Vol. 11 No. 2, January 2006
| Vol. 11 No. 2, January 2006 | ||||
Introduction. This paper extends a series on summaries of Web objects, in this case, the alt attribute of image files.
Method. Data were logged from 1894 pages from Yahoo!'s random page service and 4703 pages from the Google directory; an img tag was extracted randomly from each where present; its alt attribute, if any, was recorded; and the header for the corresponding image file was retrieved if possible.
Analysis.Associations were measured between image type and use of null alt values, image type and image file size, image file size and alt text length, and alt text length and number of images on the page.
Results. 16.6% and 17.3% of pages respectively showed no img elements. Of 1579 and 3888 img tags randomly selected from the remainder, 47.7% and 49.4% had alt texts, of which 26.3% and 27.5% were null. Of the 1316 and 3384 images for which headers could be retrieved, 71.2% and 74.2% were GIF, 28.1% and 20.5%, JPEG; and 0.8% and 0.8% PNG. GIF images were more commonly assigned null alt texts than JPEG images, and GIF files tended to be shorter than JPEG files. Weak positive correlations were observed between image file size and alt text length, except for JPEG files in the Yahoo! set. Alt texts for images from pages containing more images tended to be slightly shorter.
Conclusion. Possible explanations for the results include GIF files' being more suited to decorative images and the likelihood that many images on image-rich pages are content-poor.
This paper represents an extension to a series of research reports on how people and organizations summarize Web pages, especially how they summarize their own Web pages in descriptions and keywords in meta tags (Craven 2004a; Craven 2004b, Craven 2004c; and relevant items cited therein), though also to some extent how they summarize external Web pages (Craven 2002). What will be examined here is how people textually summarize images on their Web pages; specifically, their use of the alt attribute of the img tag.
In addition to the work of the author, a few other researchers have also investigated descriptions and keywords in meta tags: Turner and Brackbill (1998) have reported results of a small experiment that showed that addition of a description did not improve retrievability of Web pages on Infoseek and Altavista; similar results have been reported for the these two search engines and five others by Henshaw and Valauskas (2001); Drott (2002) has noted the extent to which description and keyword meta tags are used in the sites of sixty Fortune Global 500 companies. Alimohammadi (2004) has found that description and keyword meta tags are less common on Iranian Websites than elsewhere on the Web.
External descriptions of Web pages have also been examined by Wheatley and Armstrong (1997), and Amitay (2001) developed a tool called SnipIt to extract descriptive passages with URLs from Web pages and another tool called InCommonSense to select from among these the 'best' descriptive passage for each URL.
A widely used model for classifying image descriptions at the conceptual level is the Panofsky/Shatford model which involves twelve facets in a three-by-four matrix, one dimension of which is divided into 'generic', 'specific', and 'about' and the other into 'who', 'what', 'where', and 'when'. Hollink et al. (2004) found in an experiment that facets in the 'generic' set were most likely to be used in both queries and descriptions, though the frequency of specific terms was higher in queries than in descriptions.
The frequency distribution of image tags on Web pages has been examined by Ajiferuke and Wolfram (2005), who found that a generalized inverse Gaussian-Poisson (GIGP) model supplied the best overall fit, though the distributions within individual Websites were multi-modal; the same study also showed .com and .edu sites as having a significantly higher image count per page than .net and .org sites.
Kanungo et al. (2002), in a study of text in images (based on the query 'newspapers' on Google), found that 42% of sampled images contained text; 59% of images with text contained at least one word that did not appear in the HTML file; 36% of images with text contained only words also found in the HTML file; 5% of images with text contained 'non-English script' (not otherwise defined). Number of images per page varied from zero to more than 200, in a typical inverse exponential distribution.
There are various means by which a Web page creator can disseminate textual information about an image on a page, but by far the most commonly used standardized method is the alt attribute for the img tag, which has been present in HTML since version 2.0 (Berners-Lee 1995; Korpela 2005) and is considered to be required (Bersvendsen 2004, Clark 2003).
The intended function of the alt attribute is to provide a substitute for the image in cases where the image itself cannot be viewed. Such cases include viewing a page over a low-speed line or from an overloaded server without waiting for the images to download, with image display turned off to improve speed or because of security concerns, or in a text-only browser, such as Lynx; and listening to a page as rendered into speech by screen-scraping assistive software.
