vol. 16 no. 4, December, 2011
vol. 16 no. 4, December, 2011 | ||||
La tecnología se ha convertido en un agente de primer orden en la Sociedad del Conocimiento debido a su importancia en el entorno de las organizaciones y para el funcionamiento de la sociedad en general (Soto-Acosta y Meroño-Cerdan 2008, Soto-Acosta et al. 2010b). En las organizaciones actuales, que cada vez son más intensivas en conocimiento, la tecnología representa la columna vertebral que hace que el conocimiento y la información se puedan compartir, crear y almacenar, posibilitando a las organizaciones la oportunidad de ventajas competitivas basadas en el conocimiento (Lopez-Nicolas and Soto-Acosta 2010; Sharma et al. 2010). Estos hechos han colocado al conocimiento como un activo clave en torno al cual se han articulado términos y conceptos tales como: “Sociedad del Conocimiento”, “Economía del Conocimiento” o “Cultura del Conocimiento” (Bakry y Alfantookh 2010).
En este entorno, las tecnologías de la información y la comunicación conforman un activo esencial a través del cual se realizan actividades intensas en conocimiento en las que las organizaciones cimentan sus operaciones (Trigo et al. 2009). En este sentido, las tecnologías de la información y la comunicación son consideradas fundamentales para el desarrollo de productos y servicios (Gonzálvez-Gallego et al. 2010; Soto-Acosta et al. 2010c). El sector de las tecnologías de la información y la comunicación lo componen organizaciones que se dedican a: desarrollar y comercializar software empaquetado y a medida; a ofrecer infraestructura tecnológica; y a dar soporte tecnológico y consultoría (O'Sullivan and Dooley 2010). La importancia que tiene el software en el ámbito de las tecnologías de la información y la comunicación ha convertido a la industria de desarrollo de software en una de las más influyentes en el mundo y en una industria clave para el crecimiento económico. El proceso del desarrollo de software se basa en tres pilares fundamentales: procesos, tecnologías y personas. Estos pilares se encuentran interconectados, formando un triángulo fundamental para que las organizaciones operen (Hernández-Lopez et al. 2010; Soto-Acosta et al. 2010a). Sin embargo, el desarrollo de software implica, además de la producción de programas ejecutables y otros elementos de software, la generación de documentación de soporte al proceso de desarrollo, a la explotación y al mantenimiento del software. En muchas ocasiones, la documentación de soporte no presenta la calidad que sí se encuentra en el producto software final (Lethbridge et al. 2003). Sin embargo éste elemento es una herramienta útil en dos tareas fundamentales del proceso de desarrollo de software: el mantenimiento (e.g., Kajko-Mattsson 2005) y la reutilización (e.g., Yao et al. 2008).
La documentación es un componente fundamental para la calidad del software (Kajko-Mattsson 2005), facilitando el mantenimiento perfectivo, defectivo y adaptativo. La literatura ha demostrado desde los años 1980 que la ausencia de documentación es una de las causas principales de defectos en el mantenimiento, al mismo tiempo que los costes de mantenimiento de los sistemas que cuentan con una buena documentación son menores (e.g., Card et al. 1987; Rombach y Basili 1987). Además, una buena documentación permite habilitar la reutilización del software. La reutilización del software es el proceso de crear software desde sistemas existentes en lugar de realizarlo desde cero (Krueger 1992). La reutilización es una técnica de probada efectividad para el ahorro de costes, ya sea, entre otros aspectos, en los tiempos de desarrollo o en la fiabilidad de los componentes previamente probados (Frakes y Kang 2005; Kim y Stohr 1998; Mohagheghi y Conradi 2007; Selby 2005).
En el entorno de la reutilización, los mecanismos de soporte a la búsqueda con vistas a la reutilización de software suelen estar basados en palabras clave (Sugumaran y Storey 2003). Sin embargo, atendiendo a Yao et al. (2008), estos mecanismos pueden ser enriquecidos de forma sustancial con el uso de técnicas basadas en el conocimiento que soporten una mejor búsqueda en los repositorios software.
