The socio-technical design of a library and information science collaboratory
Monica Lassi
Swedish School of Library & Information Science, University of Borås, Allégatan 1, SE-501 90 Borås, Sweden.
Diane H. Sonnenwald
School of Information & Library Studies, University College Dublin. Belfield, Dublin 4, Ireland.
Introduction
This paper presents and discusses employing use cases as a design method for socio-technical design. The system for which the socio-technical design has been employed is a prototype collaboratory whose aim is to help researchers, students and professionals in a social science discipline, namely library and information science, share research data collection instruments.
A collaboratory, or virtual research environment, is 'a network-based facility and organizational entity that spans distance, supports rich and recurring human interaction oriented to a common research area, fosters contact between researchers who are both known and unknown to each other, and provides access to data sources, artefacts and tools required to accomplish research tasks'(Science of Collaboratories 2003). Examples of data collection instruments that could be shared through a collaboratory include interview guides, questionnaires, and software for logging Website usage. We propose that sharing data collection instruments may improve the quality and breadth of research within a discipline, enabling students to replicate previous studies in meaningful ways, reducing the time needed to conduct some types of research through re-use of data collection instruments, and facilitating larger scale and/or longitudinal comparison studies. This could facilitate advances in both research and practice.
Collaboratories have a social dimension: resources are created and shared based on research and social practices prevalent in the collaboratory's user community, and based on available technology. Therefore to design a collaboratory we employed a socio-technical approach, investigating both information technology and social practices, and the interplay among them. The socio-technical design features emerged from a synthesis of relevant research literature (Lassi and Sonnenwald 2010), and an empirical study in which library and information science researchers, students and professionals were interviewed to discover needs, opportunities, and barriers for sharing data collection instruments in our discipline. The socio-technical design features were refined through use cases, i.e., scenarios of interaction (Cockburn 2001). The design features developed include: re-use of data collection instruments; rewards for contributing to the collaboratory; interaction among members; global accessibility for students, professionals and researchers; protection of members' intellectual property; and, facilitation of learning about research methods and data collection instruments. The results of the design process is a prototype collaboratory implemented in the MediaWiki wiki software.
The following definitions apply through the paper. A design feature is defined as 'A distinguishing characteristic of a system item (includes both functional and nonfunctional attributes such as performance and reusability' (IEEE 2008: 10). A design requirement is defined as 'Documentation of the essential requirements (functions, performance, design constraints, and attributes) of the software and its external interfaces' (IEEE 2008: 10). Design requirements are typically derived from design features, and provide more detail regarding a system.
We first present overviews of use cases as a design method, and the role of wikis for information sharing. We next describe our design approach, and present seven use cases that describe the prototype collaboratory. These include:
- Joining the collaboratory and creating a research profile;
- Sharing a data collection instrument;
- Finding a data collection instrument;
- Posting a comment or question about a data collection instrument;
- Creating a new version of a data collection instrument;
- Volunteering to become a reviewer;
- Providing a recommendation letter for collaboratory member.
Finally, we discuss the limitations of the study and conclude with a discussion on our findings and future research.
Relevant research
Use cases as design tools
A strong tradition in software design is the use of formalized design requirements that describe the concrete actions of the system in question (for example, that the click of a button will result in a query being sent to a database). Design requirements can be said to be 'embedded within the use case's textual description, making use cases a container for the requirements' (Daniels and Bahill 2004: 318).
Use cases can be used to discover, analyse, refine, and evaluate system design requirements (see for example Cockburn 2001). Use cases focus on the interaction between the human actor and the system on a more abstract level (for example, by using narratives), which allows for flexibility of implementation. That is, use cases are based on proposed future scenarios of interactions between human actors and systems. Kamalrudin et al. (2010: 256) suggest that use cases facilitate 'alternative designs, such as using biometrics as an identification method, that still meet the "essential" requirements'.
Use cases proposing future scenarios of interactions have been used successfully in design for almost two decades (see for example Jacobson et al. 1992). Future scenarios of interactions can be generated using an empirically-driven or an analytically-driven approach to scenario design (Carroll and Rosson 1992). An empirical approach, i.e., gathering data about users' interactions with a system, presupposes an implemented system, and often generates data in amounts that may be difficult to analyse. An analytic approach, i.e., developing theories of possible scenarios of use, can be used at an earlier stage of the design process, and limits the amount of data generated in the scenario design process. (Carroll and Rosson 1992) We have taken an analytic approach to scenario design at this stage of this research.