Providing 'a text equivalent for every non-text element' (for example, by means of the alt attribute) is a checkpoint in the W3C's Web Content Accessibility Guidelines (W3C 1999c). In a comparison of usability assessment tools, Brajnik (2002) found that A-Prompt, Bobby, Net-Mechanic, LinkBot, Dr HTML, Web SAT, and LIFT all checked for presence of the alt attribute, although MacroBot, MetaBot, Web Criteria, and Web Garage did not.
In spite of its apparent usefulness, the alt attribute is often not applied (Lopresti and Zhou 2000). Mukherjea et al. (1999) state that most authors do not use it.
According to the W3C (1999a), the alternate text should 'serve as content when the element cannot be rendered normally'; two things to avoid are irrelevant and meaningless alternate text;an example given of the former is the text 'red ball' applied to an image of a red ball that functions as a decoration.
The US Access Board (2004) specifies that the alt text 'states the purpose of the image' for a navigational image or 'explains the meaning of the image' for an image contributing to page content. It 'should, when possible, communicate the same information as its associated element.'
Slatin states, 'ALT text should do two things: (1) briefly identify the nontextual element to which it is attached, and (2) provide access to the functionality represented by that element.' Alt text need not be a complete substitute for the image, but should be 'succinct, descriptive, and accurate' (Slatin 2001: p. 78). Succinctness would include omission of redundant expressions such as 'picture of' and not using jokes or uninformative placeholders like 'short description of image' or 'loading image' (Clark 2003).
'There is no one right alt text for any particular image. It all depends upon the context and the purpose of the image' (WebAIM 2005). Thus, the same image might reasonably be given different alt attributes on different pages.
For an image rich in content, some say that the alternative text should be functionally equivalent. The author should 'think of the text and the image as alternative representations for content' (Flavell 2004); the alt text 'should be a textual alternative for the meaning of the image. It should convey the same thing as the image' (Hickson 2002).
Others allow it to be a description of the image. Korpela (2005) concedes that 'the meme of regarding alt as a description has become frustratingly common' and so allows it to be either an equivalent or a description. Idocs (2002) says that a description may be used if no substitute is possible. To distinguish the two kinds of alternate text, Korpela (2005) proposes enclosing the text in brackets when it is a description of, rather than a replacement for, the image.
In any case, 'The most appropriate alt text communicates the purpose of the graphic, not its appearance' (WebAIM 2005). McAlpine (2005) does recommend, however, including the size of the image file if this is particularly large; this information could be of assistance to users in deciding whether they wish to download the image or not.
If such an image is merely 'supplemental or interesting', Flavell (2004) recommends a 'text that summarises the major feature that you wanted to bring to the reader's attention', while if it is 'critical for understanding the page', it may be that no suitable text can be provided.
Sources also differ somewhat on questions of punctuation and spacing. According to the W3C (1999b), 'Authors should not declare attribute values with leading or trailing white space'; but Watchfire (2005) recommends including leading or trailing spaces to avoid alt texts' running together; and this is also one of McAlpine (2005)'s suggestions. Flavell (2004) notes how unpunctuated alt texts in adjacent images can result in 'howlers' such as 'Photo of a bull in the water canoeing', when viewed in certain text browsers. To avoid this conflict, Tobias (2004) recommends surrounding texts with square brackets, also a suggestion of McAlpine (2005) along with vertical bars.
Another area of difference is the use of alt attributes with values equal to the empty string. 'Some guides and checkers say that empty alt texts should not be used. However, empty alt texts are perfectly valid and correct when the appropriate textual alternative to an image is an empty string' (Korpela 2005). An empty alt text has been recommended for graphics included for spacing (U.S. Access Board 2004; Tobias 2004), purely decorative images (Korpela 2005; Idocs 2002; Bersvendsen 2004; Tobias 2004), mere illustrations, images in navigational links in which suitable text is already present (Korpela 2005), or 'graphics which do not convey content' (WebAIM 2005). For spacers, however, text consisting of a space has also been recommended (Korpela 2005). Contrary to the majority opinion, Letourneau and Freed (2000) suggest providing a description for a decorative or incidental image, such as 'Drawing of a house'.
For an image of text, equivalent, if not exactly identical, text has been recommended (Korpela 2005; Letourneau and Freed 2000). If the text is a logo, the word 'logo' may be added (Korpela 2005), or the text may just be the name of the entity represented (Flavell 2004; Idocs 2002; Tobias 2004). If the image is an initial capital, the substitute text should just be the capital letter (Tobias 2004).