Con el propósito de que tanto la reutilización como el mantenimiento del software se puedan realizar de forma más efectiva, el presente trabajo presenta la herramienta SemSEDoc (Semantic Software Engineering Documentation). Esta herramienta propone la utilización de tecnologías semánticas en el aprovechamiento de los repositorios documentales de los proyectos de desarrollo de software. Para ello, SemSEDoc mediante el uso de Procesamiento del Lenguaje Natural, lleva a cabo un análisis de la documentación generada, anotando semánticamente los documentos gracias al uso de una ontología de dominio y otra funcional.
El advenimiento de la Web semántica ha supuesto una revolución en la forma de acceso y almacenamiento de la información. El término Web Semántica fue acuñado por Berners-Lee et al. (2001) para describir la evolución desde un paradigma basado en documentos hacia un nuevo paradigma que incluye de forma coordinada la información y los datos con el propósito de ser manipulado de forma automática. La utilización de soporte semántico en soluciones de las tecnologías de la información y la comunicación permite la introducción de inteligencia en los sistemas software, circunstancia que no es posible en los sistemas basados en datos simples (Álvarez-Sabucedo 2010). En particular, atendiendo a Berners-Lee et al. (2006), las tecnologías semánticas se entienden para la creación de codificaciones declarativas con el fin de facilitar la interoperatividad, la integración y el acceso a los datos. Teniendo en cuenta que el acceso a la información es uno de los retos más importantes para los sistemas de información en la actualidad (Morales-Del Castillo et al. 2009), las tecnologías semánticas se perfilan como habilitadoras del acceso inteligente y preciso a grandes repositorios de datos.
Atendiendo a Warren (2006), las tecnologías semánticas proporcionan una visión complementaria que, en muchos casos, ha expandido y reemplazado los arquetipos de la gestión del conocimiento y de la información (Davies et al. 2007). Las ontologías proporcionan vocabularios estructurados que describen especificaciones formales de las conceptualizaciones. Estas tecnologías proponen una solución para representar el significado de la información, lo que conduce a una más efectiva gestión de los datos gracias al establecimiento de un vocabulario común (Shadbolt et al. 2006). Los beneficios que conllevan la adición de semántica a los contenidos consisten en eliminar las inconsistencias terminológicas. La anotación semántica identifica formalmente conceptos y relaciones entre éstos (Uren et al. 2006). Esta anotación debe ser explícita, formal y no ambigua, siendo sus beneficios principales una mejor búsqueda e interoperabilidad (Uren et al. 2006). Una introducción sobre las principales herramientas y conceptos relativos al empleo de tecnologías semánticas se puede encontrar en el trabajo de Brooks (2009).
El empleo de las tecnologías semánticas en aplicaciones industriales se ha extendido, por su utilidad e impacto (García-Crespo et al. 2010a). Así, su aplicación en el campo de la ingeniería del software no es nueva. La literatura ha recogido esfuerzos relativos a la aplicación de tecnologías semánticas en campos como: la formación y gestión de equipos de desarrollo de software (e.g., Colomo-Palacios et al. 2010; Valencia-García et al. 2010); la utilización de patrones (Dietrich et al. 2008); componentes (Colomo-Palacios et al. 2008) o como tecnología habilitadora para la reutilización (Henriksson et al. 2008); la gestión de métricas del software (e.g., Gall et al. 2008; García-Crespo et al., 2009); el soporte a los procesos de análisis (Girardi y Leite 2008; Tappolet et al. 2010); apoyo en el desarrollo de software global (Wongthongtham et al. 2009); la ayuda para la evaluación CMMi (Lee and Wang 2009), por citar algunos de los casos y áreas más significativos y recientes. El trabajo de Zhao et al. (2009) contiene una revisión detallada de la aplicación de técnicas semánticas en diferentes aspectos relacionados con la ingeniería del software.
En el entorno específico del enriquecimiento semántico de la documentación generada durante el proceso de desarrollo de software, los esfuerzos también son notables y recientes (e.g., De Lucia et al. 2007; García et al. 2009; Hyland-Wood et al. 2008; Zhang et al. 2008). Sin embargo, ninguno de los trabajos anteriores posibilita el etiquetado semántico semi-automático de la documentación generada como soporte al proceso software, mediante una ontología funcional y otra de dominio. Dicha funcionalidad permite una búsqueda y gestión de la documentación más efectiva, habilitando de esta manera un mejor mantenimiento de la propia documentación y del software soportado por la misma.
