vol. 14 no. 3, September, 2009
vol. 14 no. 3, September, 2009 | ||||
Tags, users' own descriptions of images, are becoming widely used as participation on the Web increases. The potential of user-generated descriptors was offered by O'Connor (1996) more than a decade ago. He asserted that 'by changing our model of where the act of representation takes place', (p. 150) images can be represented with user-generated tags as well as adjective and functional tags which are difficult for a single indexer to represent. The advent of Web 2.0 technology made this approach possible in the real world, and Flickr became a popular image tagging system in America. Accordingly, a great deal of practical approaches and research endeavors have focused on tag utilization in user-centered indexing mechanisms (see the Related studies section). Compared to document-centred indexing, user-centred indexing is more interested in users' needs and focuses on incorporating possible user queries into the indexing terms (Fidel 1994; Soergel 1985). Therefore, in order to evaluate the actual effectiveness of tag utilization as a user-centred indexing mechanism, user-generated tags need to be reflected in search query terms, i.e., representations of user needs.
However, comparative analyses between image tags and search queries have not been adequately investigated. Studies on image search queries have mainly compared them to the general search queries on the Web. These comparisons between image search queries and general search queries reveal quantitative differences in the amount of image search queries and the distribution of query terms (Jansen et al. 2000; Goodrum and Spink 2001). Jansen et al. (2000) reported that image search queries formed a small portion (less than 3%) of overall users' queries on the Web. Goodrum and Spink (2001) found that image search queries contained a larger number of terms and terms that were more diverse compared to general search queries. On the other hand, research on image tags primarily focuses on the potential of tags for developing user-centred image indexing systems (i.e., folksonomies).
As a way of employing tags as a user-centred organization tool, researchers have attempted to identify patterns and features of social tags (Golder and Huberman 2006; Morrison 2008; Stvilia and Jogensen 2007) or to develop controlled vocabulary systems using computational algorithms (Schmitz 2006; Aurnhammer et al. 2006). These research efforts are based on the underlying assumption that utilizing user-supplied tags for images has benefits when building user-centred indexing systems. Since end-users directly supply the tags when describing images, it seems reasonable to assume that tags employed in user-centred indexing systems represent users' needs and perceptions of images. However, to determine this representation, it is necessary to investigate to what extent user-supplied tags are similar or different from search queries. This study is designed to fill this gap, because there is little empirical research evaluating user-supplied tags in terms of search queries for images.
This study aims to explore the characteristics and features of user-supplied tags for non-domain-specific images compared to search queries on the Web. More specifically, this study focuses on comparisons between tags and search queries using Shatfords (1986) categorization schemes and the level of specificity based on the basic level theory. These two methods have been adopted as tools in related studies (Armitage and Enser 1997; Choi and Rasmussen 2003; Jogensen 2003; Rorrisa 2008) because they provide a clear understanding of an image's semantic content. Using a categorization scheme makes it possible to examine dominant categories used in image representation (describing or searching) processes. An image contains multilayered meanings, so it is important to elucidate dominant categories (or attributes) in an image (Choi and Rasmussen 2003). In addition, an object can be articulated differently depending on term specificity (e.g., the same object can be described as 'animal', 'dog', or 'Chihuahua'). Similar to dominant meanings in images, if it is possible to find any specific level of terms, those specific levels of terms should be the main focus of the indexing process (Bates 1998). Following two methods, Shatford's categorization and specificity level, the characteristics and features of image tags are elucidated through comparison to search queries. In this context, the goals of this study are as follows:
This section introduces lines of studies on examining image search queries and user-supplied tags on images. Their fundamental purposes were to understand users' needs, perceptions of image searching behaviour, so that the findings could provide evidences on implementing more effective image retrieval systems.
Studies of image query analysis mainly consist of two areas: studies on image search queries which have been submitted to traditional visual/image collections in libraries and museums, and studies on image search queries in Web search engines.
Studies on image search queries generally attempted to identify the users' needs by analysing the users' queries submitted to visual information archives in libraries and museums. Armitage and Enser (1997) analysed 1,749 queries submitted to visual information archives of seven libraries for image retrieval by categorizing users' requests based on Shatford's categorical analysis. The results of this study identified observable similarities in image query categorization across multiple libraries. The majority of users' queries of visual information archives from seven libraries were categorized as Specific, and the remaining queries were categorized as Generic or Abstract (the latter containing the fewest queries). More specifically, Hastings (1995) analysed queries of art historians for digitized Caribbean paintings. The analysis identified four levels of complexity from least complex to most complex. The least complex type of queries included questions such as Who?, Where?, and When?; while the most complex type of queries included Meaning, Subject, and Why?. The intermediate level of queries included How?, Identity of Object, and Activities as well as What are? questions. The results of this categorical analysis were applied to retrieval parameters for image and image characteristics.
Another query analysis on a specific image collection was conducted by Choi and Rasmussen (2003). Based on Batley's (1988) four categories, they identified image search needs by analysing thirty-eight search requests from the Library of Congress American Memory photo archive. The results demonstrated that more than half of search queries were categorized general/namable needs (60.5%), then specific needs (26.3%), general/abstract needs (7.9%), and general or subjective needs (5.3%). They also analysed 185 search terms using Shatford's category, and demonstrated that 64.87% of search terms were included in the generic category and 26.49% and 8.64% were in the specific and abstract categories, respectively.