When first formulated by Jacobson and colleagues (1992), the structure of use cases was quite open and flexible. Since then, many efforts have been made to formalize use cases (Hurlbut 1997), often motivated by a sense that the lack of formality allows for ambiguity (Sinnig et al. 2010). In a survey of use case approaches Hurlbut (1997) identified thirty-one approaches to constructing use cases, ranging from open-ended narrative approaches to formalized approaches.
Use cases written as narratives in prose (natural language) function as containers of design requirements which 'can be extracted from a use case's narrative' (Daniels and Bahill 2004: 318). This type of narrative scenario has been called a 'narrative theory of the artifact in use' (Carroll and Rosson 1992: 190). Narratives written in prose are potentially more accessible to design teams, clients, and intended users (Lilly 1999, 2000; Sinnig et al. 2010). However, narratives are criticized for allowing ambiguity and for being difficult to use immediately as formal design requirements (Sinnig et al. 2010). They may also incorporate technical terminology that is difficult to understand in general and which helps to pre-determine solutions and 'reduce the scope of innovation in system design' (Jagielska et al. 2006: 92).
To address the challenges with using narratives and natural language Kamalrudin et al. (2010) are conducting research to automatically extract the essential parts of a narrative use case to form what they call essential use cases. They argue for the importance of the rich information inherent in natural language narratives, building upon the findings of Jagielska et al. (2006) who showed that it is difficult to separate the design of use cases from the more traditional computing mindset and vocabulary. Daniels and Bahill (2004) provide a middle ground on narratives: they attempt to employ a hybrid method of generating design requirements from use cases and shall-statement requirements.In this study we have combined formal use case descriptions with narratives to capture the strengths of formalism as well as prose. The formal parts of the use cases provide structured guidance to the design process. The narratives allow for creativity in the design process, as well as increased accessibility for readers who are not accustomed to computer technology vocabularies.
Wikis for information sharing
A wiki is a Website that allows its users to contribute to it by adding and modifying content. The first wiki, the Portland Pattern Repository, later called the WikiWikiWeb, was introduced in 1995 by Ward Cunningham to support a software development community (Leuf and Cunningham 2001). Today, wikis are used for many different purposes: to organize communities of practice; to share resources; for collaborative projects; for news reports; and as directories (Klobas 2006). The most famous and successful wiki is the online encyclopaedia Wikipedia (Bryant et al. 2005). Wikipedia allows individuals to author and modify pages that are added to the Website. Most articles are open for anyone to modify content; peer review of articles is handled by the community of Wikipedia editors.
Black (2008) proposes that academia adopt and use wikis widely. Because wiki content is peer reviewed, i.e., the community using the wiki can edit and discuss the content, there is a good fit with the academic peer review model and practice. Black (2008: 80) goes further, suggesting that using a wiki could 'effectively move the peer-review forum out from behind closed doors into the public arena'. Currently editors and associate editors select a handful of academics to review submissions. Using a wiki could allow more academics, and when appropriate the public, to review a submission and to post comments on the submission over time. Hoffmann (2008) argues that the research community needs to collaboratively transfer the quality control that peer review is considered to be into wikis, which are a novel form of research dissemination arena in that authors and reviewers alike can work together to ensure the quality of posts. Black (2008) also points to the time factor: the dissemination of research could be much quicker if published in a wiki compared to going through a traditional peer review process used for conferences and journals.
An issue with the use of wikis in academia is recognition for contributors (Black 2008). A solution to this problem has been implemented in WikiGenes, a wiki for the life sciences that collects information about genes, chemicals and diseases (Hoffmann 2008). WikiGenes uses the authorship tracking technology, Mememoir, to provide detailed attribution to authors by linking each word to the author. Mememoir is an attempt to implement a social practice, i.e., the importance of attributions in research, in the technical framework of social media and wikis in particular (Hoffmann 2008).