For an image representing punctuation, such as a bullet, either the punctuation (Korpela 2005; Idocs 2002; Tobias 2004) or an equivalent expression such as 'item': should be employed (Korpela 2005), at least if not obtrusive (Flavell 2004), or even just a space (Flavell 2004) or an empty string (WatchFire 2005). For an image of a symbol, the name of the symbol should be used (Korpela 2005). Korpela (2005) and Idocs (2002) deprecate the use of ASCII art, such as '==>' for an arrow, although using a row of hyphens for a horizontal rule seems to be acceptable (Tobias 2004).
Korpela (2005) also states that alt texts should be in normal prose and should be suitable for speech synthesis and hence avoid abbreviations.
For a navigational image, a suitable word should be included, with punctuation (Korpela 2005); the word may correspond to the destination of the link (Korpela 2005; Letourneau and Freed 2000) or briefly describe it (Flavell 2004), or identify its function (Letourneau and Freed 2000).
Since the alt text is intended to be read with the main text, it should generally flow well with it ( Tobias2004). More specifically, it should not duplicate the main text (WebAIM 2005; WatchFire 2005; Tobias 2004; McAlpine 2005). Clark (2003) also deprecates text that repeats the filename of the image.
'There is no set limit on the length of an alt text, but... a very long alt may not be fully displayed when image-loading is turned off or when the browser cannot locate the image file. By convention, limit alt texts to 1,024 characters (1 K) or less' (Clark 2002). Korpela (2005) advises that an alt text should be no more than 50 characters. Slatin (2001) points out that the JAWS screen reader causes problems with alt text that exceeds 150 characters.
Korpela (2005) suggests that the alt text be written first, before the image is selected. More generally, Slatin (2001) advocates composing the entire page first as a text, including image alt values, and only then adding the images, forcing the arrangement of the images to follow the logical text order.
Unlike images specified with the img tag, background images are specified in attributes of other tags (chiefly body, and sometimes table) and so cannot themselves have attributes, including alt. For this reason, WebAIM (2005) says, 'Do not put important images in the background'.
Apart from accessibility, the alt attribute can be used to improve retrievability of a site on search engines (Winters 2005) (Kovacs 2003). Abuse, however, has caused many search engines to ignore the alt text (Wall 2004). Tobias (2004) advises against 'spamdexing' in alt attributes, as does McAlpine (2005).
Common graphical browsers now treat alt texts as text for hint boxes ('tool tips'), even though it is the title attribute that is intended for this purpose (Flavell 2004; Korpela 2005; Bersvendsen 2004; Tobias 2004). Consequently, many page authors, writing to the browsers rather than to the standards, may construct alt texts with the intention of having them appear as hints.
If it is absent, text browsers typically display the filename or a placeholder text such as '[Image]' (Bersvendsen 2004, Clark 2003, McAlpine 2005), which is probably undesirable. To avoid this problem, a null value ('') may be assigned to the attribute.
The alt attribute has been used in numerous research studies of Web image retrieval. It is given the highest weight in the system of La Cascia et al. (1998). It has the second-highest weight, after the 'link string' (the visible text in any a element) in the system described by Lu et al. (2000). Mukherjea et al. (1999) consider query terms that occur in alt texts and image names to be 'very relevant' in ranking images in retrieval. Lu et al. (2001) assign equal weight for retrieval to alt text and to anchor text and image URL, with half that weight being assigned to other textual cues (metadata, title, heading, and other terms).
Other systems that have made use of the alt attribute in combination with other features include those of Shen et al. (2000), Chen et al. (2001), Jayaratne et al. (2003; 2004) and Smith and Chang (1997).
Some retrieval studies report using other properties of images, such as title (Shen et al. 2000) and 'caption' (Yang and Lee 2003) or 'image caption' ( Shen et al. 2000; Jayaratne et al. 2003; 2004). (HTML tables may have captions, and images in word processors may have captions, but not images in HTML).
Not all alt attributes are equally useful and not all images are equally worth retrieving. Examples of bad alt text given by Pilgrim (2002) are any containing HTML tags, filenames, 'alt text', 'Click here', or 'turn images on'. Some studies have accordingly applied filtering techniques to reduce noise.