Given the characteristics of general searching behaviour in the context of the Web, there are several studies focusing on image search queries conducted on the Web. Jansen, Goodrum and Spink (2000) identified image, audio, and video search queries from 1,025,908 search queries and 211,058 sessions on a major Web search engine. They identified 27,144 image queries representing 2.65% of all search queries. In terms of search query characteristics, they demonstrated that users applied more search terms (3.27 terms for images) when searching multimedia compared to general Web searches (2 terms for general searches). In addition, Goodrum and Spink (2001) examined users' Web image queries to understand visual information needs in terms of the number of image queries, terms, and sessions. The average number of image queries per user was 3.36 while the average number of general queries was 2. The categories were identified as diverse including image terms, modifiers, sexual terms, cost, sex, other, people, and art and leisure. From another perspective, Goodrum et al. (2003) identified search query reformulation patterns by using Markov analysis of state transitions with seventy-one image search queries on the Web. Eighteen state categories were identified as search tool, collection selection, queries, context moves, or relevance judgments.
Recently, social tagging has received attention in the library and information science field as a promising information organization mechanism. Based on the idea that users not only organize information for their own use but also share their organized collections with others, researchers in the field expect that user-supplied tags can serve as a user-oriented indexing approach. A social tagging system has promising advantages: for example, information loss, which inevitably occurs during the information representation process, can be overcome, or at least decreased, through social tags. This is because for most of the social tagging systems, the information loss is from people having different viewpoints and is not from a single indexer's perspective (Shirky, n.d.). In addition, since users engaged with social tagging systems describe content with their own vocabulary, tagging systems can reveal the conceptual structure and current terminologies of the user community (Furnas et al. 2006).
The potential of social tagging seems more beneficial for image indexing and retrieval. First, information loss has been identified as one of main obstacles in representing image documents. In other words, as an image document conveys multiple levels of meaning, including subjective impression, it has been argued that a single indexer cannot provide all possible index terms for an image document. However, user-supplied tags, even infrequently used tags, can be utilized in expanding indexing terms by reflecting a diversity of users' viewpoints (Jogensen 2007). Secondly, it has been recognized that there are discrepancies between professional indexers' and naive users' perspectives in interpreting and representing image documents. As Bates (1998) noted, although professional indexers assign index terms to assist users, their professional knowledge often leads to mismatches between index terms and search terms. By using user-supplied tags, it will be possible to reflect index terms that are familiar to end-users. Thirdly, browsing has been addressed as a significant activity during the image retrieval process, because verbal queries have limitations in expressing visual needs. Therefore, social tagging systems, which can assist users' browsing activities, will be a beneficial feature for an image retrieval system. Finally, there is another unique feature of image documents that can take advantage of a social tagging system. An image includes multi-layered messages that belong to different attributes (or categories). Therefore, as noted above, a prominent research area has been the discovery of which attributes of pictorial messages are significant in retrieving image documents. By analysing user-supplied tags, it is possible to discover which attributes are frequently adopted by users for organizing images for their own and others' use.
Since a social tagging system demonstrates its potential for providing access to image documents, several researchers, mostly in information science, have examined and utilized user-supplied tags. A series of studies has investigated how users use Flickr, a photo management and sharing site, which employs social tagging. On the Flickr site, which was launched in 2004, users may upload their photographs with tags. Susequently, photographs may be viewed and searched by the public. Compared to other social tagging Websites, where users assign tags for digital resources created by others, Flickr users assign tags for their own photographs. Guy and Tonkin's (2006) study attempted to investigate how to make tags more effective as access points, based on the finding that there is a convergence of tags as time goes on. They focused on 'sloppy tags' from delicious (the social bookmarking site) and Flickr and proposed methods for improving tags by handling these sloppy tags. However, they also pointed out that these tidying up processes may discourage users' participation.
Marlow et al. (2006) analysed Flickr tag usage patterns to propose a tagging system based on their findings. According to their results, most users have only a few unique tags, and the growth of unique tags adopted by an individual user declines over time. They also found correlations between contact networks among Flickr users and the formation of tag vocabulary (i.e., degree of common tag usage). Stvilia and Jogensen (2007) investigated the collection building behaviour of Flickr users by comparing descriptions given to two different types of photo sets (i.e., user-selected thematic collections), individual users' photo sets and groups' photo sets. They found that, whereas descriptions of individual users' photosets were focused on the users' contexts and events, descriptions of group photosets include more general concepts and the scope of the group.
A few studies have compared tags and the traditional indexing approach. Matusiak (2006) compared tags and professionally-created metadata using two sets of images, one from the Flickr site and the other from a digital image collection. She concluded that tags cannot be used as an alternative to professional indexing because of their inconsistency and inaccuracy. Instead, they may be used as an enhancement or a supplement to indexing. Winget (2006) focused on authority and control issues, and asserted a positive potential for tags with digital resources. According to Winget, users choose appropriate, thorough and authoritative terms, and there are informal policies which enforce appropriate tagging behaviour among users.
Researchers in computer science have developed algorithmic models connecting tags with existing indexing mechanisms. Schmitz (2006) proposed a model which induced ontology from the Flickr tag vocabulary, and discussed how the model can improve retrieval effectiveness by integrating it into a tagging community. Aurnhammer et al. (2006) proposed combining tagging and visual features, and demonstrated that their model can overcome problems that may occur by only using one of two approaches.
The potential of social tagging has been explored in the museum community as a mechanism to bridge the gap between professional cataloguers and naive viewers. Although subject indexing is a significant access point for viewers, most cataloguing standards for museum collections do not require subject descriptions as a core element. Even if professionals assign subject index terms, findings reveal they cannot easily represent naive users' viewpoints (Bearman and Trant 2005). Considering that tags can represent museum objects with the users' language as well as provide diverse views from many individual contributions, several museums, such as the Metropolitan Museum of Art, the Guggenheim Museum, and the Cleveland Museum of Art, have implemented projects integrating tags in museum collections. According to a study comparing terms assigned by professional cataloguers and by volunteer taggers at the Metropolitan Museum of Art, 88% of tags were not included in existing cataloguing records. Of these, 75% were evaluated as appropriate terms by the museum's Subject Cataloguing Committee. This study showed that tags can increase the number of user-friendly access points (Trant 2006).