SemSEDoc se presenta como una herramienta de apoyo a la gestión de la documentación almacenada en repositorios de proyectos. La herramienta ha sido diseñada para actuar en proyectos realizados bajo la metodología Métrica versión 3. Métrica3 es una metodología de desarrollo elaborada por el Consejo Superior de Informática del Ministerio de Administraciones Públicas de España. La metodología presenta tres procesos principales: A) Planificación, B) Desarrollo y C) Mantenimiento de Sistemas de Información. De estos tres, se ha considerado únicamente el proceso de Desarrollo de Sistemas de Información. Dentro de este proceso se han tenido en cuenta la documentación que surge de los cinco subprocesos que lo componen: A) Estudio de Viabilidad del Sistema; B) Análisis del Sistema de Información; C) Diseño del Sistema de Información; D) Construcción del Sistema de Información e Implantación; y E) Aceptación del Sistema. En la figura 1, se plasma la estructura de la herramienta y su relación con el repositorio de proyectos y los usuarios.
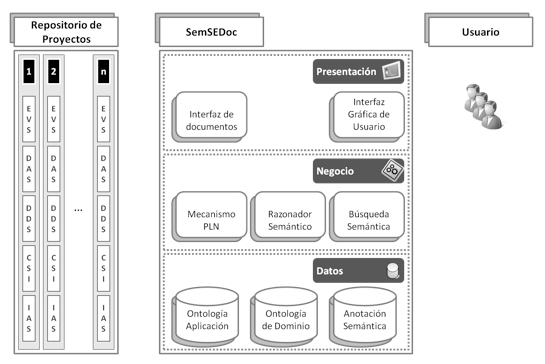
SemSEDoc obtiene la información necesaria del proyecto mediante una interfaz de documentos con el repositorio de proyectos. Dicho repositorio contiene la documentación generada en diversos proyectos a partir de las recomendaciones de Métrica3. La documentación es analizada mediante un Mecanismo de PLN que detecta aquellos elementos susceptibles de ser etiquetados, proceso que se lleva a cabo de forma semi-automática. Teniendo en cuenta que la anotación semántica, debido al esfuerzo que conlleva, se considera una barrera potencial para el uso de tecnologías semánticas (Benjamins et al. 2008), se ha optado por una anotación semi-automática, con el fin de hacer menos tedioso el proceso y evitar los errores de las anotaciones semánticas automáticas.
Una vez llevada a cabo la etiquetación semántica, que se almacena debidamente en la capa correspondiente, los mecanismos de búsqueda y razonamiento semántico se encuentran habilitados para llevar a cabo su labor, directamente relacionada con las capacidades de la herramienta de buscar elementos relativos a proyectos de desarrollo de software y su interrelación con otros. Recordemos que el fin último es el de incrementar la reutilización y de acrecentar el mantenimiento del software.
La arquitectura del aplicativo se compone de tres capas: Presentación, Negocio y Datos. Esta solución arquitectónica garantiza un mejor mantenimiento, además de permitir un desarrollo más modular. La capa de Presentación se comunica dentro de la aplicación con la capa de Negocio y sirve de interfaz de SemSeDoc con dos actores cruciales del sistema. En primer lugar, se comunica con los usuarios a través del módulo “Interfaz Gráfica de Usuario”. Este módulo aglutina la interacción con el usuario final en relación a las búsquedas y la anotación semántica de documentos. El segundo de los módulos es el encargado de interactuar con el repositorio de proyectos. En la actualidad, dicho módulo es una interfaz que lleva a cabo la comunicación de la aplicación con el conjunto de documentos listados en un cúmulo de proyectos. El requisito para su utilización es que dichos documentos deben encontrarse en un índice y su contenido debe ser codificado en formato HTML. Esta funcionalidad se plantea ser sustituida por la implementación de un crawler que permita una búsqueda no estructurada de documentos codificados en diferentes formatos (Portable Document Format, Rich Text Format, Microsoft Word, etc).