Paek and Smith (2003) used occurrences of certain keywords ('bullet', 'button', 'rule', 'line') to categorize images automatically as 'decorative', and of body text words to categorize image labels as 'body text'. Other label-based categories were 'advertisement', 'informational', 'logo', and 'navigation'. Combined with image type (GIF/JPEG), number of images on page, and visual properties (including height and width, number of colours, and various saturation properties), a decision tree was developed that would automatically class images as content or non-content with an overall accuracy of 84% when tested on four sites.
Alt texts are sometimes missing, even from significant images, which Chen et al. (2001) attribute to the fact that 'many editors are too lazy'. Yang and Lee (2003) consider that images without alt texts may be rejected as less important.
Among text clues in an image retrieval study by Munson and Tsymbolenko (2001), only the image filename, the title element of the HTML document, and the alt text had significant recall. There was a high level of precision for the alt text; but the recall, though significant, was relatively low, unsurprisingly, in view of previous research showing that more than half of alt values were empty or wrong.
The present study aimed, among other things, to test the following hypotheses about author behaviour in assigning, or not assigning, alt texts to Web page images.
An existing personal software package used for data capture in earlier studies in the present series was modified to allow capture, from individual Web pages, of the following data related to a random image on each page: the image URL; the number of images on the page; the alt attribute value for the image, if any; and the Content Type and Content Length of the image file, if its header could be retrieved from the host.
The package was used to attempt to log data from 2048 pages retrieved in June of 2004 from Yahoo!'s random page service and 6356 retrieved in May and June of 2002 from the higher levels of Google's directory The package automatically rejected invalid links, including non-responding servers, server errors, and files that did not appear to be HTML. Data were logged for the remaining pages.
Data were logged from 1894 pages from the Yahoo! set and 4703 pages from the Google set (92.5% and 74.0% respectively).
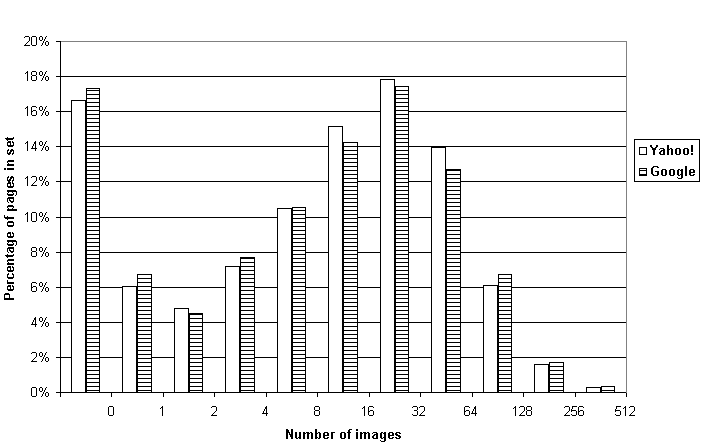
Number of images on a page varied from 0 to 373 for the Yahoo! set and from 0 to 914 for the Google set, with means of 22.1 and 22.9 and medians of 11 and 10; in the Yahoo! set, 16.6% (315) had no images; 6.0% (114), one image; and 4.8% (91), two; in the Google set, 17.3% (815), no images; 6.7% (317), one image; and 4.5% (211), two (Figure 1).
Of all 1579 image files selected in the Yahoo! set, 47.7% (737) had alt texts; of the 3888 image files from the Google set, 49.4% (1919) had alt texts. Length of alt texts varied from 0 to 255 characters and from 0 to 614 characters respectively, with means of 15.8 and 16.5 and medians of 11 and 10; 26.3% (194) and 27.5% (528) of alt texts were null; 4.1% (30) and 4.3% (82) consisted of a single character; and 0.5% (4) and 0.7% (13), of two characters.
The most common alt texts, apart from "", were as follows.
| Text | Yahoo! frequency | Google frequency | Mean proportion |
|---|---|---|---|
| 1 | 14 | 25 | 1.6% |
| setstats | 5 | 20 | 0.9% |
| pad | 8 | 7 | 0.7% |
| home | 4 | 13 | 0.6% |
| * | 3 | 14 | 0.6% |
| 3 | 13 | 0.6% |
Common keywords and phrases in alt text were as follows.
| Word or phrase | Yahoo! frequency | Google frequency |
|---|---|---|
| bytes | 17 | 49 |
| click | 9 | 35 |
| com | 22 | 51 |
| enter | 12 | 12 |
| gif | 14 | 37 |
| home | 20 | 42 |
| jpg | 11 | 21 |
| logo | 15 | 39 |
| online | 6 | 21 |
| page | 11 | 28 |
| search | 10 | 24 |
| site | 10 | 21 |
| web | 9 | 26 |
Of these, 'jpg' and 'gif' are file extensions, and 'com' is a top level domain.