This study used two data sets for comparison: a set of search terms and a set of user-supplied tags. For search terms, the Web search log of Excite 2001 was used. The Web search log of Excite 2001, which has been used frequently in several Web query studies (Spink et al. 2002; Eastman and Jansen 2003; Jansen and Spink 2005), contains 262,025 sessions and 1,025,910 queries (Spink et al. 2002). Since the search engine Excite did not provide an explicit means to specify users' queries as image search queries, users had to supply specific terms to denote image search queries (e.g. apple image rather than simply apple). Accordingly, for the first phase of query processing, the image queries needed to be selected using the specific terms which were identified in Jansen et al. (2000) (Table 1). Out of the total of 1,025,910 queries, 32,664 image queries remained.
| art, bitmap,bmp, .bitmap, .bmp, camera, cartoon, gallery, gif, .gif, image, images, jpeg, jpg, pcx, .jpeg, .jpg, .pcx, photo, photographs, photograph, photos, pic, pics, .pic, pics, picture, pictures, png, .png, tif, tiff, .tif, .tiff |
For the second phase, each of 32,664 queries was reviewed to eliminate the following queries from the data set:
After the de-selection process, a total of 8,444 queries and 5,688 sessions remained. For the third phase, three subsets of queries, initial query, second revised query and third revised query, were extracted for two reasons. First, some sessions include a large number of queries; for example one session has thirty queries. If the queries are analysed as a whole, highly repeated query terms in one session may cause biased results (e.g., a query term occurring thirty times in one session should be distinguished from a query term occurring thirty times in thirty different sessions). To eliminate high-frequency queries generated by a single searcher, queries were analysed by search stages. Secondly, by analysing queries based on the search stages, it is possible to determine whether there are any differences in features of search queries during the progress of the search. Finally, since the tagging system used in this study allows only individual words as tags, search queries were also parsed into one-word search terms, except for people's names. Then, to exclude highly subjective search terms, only terms that appear more than three times were used for comparing user-supplied tags (see Table 2).
| Query | Number of queries | Number of unique terms occurring more than three times |
|---|---|---|
| Initial query | 5,688 | 629 |
| 2nd revised query | 1,478 | 135 |
| 3rd revised query | 598 | 60 |
A data set, consisting of user-supplied tags, was collected from Flickr. Using the API provided by the Flickr Website, 33,742 tags assigned to 8,998 photographs were collected - half of the photographs were uploaded in September and October of 2004 and the other half were uploaded in May 2007. A possible limitation of this study is the time difference between the Flickr data set and the Excite search query. However, an analysis demonstrated no differences between tags generated in 2004 and in 2007 in terms of categorization distribution and specificity levels. Therefore, based on this result, it is assumed that the time difference between the two data sets does not significantly influence the current study results. Since tags provided by a single user can be too subjective, 535 unique tags provided by more than two users were identified as the data set.
We adopted and revised a classification scheme developed by Shatford (1986) (see Table 3) to compare category distributions of terms used in tags and queries. Shatford proposed categorizing image subjects as Generic of, Specific of and About, based on Panofsky's theory which describes three levels of pictorial meanings. She then developed a faceted classification scheme by applying Who, What, When and Where facets to those three categories. Shatford's faceted classification scheme has been used in examining the categories of meanings included in an image and which categories are dominant during a search for images (Choi and Rasmussen 2003; Armitage and Enser 1997). This study investigates whether there are differences in category distributions between user-supplied tags and search terms.
| Shatford's faceted classification | Revised category | Example | |
|---|---|---|---|
| Abstract (A) | Abstract object (A1) | Mythical or fictitious being (A1) | Dragon |
| Emotion/Abstraction (A2) | Symbolic value (A2-1) | Classic | |
| General feeling, atmosphere (A2-2) | Cold | ||
| Individual affection, emotional cue (A2-3) | Happy | ||
| Abstract location (A3) | Place symbolized (A3) | Urban | |
| Abstract time (A4) | Emotion, abstraction symbolized by time (A4) | - | |
| Generic (G) | Generic object (G1) | Kind of person, people, parts of a person (G1-1) | Baby |
| Kind of animal, parts of an animal (G1-2) | Bear | ||
| Kind of thing (G1-3) | Airplane | ||
| Generic event/activity (G2) | Kind of event (G2-1) | Birthday | |
| Kind of action (G2-2) | Bowling | ||
| Generic location (G3) | Kind of place (G3) | Beach | |
| Generic time (G4) | Cyclical time, time of day (G4) | Morning | |
| Specific (S) | Specific object (S1) | Individually named person (S1-1) | Chris |
| Individually named animal (S1-2) | Heron | ||
| Individually named thing (S1-3) | Sega | ||
| Specific event/activity (S2) | Individually named event (S2-1) | Olympic | |
| Individually named action (S2-2) | - | ||
| Specific location (S3) | Individually named geographic location (S3) | Florida | |
| Specific time (S4) | Linear time (date or period) (S4) | 2007 | |
| [Others] | Colour (C) | Black | |
| Boolean + search command (B) | AND, Find | ||
| Image related (I) | Photo etc. | ||
| Flickr related (F) | Geotag | ||
| Number (N) | 1 | ||
| Part of speech (P) | And | ||
For comparing the level of term specificity, the basic level theory was adopted. The basic theory explains that concepts can be categorized into one of three levels, the superordinate level, the basic level or the subordinate level. Experimental studies have demonstrated most people tend to use the basic level concept rather than the superordinate or subordinate concept (Rosch et al. 1976). Since it has been found that a set of basic level terms are dominantly used and commonly shared by general users, researchers in library and information science assumed that basic level terms should be the level of specificity for concepts, and should receive focus during the indexing process (Bates 1998; Green 2006). By following this assumption, this study examined the level of specificity of user-supplied tags and search terms by applying the basic level theory. Since most research on basic level theory has explored concrete objects and colours, this study also analysed tags and search terms in the Generic and Colour categories.
