'Information science' and research methods
Professor Tom Wilson
Professor Emeritus in Information Management
Department of Information Studies
University of Sheffield
United Kingdom
Considers the problems of defining 'information science' as a unitary discipline and suggests that the concept of integrative levels offers an explanation for the fragmentation of the field. 'Information' has different contexts at different integrative levels, and different disciplines deal with these contexts. The paper then considers how information as a social phenomenon requires social scientific research methods to be applied to its investigation and sets out a new taxonomy for social research methods.
Introduction
The nature of 'information science' has been a matter of dispute almost since the term was coined by Chris Hanson of Aslib in 1956. Curiously, the term followed the use of 'information scientist', which was used in the UK in the 1940s to describe scientists who specialised in helping their colleagues to find information. (Bottle, 1997) In other words, the original usage did not imply the existence of an information 'science', but simply a set of information practices aimed at scientists.
The difficulties with the term became evident when academic programmes in information science began to emerge and when, consequently, teachers and departments began to seek academic respectability by moving from training people in a vocational practice to searching for underlying principles and theories that would provide that respectability.
Numerous writers (e.g., Debons, 1974; Froelich, 1986; McGarry, 1987; Lancaster, 1994) have sought to define the nature of information science and set out curricula that would constitute a sound basis for a unitary discipline. However, these writers, and others disagree on what constitutes information science and, therefore, the curricula, although overlapping, do not fully agree with one another. Some argue for the inclusion of logic, mathematics, and programming; others for the inclusion of linguistics, philosophy, and economics, and so on. We have to ask, therefore, why is there lack of unanimity on what constitutes information science?
Information and integrative levels
Perhaps surprisingly, I do not think that we have to look very far for the answer. Although I have never written on the subject before (because I feel that the answer can be stated very simply and needs, perhaps, a paragraph, rather than a paper), I have long held the view that the answer lies in the concept of integrative levels.
The origins of the theory of integrative levels are unclear but the English philosopher Herbert Spencer appears to be the first to set out the general idea of increasing complexity in systems (Spencer, 1862). The term itself was first used by the English biochemist (and scholar of Chinese science) Joseph Needham (1937). The following quotation from a Web source provides an insight into the fundamentals of the theory:
(a) The structure of integrative levels rests on a physical foundation. The lowest level of scientific observation would appear to be the mechanics of particles. (b) Each level organizes the level below it plus one or more emergent qualities (or unpredictable novelties). The levels are therefore cumulative upwards, and the emergence of qualities marks the degree of complexity of the conditions prevailing at a given level, as well as giving to that level its relative autonomy. (c) The mechanism of an organization is found at the level below, its purpose at the level above. (d) Knowledge of the lower level infers an understanding of matters on the higher level; however, qualities emerging on the higher level have no direct reference to the lower-level organization. (e) The higher the level, the greater its variety of characteristics, but the smaller its population. (f) The higher level cannot be reduced to the lower, since each level has its own characteristic structure and emergent qualities. (g) An organization at any level is a distortion of the level below, the higher-level organization representing the figure which emerges from the previously organized ground. (h) A disturbance introduced into an organization at any one level reverberates at all the levels it covers. The extent and severity of such disturbances are likely to be proportional to the degree of integration of that organization. (i) Every organization, at whatever level it exists, has some sensitivity and responds in kind. ('Levels of…', n.d.)
The idea of integrative levels is widely employed today in comparative psychology, biochemistry, biology, environmental science, and many other areas. It appears to have dropped out of sight in the area of information studies, but was employed by the Classification Research Group in the UK in the 1970s as a basis for ideas on the development of a new classification scheme. (Foskett, 1978; Wilson, 1972)
What is the relevance of this for the concept of information? Quite simply, 'information' is a concept that takes different forms at different integrative levels. When the computer scientist thinks of information, he or she is thinking of units of complexity such as bits and bytes (with the byte having a different level of complexity than the bit). The information retrieval specialist, on the other hand, conceives of information in terms of strings of symbols, matching query strings against indexed strings. The librarian sees information in terms of the macro containers, i.e., books, reports, journals and, now, electronic documents of various kinds, and, indeed of a higher level of organization, the library. In other words, information itself is not a unitary concept, but has different levels of organization, around which different theories are built and practices evolved. Consequently, there cannot be a unitary information science, but only different approaches to information from the perspective of the integrative levels involved.
Many 'information sciences'
The fact that many different characterisations of information science exist can be seen in the nature of information science curricula, as pointed out above. Which information science curriculum we decide to produce will depend upon the nature of the local market for the product of educational institutions, the market for research in the field, and the competencies of local academic staff.
It is entirely reasonable, therefore, to propose a definition of 'information science' that has, at its core, a view of 'information' as something to be manipulated by computers (in fact, in Australia, departments of computer science were at one time generally known as departments of information science). On the other hand, we can propose a curriculum for information science which is based on the perception of information as a socially-constructed, economic good, which requires the methods and theories of the social sciences for its exploration. Such a curriculum would include courses on the sociology of information transfer and use, the politics of information in organization, information policy, the economics of information, and so on. From a practical point of view in relation to the market, it would need to include technological aspects of the management of information, but such courses would be informed by the generally social orientation of the programme. Most information management courses in the UK probably have an orientation of this kind and, in general and because of the confusion caused by the word science (at least in English), information management might be a better designation.