Only two texts were observed that used non-Western-European characters, one in the Yahoo! set, where the page coding was Cyrillic (Windows-1251), and the other in the Google set, where the page coding was Central European (ISO-8859-2).
The most common filenames were as follows.
| Filename | Yahoo! frequency | Google frequency |
|---|---|---|
| arrow.gif | 5 | 9 |
| blank.gif | 10 | 33 |
| clear.gif | 5 | 36 |
| clearpixel gif | 5 | 17 |
| dot.gif | 6 | 17 |
| logo.jpg | 6 | 9 |
| logo.gif | 16 | 33 |
| pixel.gif | 9 | 35 |
| s.gif | 6 | 16 |
| serv | 14 | 25 |
| shim.gif | 7 | 29 |
| space.gif | 5 | 20 |
| spacer.gif | 109 | 208 |
| trans.gif | 7 | 10 |
| trans_1x1.gif | 8 | 7 |
| transparent.gif | 9 | 12 |
| visit.gif | 6 | 20 |
Of these, spacer.gif was most usually, where available, a 43-byte GIF file, but there were variants of different sizes, in one case in the Yahoo! set a text file of 14,309 bytes and in one in the Google set a text file of 25,056 bytes; clear.gif and shim.gif were similar; where available, clearpixel.gif was almost always a 43 byte file (two exceptions of 807 bytes in the Google set), as was space.gif (four exceptions of various sizes in the Google set); the logo files all appeared to be different (with the exception of one image where two pages on the same site happened to be selected), as did arrow.gif; the picture was mixed for blank.gif, trans.gif, pixel.gif, and transparent.gif; trans_1x1.gif, at 43 bytes, was a 1x1 Web bug and always occurred in http://us.st1.yimg.com/store1.yimg.com/Img/; finally, serv was always at http://geo.yahoo.com/serv, was also a 1x1 Web bug, and accounted for all instances of the alt text '1' in both sets.
Of all the 114 URLs containing the string 'logo' in the Yahoo! set, only two had texts that included 'logo' as a word, and another three had texts that included the filename; of the 280 'logo' URLs in the Google set, twenty-two had texts that included the word 'logo' and another three had texts that included the filename.
Image content types broke down into 71.2% and 74.2% image/gif, 28.1% and 20.5%, image/jpeg, 0.8% and 0.8% image/png, and the rest other (basically 'text/html', which is, of course, not really an image format, as is discussed further below).
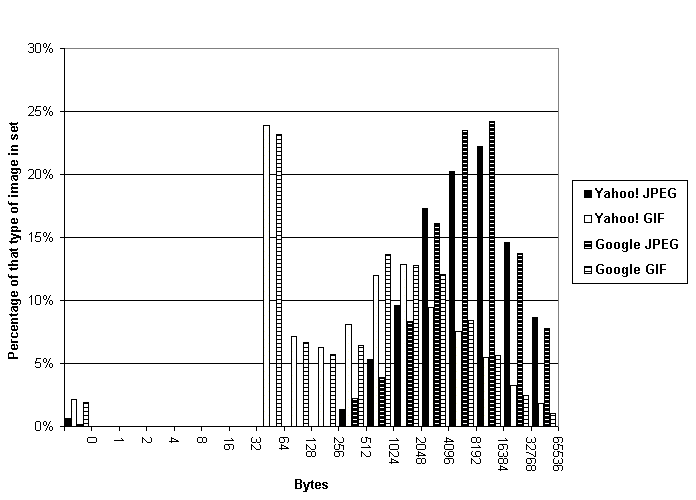
For GIF images, sizes varied from 0 to 405,252 bytes for the Yahoo! set and from 0 to 404,222 bytes for the Google set, with means of 5191.7 and 3565.1 and medians of 654 and 807; there was a concentration near the bottom of the range at 43 bytes (137 images in the Yahoo! set and 353 in the Google set). For JPEG images, sizes varied from 0 to 295,646 bytes and from 0 to 297,798 bytes, with means of 16,858.9 and 15,493.2 and medians of 7446 and 7742. Plots of the distributions of image sizes for the two file types clearly show GIF images tending to be smaller and JPEG images larger (Figure 2).