Rosch and her colleagues demonstrated features of superordinate, basic and subordinate categories through their empirical studies (Rosch et al. 1976), but they did not provide established criteria which can clearly distinguish those three categories; whereas, in information scince, some recent studies developed their coding schemes for applying the basic level theory (Green 2006; Rorissa 2008; Rorissa and Iyer 2008). This study attempted to establish a coding scheme which reflects an existing hierarchical structure among concepts in addition to considering features of three categories illustrated by previous studies.
This study made use of the hierarchies appearing in the Library of Congress Thesaurus for Graphic Materials (hereafter, 'the Thesaurus') by following three steps. First, it examined how nine taxonomies used in the empirical study of Rosch et al. (1976) are designated in the the Thesaurus hierarchy (Figure 1). We found that the absolute level of depth appearing in the Thesaurus hierarchy cannot be directly used in deciding three categories. For example, in the case of an Object → Food → Fruit → Apple hierarchy, the lowest-level word, Apple, obviously satisfies features of the basic level, the upper three concepts belong to the superordinate level and this hierarchy does not include a subordinate level. The examples of Hammer, Saws and Crosscut saws shows that two basic-level terms, Hammer and Saws, belong to two different levels in the Thesaurus and a subordinate term Crosscut saws is placed at the same level as Hammer. Although the absolute depth of the Thesaurus's hierarchy cannot be a criterion for deciding basic-level categories, it was obvious that considering its hierarchical relations among concepts can help make decisions on basic levels. Therefore, secondly, other tags and terms not included in nine taxonomies but found in the Thesaurus were categorized into one of three levels. This was done by considering features of the three categories as well as Thesaurus hierarchies. Finally, tags and terms not included in the Thesaurus were also categorized in a consistent way (refer to Yoon(2009) for a more detailed explanation). With regards to basic level colours, the analysis process was more straightforward because eleven basic colours were identified in a previous study (Berlin and Kay 1969): black, white, grey, red, yellow, green, blue, pink, orange, brown, and purple.

Categories and term specificity were coded by a trained masters' level student in the School of Library and Information Science at the University of South Florida. For checking the reliability of the coding for categorical analysis, two methods were used. First, tags and query terms were sorted by attribute and then alphabetical order, and then one of the researchers reviewed the coding, discussed with the student the anomalous codes and corrected anomalous codes (error rate < .01%). Secondly, another trained masters' level student in the same school performed coding checks on 10% of the records. The percentages of inter-coder agreement were 92% for user-supplied tags and 96.4% for search terms. The reliability of the coding for term specificity analysis was checked by examining inter-coder agreement. Again a trained masters' level student in the same school performed coding checks on 10% of the records. The percentages of inter-coder agreement were 89% for both user-supplied tags and search terms.
As a way of identifying characteristics of user-supplied tags and search query terms, a general observation of categorical distributions was described, respectively. First, as shown in Table 4, categorical distributions of user-supplied tags were indicated with respect to the number of unique tags and tag occurrence. The Generic category is the highest number of unique tags (338 unique tags, 63.18%). The Specific category is the next holding 105 unique tags at approximately 20%. The Abstract category and Flickr category show similar percentages of 8.05% and 6.17%, respectively. The Part of speech category takes only three unique tags, less than 1%. It can be noted that there is uniformity across the number of unique tags and tag occurrence. The tags in the Generic category appeared most frequently, 4,905 times or 52.10%, and those in the Specific category appeared 2,740 times (29.97%). The Flickr, Abstract and Colour category appeared 697 times (7.45%), 594 times (6.35%) and 389 times (7.45%), respectively. In general, an overall observation between the number of unique tags and their occurrence confirms that categories with more unique terms have more occurrences of those unique tags.
| Category | Unique tag | Tag occurrence | ||
|---|---|---|---|---|
| Number | % | Number | % | |
| Abstract | 43 | 8.04 | 594 | 6.35 |
| Colour | 13 | 2.43 | 389 | 4.16 |
| Generic | 338 | 63.18 | 4,905 | 52.40 |
| Specific | 105 | 19.63 | 2,740 | 29.27 |
| Part of speech | 3 | 0.56 | 35 | 0.37 |
| Flickr | 33 | 6.17 | 697 | 7.45 |
| Total | 535 | 100 | 9,360 | 100 |
On the other hand, Table 5 shows the uniqueness and occurrence of search terms in three stages of the search process: initial, second, and third stages. Search term distributions in categories are opposite to tag distributions, with more unique tags appearing more frequently in tag distributions. It can be noted that there is little uniformity across the number of unique terms and term occurrence. In the initial stage, unique terms in the Generic, Specific, and Abstract categories account for more than 80%, but Image related, Part of speech, and Boolean categories comprise more than 75% of term occurrences. The tendency for several non-semantic terms to occur very frequently in image search queries similarly appeared in the second and third stages with slight variations. The search query terms in the Generic category show the highest percentage of unique terms in all three stages. In the case of term occurrence distributions, the Image related (I) category accounts for approximately 50% of total term occurrences. As mentioned above, users are supposed to include image related terms in order to articulate their visual information needs when using the Excite search engine. Also, this study finds that users frequently used Boolean (B) terms and Part of Speech (P) when articulating their search needs into queries.