Both the thought experiment of Black (2008) and the wiki implementation by Hoffmann (2008) argue for wikis as a viable arena for sharing research information and facilitating scientific debate and conversation among academics. Debates and conversations can be useful for experts as well as students or newcomers to a discipline. Weaknesses in wikis, such as lack of author attribution mechanisms, are being addressed through new tools such as Mememoir.
Our prototype collaboratory was implemented using MediaWiki wiki software which is freely available under the GNU General Public License (GNU 2007). Media Wiki has been used to implement a variety of wikis, including Wikipedia, the wiki dictionary Wiktionary, and Wikia which hosts wikis on several topics, including gaming and entertainment. MediaWiki is an open source initiative and many people contribute to its development.
MediaWiki allows considerable flexibility in developing and customizing a wiki. There is a vast set of extensions, contributed by the open source community, which can be used to customize a wiki. For example at the beginning of August 2011, there were 1913 available extensions (Mediawiki 2009), and this number grows continuously. This gives the potential to further develop our prototype collaboratory in the future.
A potential challenge using MediaWiki is that it requires users to use wiki mark-up, as a WYSIWYG (What You See Is What You Get) user interface has been lacking. A WYSIWYG user interface in a wiki would allow users to format content in a similar fashion as when using a text editing software, e.g., highlighting text and clicking a button to format text as bold or italics. Other open source wiki software packages offer WYSIWYG (e.g., MindTouch), but lack the necessary flexible customization opportunities that MediaWiki offers.
Design approach
The socio-technical design of the prototype collaboratory emerged from three activities: a review of relevant research literature (Lassi and Sonnenwald 2010); an empirical study with library and information science researchers, students and professionals; and use case development.
In the literature review, a synthesis of literature from the areas of scientific collaboration, scholarly communication, scientific disciplines, invisible colleges, and virtual communities was conducted. The result of the synthesis is a taxonomy that provides a concise overview of explanatory factors concerning adoption and use of collaboratories. The taxonomy includes six types of factors that appear to impact the design and use of a scientific collaboratory. These are factors related to: the progress of science (including career as well as disciplinary and scientific development factors); social aspects of science (including personal and community factors); and economic aspects of science (including cost of participation and cost to develop and sustain factors). Facilitators and benefits with respect to the adoption and use of a scientific collaboratory are presented in Table 1.
| Types of factors | Facilitators and benefits |
|---|---|
| Career |
* Prestige of belonging to a community * Understanding and mastering the culture and language * The academic reward system: citations, acknowledgements, usage statistics; co-authorship leads to more citations for longer periods of time * Increased efficiency by using existing resources * Learning from colleagues' work |
| Personal> |
* Belonging to, and supporting a community * Prestige of being a member of a community * Learning opportunities * Getting recognition through usage statistics, download statistics etc * Having fun |
| Cost of participation | * Understanding and mastering the culture and language |
| Disciplinary and scientific advancement | * Discipline characteristics: collaboration readiness; collaboration infrastructure readiness; collaboration technology readiness; high degree of mutual dependence; low degree of task-uncertainty * Vision of a better world, solving important problems * Increased quality of research: reliability, validity, credibility * Faster advancements - new results published faster * Diversity among scientists can lead to new developments: new branches of science; new models of science; conceptual revolutions * Funding agencies encouraging collaboration * Learning opportunities for students and junior researchers |
| Community |
* Members feeling a sense of belonging to the community, and wanting to support it: reciprocity, gift-giving * Members understanding and mastering the culture and language * Establishing a critical mass of active users * Trust amongst community members |
| Cost to develop and sustain | * Economic issues solved, such as who provides for development and maintenance |
Concerns with respect to the adoption and use of a scientific collaboratory are presented in Table 2.
