 |
| About IR |
| Editors |
| Author instructions |
| Copyright |
| Author index |
| Subject index |
| Search |
| Reviews |
| Register |
| Home |
RefViz Version 2. Berkeley, CA: Thomson/ISI ResearchSoft, 2005. CD-ROM. $299.95 Introductory price $149.95 until 31 July 2005
About eighteeen months ago we published a review of the first version of this vizualization software as part of the review of a new edition of EndNote. Now we have version 2, which is smoother in operation than the first version, but which, otherwise, does not incorporate much in the way of new features.
The main addition is the possibility of running an external search on bibliographic databases directly from RefViz, rather than first into EndNote or Reference Manager. However, the range of sites suggested is rather limited and some, e.g., the Library of Congress, do not provide sufficient information on an item for RefViz to function: it needs an abstract and most library catalogues do not provide these.
There is the further limitation that access to other databases requires recognition of an IP address as a valid address, which means that I cannot access Web of Science, which requires password login from both of the sites I normally use.
These caveats aside, however, the 'Reference Retriever' function does work, although I'd prefer it to be activated from a menu button rather than from the 'File' menu. The figure below shows the search screen:
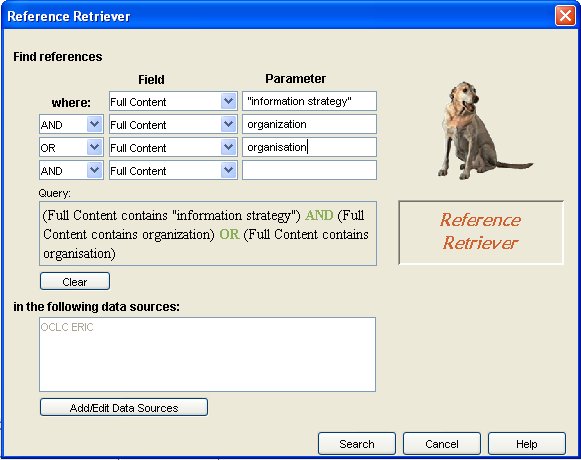
Figure 1: The Reference Retriever screen
As you can see, Boolean constructions are possible with the system; but, rather to my surprise, this search strategy revealed nothing in the ERIC database on the subject. However, a search on Web of Science, downloaded into EndNote, produced 112 items since 1995: these were picked up by RefViz and analysed, producing the distribution map shown in Figure 2.
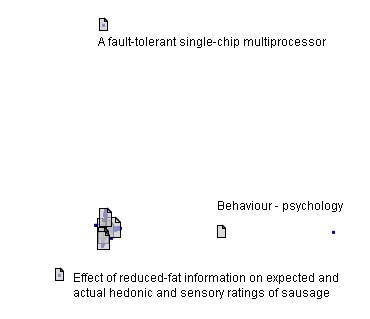
Figure 2: The 'galaxy' analysis
We can immediately see that there is a central cluster of items and three 'outliers'. I have indicated the nature of these outliers and their irrelevance to my concept of 'information strategy' will be fairly clear. ( A note on the 'sausage' item appears below—it was genuine!) Removing these and enlarging the central cluster reveals the situation in Figure 3:
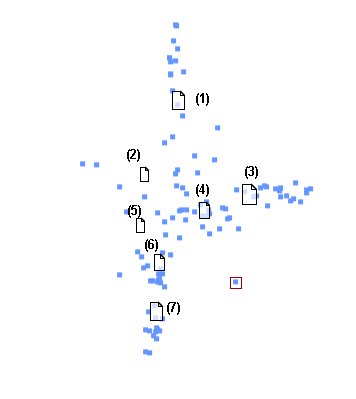
Figure 3: A second 'galaxy' analysis
Here we have seven clusters, which I have numbered from the top. We can typify these clusters as follows:
-
Change processes and models.
International factors.
Management development.
Public policy
Individual perspectives
Risk factors
Health care
In addition to the 'galaxy' view we also have a matrix view, which shows the relationships among terms. The matrix view for this particular reference set doe not illustrate the idea very well, but Figure 4 shows part of the matrix view. Cells in red show terms that frequently appear together, while those in white show no relationship at all.
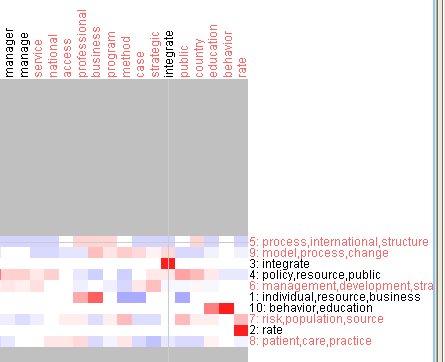
Figure 4: The matrix view
Below the main display pane of the screen, where the galaxy and matrix views are presented, is the 'reference viewer', which shows the documents that have been assigned to the cluster. In Figure 5 we see brief entries for cluster number four:

Figure 5: The reference viewer
This enables us quickly to establish whether or not a group of references is of interest to us (in this case, answer is yes) and also to weed out those references that appear to be irrelevant (in this case, about one third of the references would not be of any interest to me).