In summary, as shown in Table 4 and Table 5, there are clear differences between tags and search query terms. More specifically, it is recognized that there is considerable discrepancy due to characteristics unique to either search query terms or tags. For instance, search query terms are likely to contain substantial numbers of Image related terms and Boolean operators in order to express users' visual information needs in a query form; whereas tags include Flickr related tags, which are only meaningful in Flickr communities. Since this study compares tags and search queries in order to see the potential of tags as a user-centred subject indexing mechanism, it is reasonable to select semantically meaningful categories such as Abstract, Colour, Generic, and Specific as a way of analysing the differences between tags and search query terms.
| Category | Initial search term | 2nd search term | 3rd search term | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Unique term | Term occurrence | Unique term | Term occurrence | Unique term | Term occurrence | |||||||
| No. | % | No. | % | No. | % | No. | % | No. | % | No. | % | |
| A | 81 | 13.41 | 596 | 4.17 | 18 | 13.95 | 96 | 3.47 | 6 | 11.54 | 25 | 2.27 |
| C | 8 | 1.32 | 88 | 0.62 | 3 | 2.33 | 20 | 0.72 | 1 | 1.92 | 6 | 0.55 |
| G | 276 | 45.70 | 1904 | 13.32 | 65 | 50.39 | 326 | 11.78 | 20 | 38.46 | 93 | 8.45 |
| S | 138 | 22.85 | 734 | 5.13 | 12 | 9.30 | 47 | 1.70 | 4 | 7.69 | 12 | 1.09 |
| P | 37 | 6.13 | 1581 | 10.62 | 12 | 9.30 | 422 | 15.25 | 8 | 15.38 | 180 | 16.36 |
| N | 10 | 1.66 | 49 | 0.34 | 2 | 1.55 | 7 | 0.25 | 0 | 0.00 | 0 | 0.00 |
| I | 22 | 3.64 | 7424 | 51.92 | 14 | 10.85 | 1294 | 46.77 | 11 | 21.15 | 547 | 49.73 |
| B | 3 | 0.50 | 1848 | 12.92 | 2 | 1.55 | 549 | 19.84 | 2 | 3.85 | 237 | 21.55 |
| O | 29 | 4.80 | 138 | 0.97 | 1 | 0.78 | 6 | 0.22 | 0 | 0.00 | 0 | 0.00 |
| Total | 604 | 100.00 | 14299 | 100.00 | 129 | 100.00 | 2767 | 100.00 | 52 | 100.00 | 1100 | 100.00 |
| A: Abstract, C: Colour, G: Generic, S: Specific, P: Part of speech, N: Number, I: Image related, B: Boolean, O: Others | ||||||||||||
Figure 2 demonstrates categorical distributions of unique terms used in tags, the initial search stage, the second search stage and the third search stage. As shown in Figure 2, the overall pattern among tags, initial search terms, second search terms, and third search terms are found to be similar. The Generic category accounts for the majority of tags and search terms in three different stages, and the Colour category comprises only a minor portion. The Abstract and Specific categories are second to the Generic categories, but the order between the two categories is dependent on whether they are in tags, initial search terms, second search terms, or third search terms.
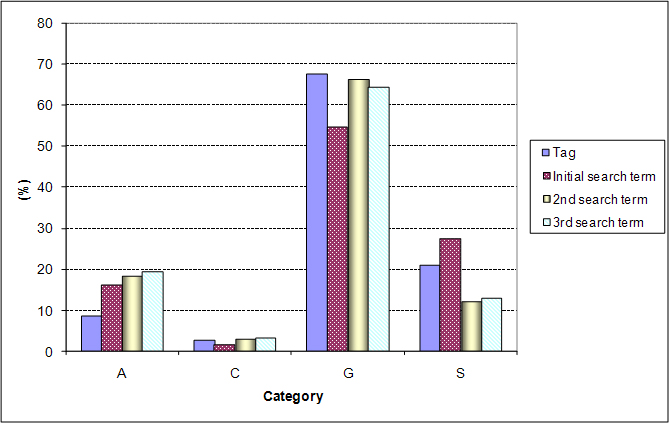
Based on overall categorical distributions of tags and terms in three stages, a chi-squared test was used to examine whether differences among them are statistically significant. As shown in Table 6, there are significant differences in category distributions among the tag and the search terms in three stages. In addition, there are significant differences between the categories of tags and initial search terms. Even among the search terms in different stages, there are significant differences in categorical distributions.