| Types of Factors | Concerns |
|---|---|
| Career |
* The academic reward system: low prestige in using other researchers' resources; recognition only to first author in citation analyses * Not getting credit when others use your resources * Competition - others may use your resources and publish before you do |
| Cost of participation |
* Economic costs, such as: equipment, operating systems, software, Internet connection) * Contribution barriers, such as: complex procedures for sharing; few supported file types; complex and exhaustive metadata schemes |
| Community | * Too many passive members (lurkers) compared to active members |
| Cost to develop and sustain |
* Development costs, such as requirement analysis * Hardware and software costs * Salaries for staff and developers * Recruiting a critical mass of members |
The empirical study investigated the needs, opportunities and barriers for sharing digital data collection instruments in the library and information science community. Purposeful sampling (Miles&Huberman 1994) was employed to ensure a broad range of experience and expertise among the study participants. A total of sixteen semi-structured interviews were conducted with information professionals, master students, Ph.D. students, researchers, and senior researchers. Each participant had different research experiences and expertise regarding data collection techniques. The study participants were American, Australian, Canadian, Swedish and Taiwanese. The interview data were analysed using open and axial coding (Robson 2002). Six themes emerged from the data analysis: access to research instruments; rewards for contributing; ensuring quality; the role of the social network; time and effort; and sustaining a collaboratory.
As discussed, the use cases in this paper have been generated using an analytic approach (Carroll and Rosson 1992) building upon the results of the activities described above. The use cases highlight potential ways that individuals could interact with the collaboratory to facilitate their research and learning. We have worked with formalized condition statements as well as with narratives to make visible important design features. The formal portions of the use cases capture important aspects such as success and fail conditions, actors, and triggers. The narratives describe the human-system interaction in prose. We have taken care to avoid systems development jargon, following the results and recommendations of Jagielska and colleagues (2006). In the section Collaboratory design we present the prototype collaboratory design as use cases. The actors in these use cases are collaboratory members, regardless of the user group they belong to. As discussed, the use cases in this paper have been generated using an analytic approach (Carroll and Rosson 1992) building upon the results of the activities described above. The use cases highlight potential ways that individuals could interact with the collaboratory to facilitate their research and learning. We have worked with formalized condition statements as well as with narratives to make visible important design features. The formal portions of the use cases capture important aspects such as success and fail conditions, actors, and triggers. The narratives describe the human-system interaction in prose. We have taken care to avoid systems development jargon, following the results and recommendations of Jagielska and colleagues (2006). In the section Collaboratory design we present the prototype collaboratory design as use cases. The actors in these use cases are collaboratory members, regardless of the user group they belong to.
The MediaWiki software was chosen to implement a prototype collaboratory. MediaWiki runs on a server and uses a MySQL database for data storage (Mediawiki 2009). Communication with the server for handling processes and displaying data in different ways is handled by PHP (Lerdorf et al. 2006). The prototype collaboratory can be used with most Web browsers and does not require any equipment other than an Internet connection. It can be accessed from any geographic location in the world. This is in line with lessons learned from collaboratories in other disciplines, which indicate that a flexible system that does not require any special equipment, hardware, operative systems or other software are more likely to be used (Finholt 2002).
Collaboratory design
As discussed, the overall goal of the collaboratory is to facilitate the sharing of research data collection instruments across geographic distances, organizations and professional roles within information and library science. We propose that sharing data collection instruments among practitioners, researchers and students may enhance the quality and breadth of research, enabling replication of previous studies in meaningful ways, reducing the time needed to conduct some types of research through re-use of data collection instruments, and facilitating larger scale and/or longitudinal comparison studies. Examples of data collection instruments that could be shared include interview guides, questionnaires, and software for logging Website usage.
The main page of the prototype collaboratory is found in Figure 1. The two most prominent activities, sharing and finding data collection instruments, are the focus of the main page. Boxes listing the latest uploads, most downloaded, and latest comments are displayed to members upon login. Dynamic elements such as these could motivate members to log in frequently, to check what has been added recently and which data collection instruments members are showing particular interest in.