En la capa de lógica de negocio existen tres módulos. El primero de ellos es el correspondiente al mecanismo para el PLN. Este componente analiza los documentos que se encuentran en el repositorio de proyectos. Así, el componente utiliza las herramientas GATE para la anotación sintáctica de los contenidos y JAPE para extraer los conceptos relativos a la ontología de dominio y la funcional. Posteriormente, a partir de la lista proporcionada se sugiere la anotación semántica de los diferentes elementos de forma semi-automática. El segundo de los módulos que presenta la capa de lógica de negocio es el razonamiento semántico. Un razonador semántico típicamente deriva hechos de una base de conocimiento con el propósito último de formular nuevas conclusiones. En el caso particular de la herramienta que nos ocupa consiste en un razonador basado en OWL (Ontology Web Language). Este lenguaje incorpora un modelo semántico que permite la creación de sistemas de razonamiento. Así, la herramienta incorpora a RACER (Renamed ABox and Concept Expression Reasoner) para llevar a cabo la tarea descrita. El componente de búsqueda semántica utiliza el lenguaje de consultas SPARQL RDF para llevar a cabo consultas en la capa de datos. Una de las características de la herramienta es la búsqueda por facetas. Con metadatos por facetas (Ranganathan 1962), el espacio de información se divide en particiones utilizando dimensiones conceptuales ortogonales de los datos. Estas dimensiones se llaman facetas y representan las características de los elementos de la información. Estas facetas se utilizan para seleccionar o filtrar elementos relevantes en un determinado espacio de información, llevando así a los usuarios exactamente a la información necesaria. Estas facetas son las propiedades definidas en el dominio de las ontologías. La búsqueda semántica por facetas ha sido utilizada con éxito en herramientas del ámbito semántico, tal y como reflejan diferentes trabajos en la literatura (e.g., García-Crespo et al. 2010b, 2011; Gómez-Berbís et al. 2011; Prasad y Madalli 2008; Suominen et al. 2009).
La última capa es la de datos o persistencia. En dicha capa se almacenan, por un lado, las ontologías de aplicación y de negocio y, por otro, las anotaciones semánticas de los documentos analizados. Dicho repositorio ha sido implementado utilizando las capacidades de Jena sobre SESAME. De esta forma, se consigue la persistencia de las ontologías, la realización de consultas en el entorno desarrollado y se ofrece un nivel de abstracción de la complejidad que permite el almacenamiento y la recuperación de ontologías OWL DL en conjunción con su sintaxis RDF.
A continuación se describe la evaluación llevada a cabo con el propósito de testar si SemSEDoc sirve como sistema de gestión de la documentación generada como soporte al proceso de desarrollo de software en un entorno controlado.
Una vez que el sistema ha sido desarrollado y testado desde el punto de vista del proceso de desarrollo, se necesita probar la validez de SemSEDoc. Así, se pretende conocer dos tipos de características del aplicativo en relación con su utilización. En primer lugar, la bondad de los resultados del proceso de búsqueda y, por ende, del conjunto de funcionalidades de etiquetado y, en segundo lugar, se pretende testar si el procedimiento de anotación semiautomático produce sugerencias de anotación pertinentes de acuerdo con el juicio de los expertos. Esta segunda característica comprueba si las sugerencias de anotación de los diferentes documentos coincide con la anotación manual de los expertos.
Ambos aspectos requieren la utilización de métricas conocidas y efectivas. Para ello, se utilizarán las métricas Precision, Recall y F1. Las dos primeras fueron introducidas por Cleverdon et al. (1966). Con posterioridad, la métrica F1 fue diseñada por van Rijsbergen (1979) con el propósito de integrar en una única medida y con importancia equivalente las capacidades de ambas métricas. Un trabajo reciente y relevante que analiza el uso de las citadas métricas es el publicado por Good and Tennis (2009). Las tres métricas se pueden definir atendiendo a las siguientes formulaciones:
Precision = Resultados encontrados correctos / Total de resultados encontrados
Recall = Resultados encontrados correctos / Total de resultados Correctos
F1 = (2 * Precision*Recall) / (Precision+Recall)
Para llevar a cabo ambos procedimientos se contó con un repositorio de proyectos compuesto por un total de 9 proyectos de desarrollo de software ejecutados bajo los dictados de Métrica3. Dicho repositorio de proyectos fue alojado en un ordenador conectado a una red de área local en la que se encontraba también el servidor que albergaba a SemSEDoc. Con el propósito de testar los aspectos expuestos anteriormente, se contó con un total de 18 sujetos cuya participación efectiva en los proyectos les habilitara permite realizar un juicio sobre la bondad de la herramienta en la búsqueda y anotación semántica.