| Row variable | Column variable | Chi squared | df | p |
|---|---|---|---|---|
| Category | Source term | |||
| Abstract; Colour; Generic; Specific |
Tag, Initial, 2nd, & 3rd search terms | 34.422 | (4-1)*(4-1)=9 | 0.000 |
| Tag & Initial search term | 23.562 | (4-1)*(2-1)=3 | 0.000 | |
| Initial, 2nd, & 3rd search terms | 13.359 | (4-1)*(3-1)=6 | 0.038 |
| Tag | Initial search term | 2nd search term | 3rd search term | |||||
|---|---|---|---|---|---|---|---|---|
| Number | % | Number | % | Number | % | Number | % | |
| A1 | 1 | 0.20 | 8 | 1.59 | 2 | 2.04 | 2 | 6.45 |
| A2-1 | 20 | 4.01 | 37 | 7.36 | 9 | 9.18 | 1 | 3.23 |
| A2-2 | 11 | 2.20 | 27 | 5.37 | 5 | 5.10 | 2 | 6.45 |
| A2-3 | 7 | 1.40 | 5 | 0.99 | 1 | 1.02 | 1 | 3.23 |
| A2 | 38 | 7.62 | 69 | 13.72 | 15 | 15.31 | 4 | 12.90 |
| A3 | 4 | 0.80 | 4 | 0.80 | 1 | 1.02 | 0 | 0.00 |
| A4 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 |
| A | 43 | 8.62 | 81 | 16.10 | 18 | 18.37 | 6 | 19.35 |
| C | 13 | 2.61 | 8 | 1.59 | 3 | 3.06 | 1 | 3.23 |
| G1-1 | 28 | 5.61 | 48 | 9.54 | 17 | 17.35 | 6 | 19.35 |
| G1-2 | 31 | 6.21 | 32 | 6.36 | 6 | 6.12 | 1 | 3.23 |
| G1-3 | 189 | 37.88 | 109 | 21.67 | 23 | 23.47 | 8 | 25.81 |
| G1 | 248 | 49.70 | 189 | 37.57 | 46 | 46.94 | 15 | 48.39 |
| G2-1 | 11 | 2.20 | 8 | 1.59 | 4 | 4.08 | 1 | 3.23 |
| G2-2 | 19 | 3.81 | 39 | 7.75 | 7 | 7.14 | 0 | 0.00 |
| G2 | 30 | 6.01 | 47 | 9.34 | 11 | 11.22 | 1 | 3.23 |
| G3 | 52 | 10.42 | 34 | 6.76 | 7 | 7.14 | 3 | 9.68 |
| G4 | 8 | 1.60 | 6 | 1.19 | 1 | 1.02 | 1 | 3.23 |
| G | 338 | 67.74 | 276 | 54.87 | 65 | 66.33 | 20 | 64.52 |
| S1-1 | 13 | 2.61 | 49 | 9.74 | 6 | 6.12 | 0 | 0.00 |
| S1-2 | 2 | 0.40 | 1 | 0.20 | 0 | 0.00 | 0 | 0.00 |
| S1-3 | 2 | 0.40 | 32 | 6.36 | 3 | 3.06 | 0 | 0.00 |
| S1 | 17 | 3.41 | 82 | 16.30 | 9 | 9.18 | 0 | 0.00 |
| S2-1 | 3 | 0.60 | 6 | 1.19 | 1 | 1.02 | 1 | 3.23 |
| S2-2 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 | 0 | 0.00 |
| S2 | 3 | 0.60 | 6 | 1.19 | 1 | 1.02 | 1 | 3.23 |
| S3 | 76 | 15.23 | 45 | 8.95 | 2 | 2.04 | 3 | 9.68 |
| S4 | 9 | 1.80 | 5 | 0.99 | 0 | 0.00 | 0 | 0.00 |
| S | 105 | 21.04 | 138 | 27.44 | 12 | 12.24 | 4 | 12.90 |
| Total | 499 | 100.00 | 503 | 100.00 | 98 | 100.00 | 31 | 100.00 |
| (A: Abstract, C: Color, G: Generic, S: Specific) | ||||||||
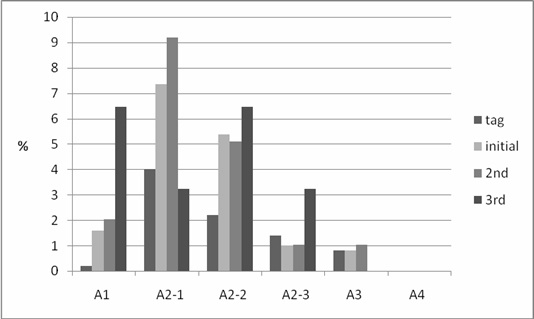
As shown in Table 7, categorical distributions were analysed in detail using the sub-categories for Abstract, Colour, Generic, and Specific. From the Abstract category, image searchers on the Web used abstract terms more frequently in all three search stages compared to Flickr users (8.62% in tags vs. 16.10% in initial search, 18.37% in second search, and 19.35% in third search). More specifically, Figure 3 presents various search terms that appear in the Mythical and fictitious beings (A1) and the Emotion/Abstraction (A2) categories. In the A1 category, terms such as angel, devil, gods, ghost and so on, were only found as search terms. In the A2 category, search terms in Symbolic value (A2-1) and Atmosphere (A2-2) were more diverse than tags. The Abstract location category (A3), however, was identified nearly in similar proportions. The Abstract time category (A4) was neither used in tags or search query terms.
For the Colour category, it was found that basic colour terms identified in a previous study (Berlin and Kay 1969) were used in both tags and search query terms.
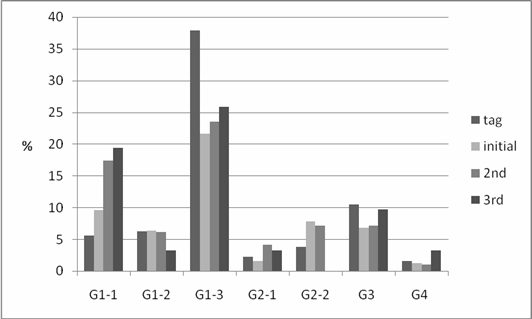
By examining the subcategories of the Generic category in Figure 4, it can be noted that the subcategories of G1-3 (Kind of thing), G1-2 (Kind of animal), G2-1 (Kind of event), and G3 (Generic location) present more diversity in tags than in search query terms. One plausible explanation for this can be deduced by considering photo-storing behaviors in Flickr. Just as with analogue photo albums, users might use Flickr to store travel photos, pet photos, etc. In this sense, image taggers are more likely to use various generic terms compared to image searchers on the Web. On the other hand, search query terms in G1-1 (Kind of person) and G2-2 (Kind of action) are more various compared to tags. Whereas it was difficult to identify what type of G2-2 terms were more frequently used as search queries, in the G1-1 category, terms representing people's occupations (fighter, knights, president, queens, sailor, slave, wife and so on) were prominent in search terms.