Research methods and a social information science
If we were to try to develop and research methods programme for all possible conceptions of information science we would produce a virtually unmanageable course - or one that skimmed over every possible topic from the development of computer algorithms to survey research. The recognition that there can be many different information sciences enables us to create research methods courses that are more limited in scope and directed specifically to a particular integrative level of information. Consequently, for a social information science, as set out above, a research methods course will be a course on social research methods.
However, even here we are not immune from disputes over the nature of social research and over the correct epistemological position to be taken. The major dispute, over which a great deal of printer's ink is spent, is between those who adopt a positivist view of the nature of social reality, in which social facts can be known with certainty and in which laws of cause and effect can be discovered and applied, and what can be called humanistic approaches (Hughes, 1980) The humanistic approaches generally see social reality as constructed through social action on the part of people who undertake those acts because they have meaning for them. Social construction and meaning therefore become central to most of the humanistic approaches.
Unfortunately, the terms quantitative and qualitative have become associated with the positivist and humanistic approaches, while, in fact, the counting of phenomena is an entirely valid activity in humanistic social research. This division confuses many people who wonder how, for example, an interview schedule (seen as a positivist, quantitative instrument) can be employed in qualitative research. However, we can overcome this problem, again, very simply.
An alternative typology of research methods
The starting point is that all research methods, in all disciplines are based upon observation: astronomy began by people looking at the starts, then using optical telescopes to do the same thing, then using radio telescopes and other devices to see what the naked eye could not. In physics, what cannot be observed by the eye, is observed by instruments - cloud chambers to show up the collision of particles, for example. In botany, close observation of plants gave Linnaeus his ideas for a classification scheme of plants - now we are using DNA links to do the same thing. And so on - we could go through almost every discipline and find that the original method of data collection on the relevant phenomena was observation; all that has changed, over time, is the sophistication of the instruments used to make observations where the naked eye cannot do so.
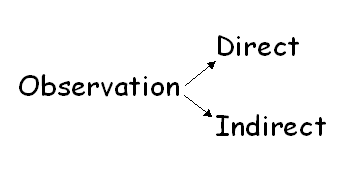
However, in social research (and, hence, in information research), observation may be direct or indirect. That is, the researcher him- or herself, may watch what is happening, or may rely on the reported observations of others.
For example, if you are interested in how people use Web search-engines, you could sit beside them during a surfing session and watch what happens, recording the different terms used for the subject and the stages the person went through. You could also log some of this information automatically - that is, the machine makes the observations for you - or you could videotape what was appearing on the screen, while you tape-recorded the person talking aloud about their activity. All of this would be direct observation.
On the other hand, you could conduct interviews with people about how they use search-engines: they would then have to recall what they did and report it to you. This assumes that people have an ability to recall earlier behaviour accurately - which may not always be true. (For example, Brewer, 2000) If you then proceed to ask them about their opinions of, or attitudes towards Web search-engines, you are asking them to observe (probably for the first time) their mental states on these issues: you are asking them to make self-observations.
Our typology of research methods, therefore, begins with observation, divided into direct and indirect modes - all social research methods can be shown to relate to this initial classification.
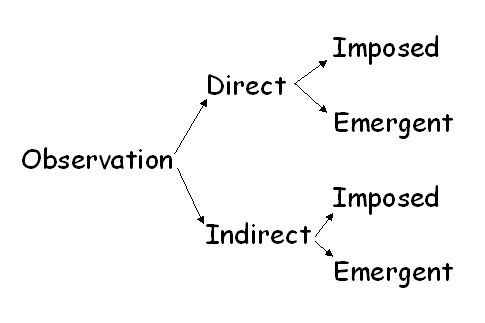
Structure now enters the classification. No data collection process can be totally lacking in structure - we will always have some ideas, derived from prior knowledge of the situation, or from the person we are approaching to interview, or from prior research or theory, or simply from our research objectives. We may wish to put all of that aside in, say, interviewing, but we cannot possibly take it out of mind completely.
The key point is whether the structure is imposed in its totality by the researcher, for example, in designing a self-completed questionnaire, or whether the structure emerges from the research process; for example, by analysing interview transcripts and developing a conceptual structure in the process.
Applying this idea of structure then gives us four categories of methods - direct observation with either imposed or emergent structure; and indirect observation with either imposed or emergent structure.