Teniendo en cuenta el doble objetivo de la evaluación, se diseñó una tarea doble para los sujetos. Así, y tras llevar a cabo la recolección de los datos de identificación del sujeto, en primer lugar, cada sujeto debía llevar a cabo la anotación de uno de los documentos generados como soporte al desarrollo del proyecto en el que los sujetos habían llevado a cabo su labor. El documento (un acta de reunión relativa a la recolección de requisitos), que en todos los casos había sido examinado con anterioridad, contenía texto para llevar a cabo un conjunto suficiente de anotaciones (alrededor de veinte). El diseño del experimento habilitaba la verificación de la bondad del proceso de anotación en relación al conjunto de anotaciones posibles mediante la comparación de las anotaciones de los expertos con las sugerencias producidas por el sistema. En segundo lugar, se solicitaba a los sujetos que llevaran a cabo una búsqueda de un término (un aspecto específico relativo a un requisito de usuario) restringiendo la misma a un conjunto de documentos dado (estudio de viabilidad del sistema y análisis del sistema de información). En este caso, el objetivo es probar si se producen los resultados de búsqueda deseados. Los datos de los resultados de búsqueda se comparan con la búsqueda realizada, por los sujetos de forma libre, mediante el acceso a los documentos utilizando un navegador y capacidades de búsqueda textual, además de la lectura.
Los sujetos llevaron a cabo su labor asistidos en todo momento por un miembro del equipo de desarrollo de SemSEDoc y codificaron sus resultados con ayuda de un cuestionario. A la finalización de su trabajo entregaron el cuestionario al miembro del equipo de proyecto, quien codificó los resultados utilizando la herramienta estadística SPSS.
La muestra se compone de 18 sujetos. La distribución de los sujetos por sexos se establece en 13 hombres (72.22%) y 5 mujeres (27.78%). Todos ellos cuentan con experiencia en los 9 proyectos objeto de estudio, escogiendo 2 sujetos por proyecto, con el fin de contar con más de una opinión por proyecto. El rol de los diferentes sujetos en los proyectos se distribuye de la siguiente manera: Jefe de Proyecto (7), Gestor de Configuración (5), Gestor de Calidad (4) y Analista-Programador (2). Todos los sujetos contaban con experiencia previa en la anotación semántica de textos.
La tabla 1 contiene los resultados de las anotaciones de los sujetos y la herramienta. La columna Sujeto x contiene las anotaciones realizadas por uno de los sujetos en un determinado proyecto. La columna TOTAL refleja la suma de las anotaciones diferentes de los dos sujetos que figuran en las columnas anteriores. SemSEDoc contiene las anotaciones de la herramienta y Comunes exhibe la intersección de las anotaciones de la herramienta y de la columna TOTAL.
| Proyecto | Sujeto 1 | Sujeto 2 | TOTAL | SemSEDoc | Comunes |
|---|---|---|---|---|---|
| Proyecto 1 | 21 | 21 | 21 | 19 | 19 |
| Proyecto 2 | 24 | 24 | 24 | 25 | 20 |
| Proyecto 3 | 19 | 20 | 20 | 21 | 18 |
| Proyecto 4 | 26 | 27 | 27 | 29 | 25 |
| Proyecto 5 | 22 | 22 | 22 | 23 | 19 |
| Proyecto 6 | 19 | 18 | 19 | 18 | 17 |
| Proyecto 7 | 18 | 19 | 19 | 19 | 18 |
| Proyecto 8 | 20 | 20 | 20 | 18 | 17 |
| Proyecto 9 | 25 | 25 | 25 | 23 | 21 |
A partir de los resultados mostrados en la Tabla 1, se localizó por parte de los sujetos un total de 197 elementos susceptibles de ser anotados. La herramienta detectó un total de 195 elementos, de los que 174 coincidían con los señalados por los usuarios. Con el propósito de verificar si existían diferencias significativas desde el punto de vista estadístico entre los resultados obtenidos por los expertos (TOTAL) y las anotaciones sugeridas por SemSEDoc que se consideran correctas (Comunes), se utilizó el método estadístico de la t de Student. El nivel de significación se situó en 0.05. Los resultados del test indican que ambos resultados no presentan diferencias significativas (t(9)=2.02, p>0.05) entre sí, por lo que se puede confirmar la cercanía de los resultados ofrecidos por SemSEDoc al estándar de anotación.