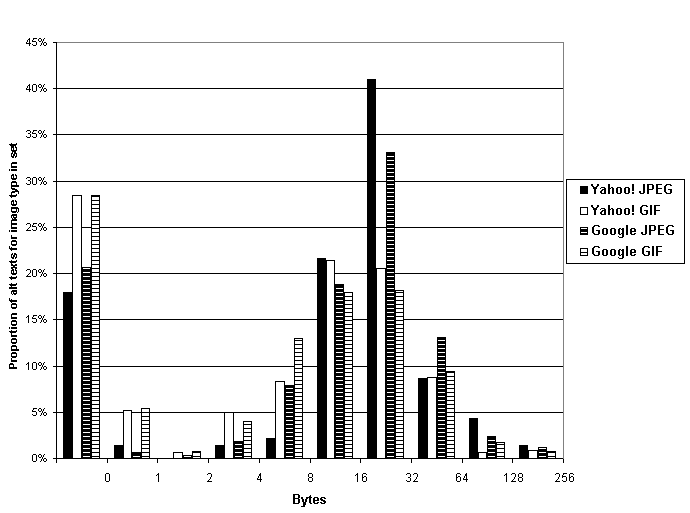
Alt text was present for 47.3% (=443/997) of GIF files versus 43.8% (=139/317) of JPEG files in the Yahoo! set, and for 50.1% (=1259/2511) of GIF files versus 47.3% (=329/695) of JPEG files for the Google set; the differences in proportion were not statistically significant (chi-squared p=0.2898 and 0.1912). Length of alt text, where present, varied for GIF images from 0 to 255 for the Yahoo! set and from 0 to 614 characters for the Google set; for JPEG images, it varied from 0 to 165 for the Yahoo! set and from 0 to 183 for the Google set (Figure 3).
Null values were found for 28.4% (=126/443) of GIF file alt texts versus 18.0% (=25/139) of JPEG texts in the Yahoo! set and for 28.4% (=358/1259) of GIF file alt texts and 20.7% (=68/329) of JPEG texts in the Google set; the differences in proportions between the two file types were statistically significant in both sets (chi-squared p=0.0141 for the Yahoo! set and 0.0046 for the Google set).
Correlation between length of alt text and image file size was slightly positive for GIF files in both sets (0.1200 and 0.1024); there was virtually no correlation for JPEG files in the Yahoo! set (-0.0229) and a weak positive correlation in the Google set (0.0720).
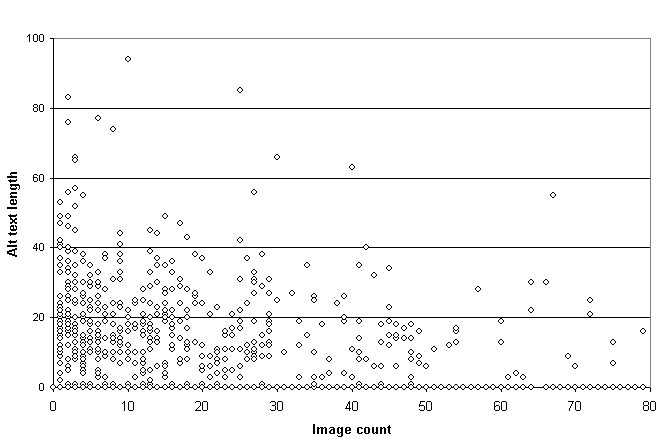
Correlations between image count and length of alt text were slightly negative (-0.1120 and -0.1056) and were statistically significant (t=-3.0544, df=735, p < 0.01; t=-4.6545, df=1922, p < 0.01). as can be seen from Figure 4, the relationship was not linear, but rather involved an almost complete exclusion of cases where both image count and alt text length were high, while allowing many instances of simultaneous low image count and low text length. correlations between image count and image size were very slightly negative (-0.0917 and -0.0823) and were also statistically significant (t=-4.0059, df=1892, p < 0.001; t=-5.6583, df=1892, p < 0.01).
The difference in proportion of valid pages between the two sets was likely mostly a result of time, the Google set having originated two years before the Yahoo! set and neither having been updated in the intervening period.