The clustering of references is affected by the terms one chooses to include in the process. Figure 6 shows the terms selected that give rise to group four as well as those that have not been selected:
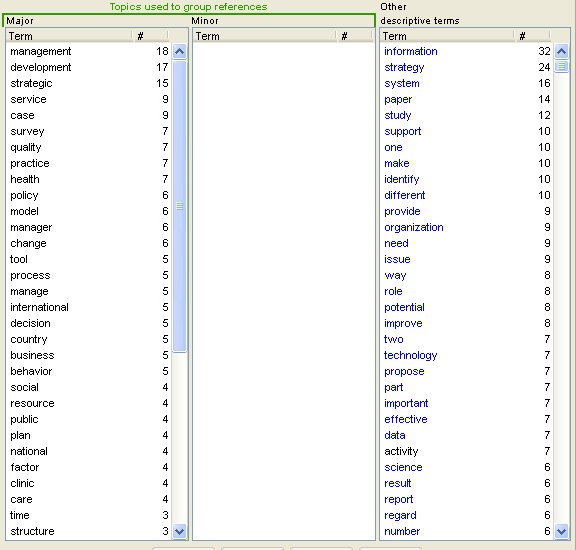
Figure 6: Term selection-1
We can now deselect some terms and select others, with the result shown in Figure 7:
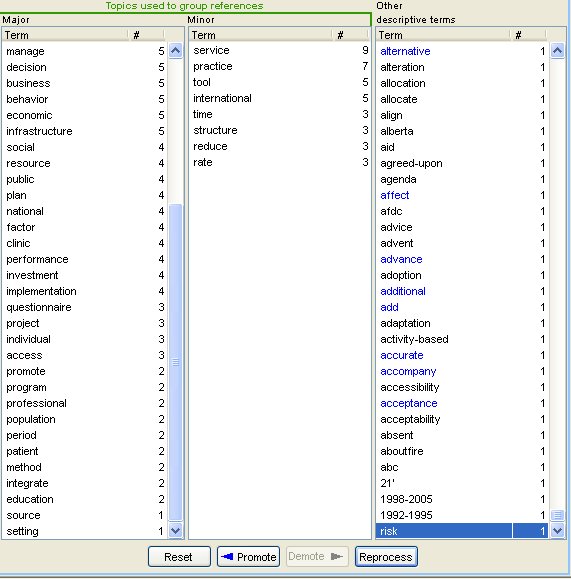
Figure 7: Term selection-2
Of course, this has an effect upon the matrix of term associations, with resulting changes in the matrix and galaxy views. The new galaxy is shown in Figure 8.

Figure 8: The galaxy reprocessed
As we see, the clusters have now been brought closer together, signifying that the associations are stronger. Further manipulation of the terms used would enable us to refine the clustering process even more and isolate that set of references most likely to be of interest. For a small file of 112 references like this, it probably isn't worth the effort, but a file with a 1,000 references would probably repay the effort.
I said in my review of the first version of RefViz: "I approached RefViz with a certain degree of scepticism, never having been convinced of the value of visualization, but I have been won over.", and this version is a much smoother operator than the first. For me, its main interest is as a bibliographic research tool (you'll find an example of its use in Maceviciute & Wilson (forthcoming)), but for many its value will lie in its ability to filter references into groups of likely interest, to reduce the time spent is scanning the output from searches.
Reference
Macevičiūtė, E. & Wilson, T.D. (forthcoming) Introducting information management: an Information Research reader. London: Facet.
Professor T.D. Wilson
Editor-in-Chief
Note: The 'sausage' reference.
In the interests of promoting scientific endeavour, here is the full reference and abstract for the 'sausage' reference: you will see how it gets into a file on 'information strategy'!
| Kahkonen, P., & Tuorila, H. (1998). Effect of reduced-fat information on expected and actual hedonic and sensory ratings of sausage. Appetite, 30(1), 13-23. |
| The effect of information about fat content on expected and actual sensory and hedonic ratings of regular-and reduced-fat Bologna sausages was studied using 115 young men. All the subjects rated the expected pleasantness, juiciness, saltiness and fattiness of "Bologna". Subsequently, a sub-group of subjects ("No information", N=54) rated the unlabelled samples after tasting. Another sub-group ("Information", N=61) rated the expected and actual pleasantness and attribute intensities of samples labelled as "Regular type of Bologna (20% fat)" and "Light Bologna (10% fat)". The samples were not rated significantly different by the "No information" group. In the "Information" group, "Light Bologna" was expected to be less fatty, less salty, less juicy and less pleasant than "Regular type of Bologna". After tasting, saltiness and fattiness of "Light Bologna" were rated lower while pleasantness and juiciness of the samples were not significantly different. Actual saltiness and fattiness of "Light Bologna" were assimilated to the low expected intensities. Even that the hedonic ratings of "Light" and "Regular type of Bologna" differed only slightly, low expected pleasantness, juiciness and other attribute intensities imply that young men would not choose the product. Other information strategies might result in better acceptance by this target group. |
How to cite this review
Wilson, T.D. (2005). Review of: RefViz Version 2. Berkeley, CA: Thomson/ISI ResearchSoft, 2005. Information Research, 10(4), review no. SR19 [Available at: http://informationr.net/ir/reviews/sofrev19/sofrev19.html]