Con respecto a las métricas de bondad, la medida Precision (Precisión) se situó en 0.892307692, mientras que la métrica Recall (Exhaustividad) resultó ser de 0,883248731 y la ponderada armónica F1 fue de 0.887755102.
A continuación, se exponen los resultados de la comparativa entre las búsquedas llevadas a cabo por la herramienta desarrollada y la que han llevado a cabo los usuarios. La Tabla 2 contiene los resultados de dicho proceso. La descripción de las columnas es análoga a la que aparece para la Tabla 1, con la salvedad de que los resultados son consignados para las búsquedas en lugar de las anotaciones.
| Proyecto | Sujeto 1 | Sujeto 2 | TOTAL | SemSEDoc | Comunes |
|---|---|---|---|---|---|
| Proyecto 1 | 45 | 50 | 52 | 48 | 41 |
| Proyecto 2 | 66 | 70 | 71 | 72 | 62 |
| Proyecto 3 | 30 | 23 | 31 | 34 | 18 |
| Proyecto 4 | 28 | 23 | 28 | 29 | 19 |
| Proyecto 5 | 52 | 47 | 54 | 43 | 43 |
| Proyecto 6 | 58 | 69 | 75 | 54 | 50 |
| Proyecto 7 | 43 | 36 | 44 | 42 | 35 |
| Proyecto 8 | 32 | 34 | 34 | 29 | 24 |
| Proyecto 9 | 56 | 49 | 59 | 52 | 40 |
De los resultados ofrecidos en la Tabla 2, se desprende que se localizan por parte de los sujetos un total de 448 resultados de búsqueda. La herramienta arrojó un total de 403 resultados, de los que 332 coinciden con los señalados por los usuarios. De forma análoga a la anterior, los resultados de la comparación de medias entre TOTAL y Comunes tampoco presenta diferencias estadísticamente significativas entre ambas poblaciones (t(9)=1.73, p>0.05). Este hecho implica una semejanza de los resultados obtenidos por los expertos y la herramienta desde la perspectiva numérica.
Respecto a las métricas de bondad, la medida Precision (Precisión) resultó ser de 0.82382134, mientras que la métrica Recall (Exhaustividad) alcanzó un valor de 0.741071429 y la ponderada armónica F1 se situó en 0.780258519.
Atendiendo a sus resultados, SemSEDoc se presenta como una herramienta que puede producir resultados atractivos para la gestión de repositorios de documentación relativa al proceso de desarrollo de software. Los resultados de la anotación se consideran semejantes a los obtenidos por otras herramientas de anotación basadas en procedimientos de PLN (e.g., García-Crespo et al. 2010a; Miao et al. 2009), donde la métrica combinada F1 ronda los 0.9 puntos y en algunos casos de forma ligeramente superior a los resultados ofrecidos por otros trabajos del área (Morales del Castillo et al. 2009). Con relación a la búsqueda, teniendo en cuenta que ésta basa su efectividad en el anotado de los documentos (se considera madura la tecnología de búsqueda semántica que sustenta la herramienta) los resultados son análogos, aunque ligeramente inferiores a los obtenidos en la anotación. Esto puede ser debido a que, si bien la búsqueda se ha llevado a cabo en un entorno compuesto únicamente por dos documentos (Estudio de viabilidad del sistema y Análisis del sistema de información), la complejidad de ambos documentos es mucho mayor que el documento de Acta utilizado para la primera tarea. Adicionalmente, se detectó que en los proyectos 5 y 8 las diferencias entre las poblaciones provenían de una incompleta definición de los mecanismos de PLN. Dicha incorrección (no inclusión de un sinónimo en el vocabulario), impidió la detección de un total de 6 ocurrencias para el Proyecto 5 y de 7 para el Proyecto 8. Esta incidencia revela un ámbito de mejora sustancial en la gestión de los vocabularios para el PLN. Por otra parte, se considera que los mecanismos semánticos que sustentan el proceso de búsqueda han producido resultados muy destacados en efectividad y rendimiento.