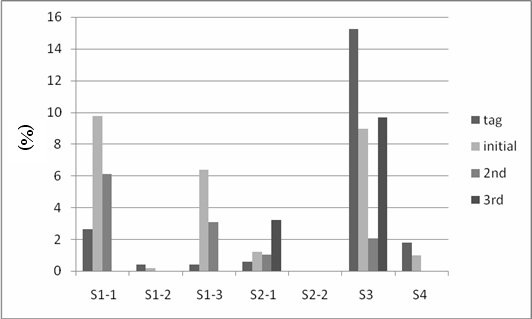
The Specific category is shown in Figure 5. By examining subcategories, it was found that tags in S1-2 (Individually named animal), S3 (Individually named geographic location), and S4 (linear time: date and period) were more diversely used than search query terms in overall, mainly because of S3 (15.23% out of 21.04%). This result can be comprehended in terms of Flickr's photo album features, because Flickr users often apply Specific location names when they upload their pictures for their travel photos and there are only a limited number of popular places where people travel. On the other hand, S1-1 (individually named person), S1-3(individually named thing), and S2-1(individually named event) were in a variety of search terms compared to tags. This trend can be understood due to search engines' general usages, since users often want to find photos of celebrities, cartoon or movie characters, and specific brand names. For S2-2 (individually named action), there was no incidence in tags or search query terms.
With respect to term specificity in tags and search query terms, the level of term specificity was examined in the Colour and Generic categories based on the basic level theory. In the case of the Colour category, eleven basic colour names were used in tags and all stages of search terms. In the Generic category, as noted in Table 8 and Figure 6, the overall distribution of term specificity among tags and search terms was similar; the distribution pattern, with basic level concepts most frequent, was also consistent with the related studies' results. However, this study result also demonstrated that compared to tags, search engine users tend to use subordinate level terms less frequently (13.61% from tag vs. 6.88%, 6.15% & 5.00% from search terms). In addition, contrasting basic and subordinate levels, it seems that the superordinate level in search terms on the Web relatively increases as users revise search query terms toward second and third search phases. In other words, while Flickr users tag images by using more specific terms, Web searchers tend to use superordinate terms more frequently and attempt broader terms when revising initial search queries.
| Level | Tag | Initial search term | 2nd search term | 3rd search term | ||||
|---|---|---|---|---|---|---|---|---|
| Number | % | Number | % | Number | % | Number | % | |
| Superordinate | 20 | 5.92 | 18 | 6.52 | 8 | 12.31 | 4 | 20.00 |
| Basic | 272 | 80.47 | 239 | 86.59 | 53 | 81.54 | 15 | 75.00 |
| Subordinate | 46 | 13.61 | 19 | 6.88 | 4 | 6.15 | 1 | 5.00 |
| Total | 338 | 100.00 | 276 | 100.00 | 65 | 100.00 | 20 | 100.00 |
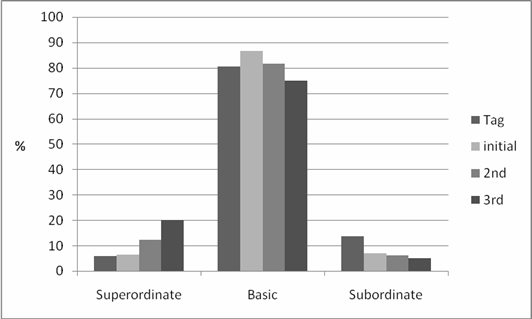
A chi-squared analysis was performed at the level of term specificity of the Generic category to determine whether there were any statistically significant differences among tags, initial search terms, second search terms, and third search terms. As shown in Table 9, it was found that there are significant differences in basic level distribution among the tags and three stages of search terms. Further analysis shows that whereas there is a significant difference between tags and initial search terms, there is no significant difference among search terms in the three stages.
| Row variable | Column variable | chi squared | df | p |
|---|---|---|---|---|
| Term specificity level | Source term | |||
| Superordinate; Basic; Subordinate | Tag, Initial, 2nd, & 3rd search terms | 17.297 | (3-1)*(4-1)=6 | 0.008 |
| Tag & Initial search term | 7.265 | (3-1)*(2-1)=2 | 0.026 | |
| Initial, 2nd, & 3rd search terms | 6.139 | (3-1)*(3-1)=4 | 0.189 |
Recent studies have utilized user-supplied tags, especially Flickr tags, as a way of representing images from users' perspectives and for indexing schemes and thesaurus constructions. Although these endeavours have been conducted on the assumption that user-supplied tags have considerable potential as a user-centred organization mechanism, there has been little research to understand how these tags compare to search terms. This study investigated the features of tags and search query terms by categorical comparisons and the level of specificity comparisons. In addition to examining overall patterns, statistical analyses were conducted to examine whether there were any significant differences in categories and specificity levels between tags and search query terms in three different stages.
In general, tags, initial, second, and third search terms appeared to have similar categorical and term specificity distribution; however, the results of chi-squared analyses demonstrated that there are significant differences both in categories and term specificity between tags and search query terms. Since this research is one of the first studies to compare tags and search queries, these findings can be explained in many ways. Explanations from a more fundamental perspective would be desirable in this sense. First, although both Flickr and Web search engines contain general or non-domain-specific image collections which are open to public users, there exist to some extent unique characteristics that inherently distinguish the two collections. Flickr users tag their own images not only for sharing with others (i.e., indexing), but also for storing and organizing their photos (i.e., describing), whereas search engine users search images (i.e., retrieving), which have been created by others without any concrete ideas of which images are searchable and how. For example, Flickr users often upload pictures from their travels, producing many general and specific location tags, whereas search engine users are more likely to search pictures on the basis of specific information such as celebrities' names, cartoon characters, and products with specific brand names.
Secondly, a task-oriented perspective can explain differences between describing tasks in tags and retrieving tasks in queries. In the case of the Abstract category, this result is consistent with Jogensen's (1995; 1998) and Fidel's (1997) results which showed that users have a tendency to use abstract terms more frequently in retrieving tasks than in describing tasks. Again, this result supports the idea which emphasizes the importance of providing an access mechanism for abstract categories in image retrieval systems, in spite of the difficulties in representing abstract messages (Greisdorf and O'Connor 2002; Black et al. 2004; Enser et al. 2007). The results of the analysis of term specificity level also can be understood on the same basis. As found in previous basic level studies on images (Jogensen 2003; Rorissa 2008), overall basic level terms were dominant in tags as well as all stages of search terms. However, when statistically comparing tags and search queries, it was found that there are differences in the level of term specificities between describing and searching tasks; image searchers who do not have a clear idea of what they want to find are more likely to use superordinate level terms, whereas Flickr users who describe their own photographs tend to use subordinate terms more frequently than searchers.
