy. He can be contacted at mridley@uoguelph.ca on www.MichaelRidley.ca, and @mridley
References
- Bates, M.J. (2010). Information behavior. In M.J. Bates & M.N. Maack (Eds.), Encyclopedia of library and information sciences (3rd ed., pp. 2381–2391). Boca Raton, FL: CRC Press.
- Belkin, N.J. (1980). Anomalous states of knowledge as a basis for information retrieval. Canadian Journal of Information Science, 5, 133–143.
- Boden, M.A. (2016). AI: Its nature and future. Oxford: Oxford University Press.
- Bogost, I. (2017). “Artificial intelligence” has become meaningless. The Atlantic. Retrieved from www.theatlantic.com/technology/archive/2017/03/what-is-artificial-intelligence/518547/
- Bourg, C. (2017, March 17). What happens to libraries and librarians when machines can read all the books? Retrieved from https://chrisbourg.wordpress.com/2017/03/16/what-happens-to-libraries-and-librarians-when-machines-can-read-all-the-books/
- Buduma, N. (2017). Fundamentals of deep learning: designing next-generation machine intelligence algorithms. Sebastopol, CA: O’Reilly.
- Case, D.O. & Given, L.M. (2016). Looking for information: a survey of research on information seeking, needs and behavior (4th ed.). Bingley, UK: Emerald Group Publishing.
- DARPA (2016). Explainable artificial intelligence (XAI). Arlington, VA: DARPA. Retrieved from http://www.darpa.mil/attachments/DARPA-BAA-16-53.pdf
- Dervin, B. (2003). Sense-making methodology reader: selected writings of Brenda Dervin. Cresskill, N.J.: Hampton Press.
- Dervin, B. & Nilan, M. (1986). Information needs and uses. Annual Review of Information Science and Technology, 21, pp. 3–33.
- Domingos, P. (2015). The master algorithm: how the quest for the ultimate learning machine will remake our world. New York, NY: Basic Books.
- Eubanks, V. (2018). Automating inequity: how high-tech tools profile, police, and punish the poor. New York, NY: St. Martin’s Press.
- Fazi, M. B. (2018). Can a machine think (anything new)? Automation beyond simulation. AI & Society, 1–12. doi:10.1007/s00146-018-0821-0
- Fisher, K.E., Erdelez, S. & McKechnie, L. (Eds.). (2005). Theories of information behavior. Medford, NJ: American Society for Information Science and Technology.
- Floridi, L. (2011). The philosophy of information. Oxford: Oxford University Press.
- Gil, Y., Greaves, M., Hendler, J. & Hirsh, H. (2014). Amplify scientific discovery with artificial intelligence. Science, 346(6206), 171–172. doi: 10.1126/science.1259439
- Goodfellow, I., Bengio, Y. & Courville, A. (2016). Deep learning. Boston, MA: MIT Press.
- Ingwersen, P. (1992). Information retrieval interaction. London: Taylor Graham.
- Ingwersen, P. & Järvelin, K. (2005). The turn: integration of information seeking and retrieval in context. Dordrecht, Germany: Springer.
- Jaeger, P.T. & Burnett, G. (2010). Information worlds: social context, technology, and information behavior in the age of the Internet. New York, NY: Routledge.
- Knapton, S. (2017, October 18). AlphaGo Zero: Google DeepMind supercomputer learns 3,000 years of human knowledge in 40 days. The Telegraph. Retrieved from http://www.telegraph.co.uk/science/2017/10/18/alphago-zero-google-deepmind-supercomputer-learns-3000-years/amp/
- Kuhlthau, C.C. (1991). Inside the search process: Information seeking from the user’s perspective. Journal of the American Society for Information Science, 42(5), 361–371.
- Latour, B. (2005). Reassembling the social: An introduction to actor-network-theory. Oxford: Oxford University Press.
- LeCun, Y., Bengio, Y. & Hinton, G. (2015). Deep learning. Nature, 521, 436–444. doi: 10.1038/nature14539
- Malafouris, L. (2013). How things shape the mind: a theory of material engagement. Cambridge, MA: MIT Press.
- Marcus, G. (2018). Deep learning: a critical appraisal. Retrieved from http://arxiv.org/abs/1801.00631
- Mukherjee, S. (2017, April 3). The algorithm will see you now. The New Yorker, 46– 53.
- Nass, C.I., Moon, Y., Morkes, J., Kim, E.-Y. & Fogg, B. J. (1997). Computers are social actors: a review of current research. In B. Friedman (Ed.), Human values and the design of computer technology (pp. 137–162). New York, NY: Cambridge University Press.
- Noble, S.U. (2018). Algorithms of oppression: How search engines reinforce racism. New York, NY: New York University Press.
- O’Neil, C. (2016). Weapons of math destruction: how big data increases inequality and threatens democracy. New York, NY: Crown.
- Pasquale, F. (2015). The black box society: the secret algorithms that control money and information. Cambridge, MA: Harvard University Press.
- Savolainen, R. (1995). Everyday life information seeking: approaching information seeking in the context of “way of life.” Library and Information Science Research, 17(3), 259–294. doi: 10.1016/0740-8188(95)90048-9
- Savolainen, R. & Kari, J. (2004). Conceptions of the internet in everyday life information seeking. Journal of Information Science, 30(3), 219–226. https://doi.org/10.1177/0165551504044667
- Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A. & Guez, A. (2017). Mastering the game of Go without human knowledge. Nature, 550, 354–359. doi: 10.1038/nature24270
- Wilson, T.D. (2010). Information behavior models. In M.J. Bates & M.N. Maack (Eds.), Encyclopedia of library and information sciences (3rd ed., pp. 2391–2400). Boca Raton, FL: CRC Press.