La última de las cuestiones que se deben plantear son las limitaciones del estudio emprendido. La primera de las limitaciones tiene que ver con el ámbito de la prueba. Dicha prueba se realizó en un entorno de proyectos de tamaño pequeño y controlado. De esta forma, las obligaciones de observancia del rendimiento necesarias para la explotación de SemSEDoc en un entorno real quedan fuera del ámbito del presente trabajo. En segundo lugar, la prueba de búsqueda y anotación también se realizó en un conjunto de documentos definido, por lo que la riqueza de producción documental de un proyecto de desarrollo de software (aún cuando éste se desarrolla guiado por una metodología pesada y perfectamente pautada como Métrica 3) no fue tenida en cuenta en su totalidad. La tercera de las limitaciones proviene de la composición de la muestra, que si bien cubre un total de nueve proyectos, incluye la participación de sólo dos componentes del equipo de trabajo por proyecto.
La importancia del software en el mundo de hoy en día supone que su desarrollo deba ser afrontado desde una perspectiva ingenieril e industrial. En este escenario, la documentación que soporta el proceso software, representa una fuente de información y de gestión del conocimiento que, en muchos casos, no es aprovechada de forma conveniente. Por otra parte, las tecnologías semánticas se han revelado en los últimos años como importantes habilitadoras en aspectos como la gestión del conocimiento y el aprovechamiento inteligente de la información depositada en repositorios. Teniendo en cuenta ambas circunstancias, en el presente trabajo se ha presentado SemSEDoc, una herramienta tendente al aprovechamiento de las ventajas de las tecnologías semánticas en el entorno de la documentación generada como soporte al proceso software.
La herramienta desarrollada permite una gestión de la documentación a partir del anotado semántico semi-automático de los contenidos. Dicho anotado se considera semi-automático, ya que el sistema sugiere las anotaciones, pero es el usuario el que las realiza. Adicionalmente, y desde el punto de vista de búsqueda de informaciones, la aplicación permite la navegación semántica y la búsqueda por facetas de los documentos. Desde el punto de vista de la evaluación de la herramienta, SemSEDoc presenta unos resultados muy prometedores en relación a la gestión de información.
Por último, se quieren poner de manifiesto diversos trabajos futuros que emanan del diseño e implementación de SemSEDoc. En primer lugar, se sugiere la expansión de las funcionalidades del aplicativo para incluir otras metodologías de desarrollo de sistemas de información. En segundo lugar y desde un punto de vista más técnico, se propone la realización de un crawler que permita la gestión de repositorios de artefactos software en formatos distintos a HTML, con una organización no conocida y dispersos desde el punto de vista de su acceso y almacenamiento. En tercer lugar, se propone dotar a la herramienta de capacidades para el análisis de código fuente. Dicha funcionalidad ampliaría las capacidades de utilización de SemSEDoc en entornos donde la documentación no haya sido generada o se haya extraviado, habilitando así el uso de la herramienta en entornos de Reingeniería del Software. Por último, se sugiere la incorporación de tecnologías que permitan el aprendizaje continuado de SemSEDoc en el ámbito de la búsqueda de términos para su posterior anotación. Dichas técnicas relacionadas con la inteligencia artificial permitirían al aplicativo la mejora continuada en el proceso clave para SemSEDoc: las recomendaciones de anotación.
Francisco J. García-Peñalvo es Profesor Titular de Universidad en el Departamento de Informática y Automática de la Universidad de Salamanca. Se le puede contactar en el correo electrónico: fgarcia@usal.es
Ricardo Colomo-Palacios es Profesor Titular de Universidad Interino del Departamento de Informática de la Universidad Carlos III de Madrid . Se le puede contactar en el correo electrónico: rcolomo@inf.uc3m.es
Pedro Soto-Acosta es Profesor Titular de Universidad del Departamento de Organización de Empresas y Finanzas de la Universidad de Murcia. Se le puede contactar en el correo electrónico: psoto@um.es
Isabel Martínez-Conesa es Profesora Titular del Departamento de Economía Financiera y Contabilidad de la Universidad de Murcia. Se le puede contactar en el correo electrónico: isabelm.martinez@um.es
Enric Serradell-López es Profesor de los Estudios de Economía y Empresa de la Universidad Oberta de Cataluña. Se le puede contactar en el correo electrónico: eserradell@uoc.edu
| Find other papers on this subject | ||
© the authors, 2011. Last updated: 26 November, 2011 |
|