Once we have this classification we can assign social research methods in a straightforward way, shown in this third diagram:
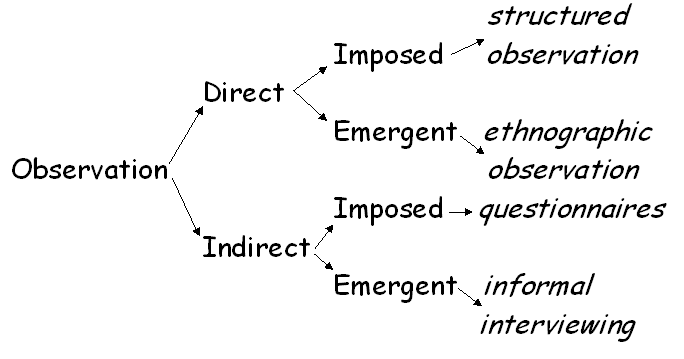
The list of methods is limited to fit the frame, but the idea is readily extendable, I think, to include more. For example, we can have:

extending the previous diagram, showing that, in addition to informal interviewing, we can allocate at least two other methods to that category - analysis of organizational documentation, and the analysis of almost any other text, including published (or personal) diaries, biographies, and so on.
This typology of methods does not provide the researcher with a ready-made answer to the question, "Which method should I use?" It simply offers a reasonably logical way of viewing the whole range of possible methods and making decisions about which method is appropriate in the circumstances. Those circumstances include the philosophical framework within which you wish to operate (positivist or interpretative), what you know about the research area to begin with, the nature of the research population, and so on.
The question of what we know already is really the main guide, since we can only impose structure when the field is well understood, or when we wish to test a well-developed theoretical framework. Consequently, allowing the structure to emerge through the process of analysis is desirable when the research is exploratory and aimed at theory development.
From selection of method, we eventually move to mode of analysis and here again, structure determines both what we have to analyse and what we can use in the analysis.
Imposing structure allows us to collect structured data, which, if not already in numeric form, can be converted to numbers (e.g., by coding Yes/No as 1/0). This allows us to use statistical analysis packages such as SPSS (Statistical Package for the Social Sciences; see for example, Kinnear & Gray, 1999).
Methods that rely upon emergent structure produce mainly text - although they can produce a mixture of text and characteristics that can be numerically coded. Text is more problematical to analyse, since statistical methods cannot be applied and you have to work with the text to identify theoretical concepts. It is then possible to use statistical techniques to determine whether the occurrence of concepts in relation to one another have some probability of being statistically associated, but the initial analysis demands either 'pencil and paper' methods of handling the text, or, better, using a qualitative analysis package such as Atlas.ti [A demonstration version of Atlast.ti can be found at the Web-site]
To conclude: while a typology of methods may not enable us, on its own, to determine the methods we ought to employ in an investigation, it may help us to determine the approach and to ask ourselves questions about the fundamental research position we are adopting.
Conclusion
The link between integrative levels and appropriate research methods in information science has been explored in this paper. We have shown that information is not a unitary concept, but takes different forms at different integrative levels and must be explored by methods appropriate to those levels. It is suggested that a social information science can be created, in which information is conceived as socially constructed and for which social research methods are appropriate. There is, however, confusion over those methods and an attempt has been made to resolve that confusion by proposing a typology based on the fundamental method of observation and the ways in which structure in data may be achieved. It is only by fundamental analysis at these kinds of levels that any firm basis for any model of information science can be evolved.
References
- Bottle, R.T. (1997) 'Information science', in: John Feather and Paul Sturges, editors. International encyclopedia of information and library science. London: Routledge.
- Brewer, D.D. (2000) Forgetting in the recall-based elicitation of personal and social networks. Social Networks, 22 (1) 29-43
- Debons, A., ed. (1974) Information science, search for identity: proceedings of the 1972 NATO Advanced Study Institute in Information Science held at Seven Springs, Champion, Pennsylvania, August 12-20, 1972. New York, NY: Marcel Dekker.
- Foskett, D.J. (1978). "The Theory of Integrative Levels and its Relevance to the Design of Information Systems." Aslib Proceedings 30, (6), 202-208.
- Froehlich, T.J. (1986) 'Challenges to curriculum development in information science'. Education for Information, 4 (4), 265-289
- Hughes, J. (1980) The philosophy of social research. London: Longman.
- Kinnear, P.R. & Gray, C.D. (1999) SPSS for Windows made simple. 3rd. ed. London: Taylor & Francis.
- Lancaster, F.W. (1994) 'The curriculum of information science in developed and developing countries'. Libri 44 (3): 201-205
- 'Levels of organization. Integrative levels', (n.d.) in: Union of International Associations, editor. Encyclopedia of World Problems and Human Potential. Brussels: Union of International Associations. (Available at: http://www.uia.org/uiademo/kon/c0841.htm. Accessed 11th July 2001)
- McGarry, K.J. (1987) 'Curriculum theory and library and information science'. Education for Information, 5 (2-3), 139-156
- Needham, J. (1937) Integrative levels: a revaluation of the idea of progress. Oxford: Clarendon Press.
- Spencer, H. (1862) First principles. London: Williams and Norgate, 1862 (A system of Synthetic Philosophy ; v. 1)
- Wilson, T.D. (1972) 'The work of the British Classification Research Group'. in Subject Retrieval in the Seventies, edited by Hans Wellisch and Thomas D. Wilson, Westport, CT: Greenwood Publishing Company. pp. 62-71.
This paper is to appear in Slovak, in Knižnicná a informacná veda (Library and Information Science), published by the Department of Library and Information Science, Comenius University, Bratislava, Slovak Republic. Updated 26th March 2002