The mean and median number of images per page were slightly lower than those observed by Ajiferuke and Wolfram (2005), which ranged from 25.4 to 36.4 and from 14.0 to 23.0 respectively, depending on top-level domain; a likely explanation is that the present study did not restrict itself explicitly to top-level (home) pages and that lower-level pages tend to have somewhat fewer images.
The results of this study showed a slightly higher proportion of pages using alt texts than reported by Kanungo et al. (2002), although it was still marginally true, in accordance with the observation of Mukherjea et al. (1999), that most images sampled did not have them.
The rarity of non-Western-language characters in the alt texts, at least in comparison with the current experience of the Web, has a fairly obvious cause. Both sets were likely strongly biased in favour of English-language materials: the Google set, certainly, was derived from an English-language version of the directory, which appears to list almost exclusively pages in English.
The relative frequency of image formats in this study is quite different from that reported by Security Space (2005) of 62.7% GIF, 53.3% JPEG, and 6.2% PNG. This is no doubt largely because Security Space is measuring something different, as is obvious from the fact that its percentages do not add up to 100%: not the proportion of images in a particular format, but the proportion of sites that contain any images in the given format. Most of the images on a page might be small, decorative GIF images, for example, but the same page might contain one large photographic JPEG or PNG image.
The 43-byte size commonly observed for the Web bugs is not actually the minimum possible for a GIF file; for example, both Adobe Photoshop and, with the right settings, GIMP, readily create GIF files of only 35 bytes. Truly minimal GIF files, however, would not be transparent, and thus might be visible to alert readers.
Data on the images may be flawed in some cases because of defects in the header information returned by the servers. The few images reported as having zero size may actually just not have had their sizes specified in the HTTP header; the Content-Length header line is not actually required in HTTP. Misidentification of the Content-Type is also not unheard of, even for commonly used content types. For example, a HEAD request on the URL http://www.fortunecity.com/westwood/karan/21/lairline.gif returned a header that both omitted Content-Length and misidentified a JPEG file as a GIF file (likely because of its having the wrong extension). The relatively few file headers with Content-Type text/html or text/plain are partly simply errors of the kind just mentioned and partly error pages returned by the servers when the image files cannot be found in response to unreferred requests.
In spite of these problems, looking at Content-Length rather than image dimensions served several purposes in comparison to the alternative of taking the product of the image dimensions as the measure of the image's size. Dimensions specified in the HTML code could have been used where available, but, if this were not the case, it would have been necessary to download and analyse the image file itself. Relying on a mixture of the two methods would have been methodologically untidy, while adopting the second alone would have taken still longer. It should also be considered that the dimensions of an image may also be a relatively poor measure of its information content from a theoretical point of view: an image of relatively small dimensions may contain much more detail than another image of greater dimensions. Moreover, a GIF image may be animated, introducing a third dimension that is somewhat difficult to make commensurable with the other two. GIF and JPEG images are both compressed, and compression generally reduces simple images more than complex ones. Thus, file size seems to be a better measure of image size.
This study confirmed most of the hypothesized relationships, at least to some extent. GIF images were indeed more commonly assigned null alt texts than JPEG images. GIF files also clearly tended to be shorter than JPEG files. A weak positive correlation was observed between image file size and alt text length for GIF files; contrary what had been hypothesized, however, such a correlation was not found for JPEG files in the Yahoo! set. Alt texts for images from pages containing more images did tend to be shorter, but only weakly.
The explanations suggested for the observed relationships doubtless have some strength; but it is also clear from the weaknesses of the correlations observed, and especially from the partial failure of the hypothesis relating length of text to size of image file in the case of JPEG, that there are also other factors at work affecting how Web page creators describe the images on their pages.
Thus, the main implication of the present study is not so much in its having proved any surprising new findings as in, first, confirming some general ideas certain aspects of Web authoring behaviour and, second, in suggesting some future areas for more intensive research.
As one example of more specific research directions, the author has also undertaking a more detailed study of references to image files with commonly used names, such as arrow, and with names equal to letters of the alphabet and what kinds of alt values these are assigned. Other areas of investigation might include determining the frequency with which JPEG files are compressed at other than the common ratios provided for in simple software packages like Paint and, if different compressions ratios are found, whether these correlate in any way with use of alt texts.
| Find other papers on this subject. |
|||
© the author, 2006. Last updated: 21 December, 2005 |
|