In this sense, the findings of this study might present a challenge to current research efforts on utilizing user-supplied tags as a promising access point for images. As introduced in the Related studies section, lines of research have attempted to utilize Flickr tags in order to understand users' image describing patterns as well as to develop a user-centred controlled vocabulary. These recent studies have been based on the assumption that frequently used terms in Flickr can be an access point in the image search process. Overall, patterns of categorical and specificity distribution results support this approach. However, statistical results demonstrated significant differences in categorical distribution and term specificity levels. The findings of this study suggest that although Flickr tags, which are currently the most popular image tagging system, can be a valuable source for understanding user-centred image representation patterns, it is important to consider its image collection features and its user groups - i.e., Flickr users describe their own pictures. In other words, Flickr tags can provide some basics for public users' image describing behaviours in general, but they need to be customized depending on the collection. In addition, the findings of this study suggest collecting tags should be collected for each collection, if possible, and then utilized for that particular collection, such as in the Steve Museum project.
In addition to the comparisons between tags and search terms, this study compared search terms in different stages. In general, tags and initial search query terms are similar in terms of overall categorical distributions. The Generic category is the most popular followed by the Specific and the Abstract categories; the Colour category is the least popular. On the other hand, compared to initial search query terms, second search query terms and third search query terms present slightly different categorical distributions, as the Abstract and Generic categories are more frequently used, and the Specific category is less prominently used. Although a significant difference was not identified, the term specificity level analysis showed that searchers tend to adopt more superordinate terms instead of subordinate terms as they revise search terms. This implies that an image retrieval system should facilitate users revising their searches by providing semantically related concepts including related abstract terms and superordinate concepts. Also, if users tend to avoid terms in the Specific category due to the difficulties in finding alternative specific terms, the image retrieval system should provide useful guidelines for alternative terms - either other terms in the Specific category or related terms in the Generic category - for terms in Specific category.
Image descriptions supplied by users are clearly good resources to adopt when constructing user-centred indexing systems. Many efforts have attempted to understand the characteristics and features of tags, while little empirical research exists to explore user-supplied tags compared to search queries. In this sense, this study explored the differences between tags and queries submitted for searching images in order to investigate the features and characteristics of user-supplied tags in terms of user-centred indexing system construction.
This study identified differences between user-supplied tags and search queries for images in terms of categories and levels of specificity. Overall distribution of categories and levels of specificity were found to be similar between user-supplied tags and search query terms. The Generic category is the most frequently used for both tags and search query terms. Following the Generic category, the Specific and Abstract categories were next in frequency. The Colour category was identified as the least used category.
The findings of this study are in line with previous research (Chen 2001; Collins 1998; Choi and Rasmussen 2003; Jogensen 1998). Regarding levels of specificity, distribution in three levels (superordinate, basic, and subordinate) demonstrated that the basic level was most frequently used. Superordinate and subordinate levels followed. Moreover, statistical analyses on distributions were performed to examine whether the differences in categories and levels were statistically significant. In regards to categories, significant differences were found among tags, initial search terms, second search terms, and third search terms. Statistical analyses on the level of specificity demonstrated significant differences between tags and the three stages of search query terms, but no significant differences among the three different stages of a single search. While many possible explanations can be applied to the results of this study, one fundamental reason for these differences in categories and levels of specificity can be induced from the inherent functionality of each collection, Flickr and image search engines on the Web. For instance, tags in Flickr are mainly created for storing and sharing, not considering retrieval uses, while search queries for images on the Web are primarily for searching images. Another fundamental perspective is to understand the inherent differences because of dissimilar tasks such as searching and describing an image.
These findings have fundamental and practical implications. Basically, the findings of this study imply that directly utilizing Flickr tags on user-centred indexing systems needs to be reconsidered. It is desirable to take into account collections, users' features, and differences in tasks when designing user-oriented index systems. More practically, involvement would at least address interface design issues of image searching and tagging. In terms of image searching and tagging interface design, the results in this work provide categorical and specificity guidelines for designing image retrieval and tagging system interfaces. For instance, image tagging and searching interfaces could employ appropriate categories and levels of specificity as users progress their searches.
Evidently, future studies and analyses are necessary to further comprehend the relationships between user-supplied tags and search queries for images. This study compared two different data sets, Flickr and Web search queries. It is a meaningful approach to have used the most popular image tagging system in analysing user-tagging behaviors, because it demonstrated that Flickr tags have their own unique features which cannot simply be generalized for other image collections. However, in order to investigate differences between two tasks, tagging and searching, future studies should compare two data sets which are extracted from a single collection. Also, tags might exist which do not match search queries but would assist users to navigate or browse image collections. Therefore, in addition to comparing tags and queries in quantitative ways, it should be investigated how users use tags during the actual image search process and how tags improve search effectiveness. Another future research area proposed by the current study is image search query reformulation. As this study demonstrated changes from initial search queries to transformed queries, once reformulation patterns can be specified, they will be useful in designing an interactive image retrieval system which effectively support the query revising process of users.
The authors gratefully acknowledge Dr. Jim Jansen's generous sharing of Excite data and insightful reviews from two anonymous reviewers. We also thank Stacy Davis for her assistance in data analysis and Ga Young Lee for her various assistance.
| Find other papers on this subject | ||
© the authors, 2009. Last updated: 14 August, 2007 |