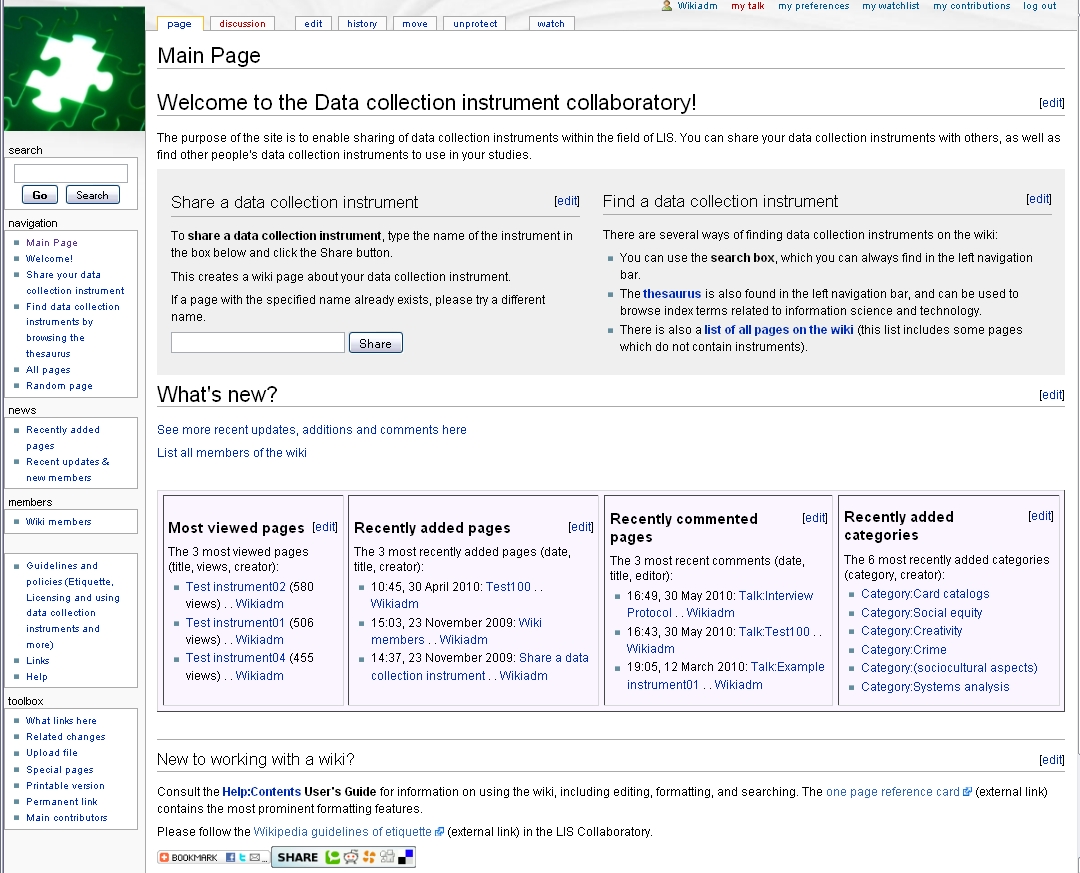
The collaboratory design is presented as seven use cases described formally as well as narratively. In the context of use cases, the term extension has a different meaning than that found in the MediaWiki software. In use cases, extensions are understood as alternative interaction steps in the use case, as opposed to mandatory steps.
Use case 1: Joining the collaboratory and creating a collaboratory profile
To start using the collaboratory, a new member needs to create an account and a member profile that is visible to other members. The member profile includes some required information such as the member's name, affiliations, and contact information. More information such as a personal presentation and links to personal Web pages, can be added if the member wishes.
This use case consists of three steps, one of them having extensions to capture alternative interactions. The potential ways for the actor to interact with the collaboratory in connection with each step are presented below.
- Goal: to join the collaboratory and create a member profile.
- Actor: a person who wants to become a member of the collaboratory.
- Success condition: t actor has joined the collaboratory and created a member profile.
- Failure conditions: the actor has not been able to join the collaboratory or create a member profile.
- Trigger: the actor wants to gain access to what the collaboratory has to offer in terms of data collection instruments and social features.
- Note: the collaboratory has been designed for library and information science, but anyone with relevant research interests is welcome to join the collaboratory.
Step 1) The actor accesses the collaboratory's home page and is met by a notification that they need to become a member to access and use the collaboratory.
The prototype collaboratory requires members to sign in before using the system to share and find data collection instruments. This is to increase the chances that the person sharing a data collection instrument is the person who created it, and to facilitate communication between members, such as notifying a creator that a question has been posted about their data collection instrument, or that it has been downloaded.
Step 2) The actor chooses to become a member and creates a member profile.
The members choose how elaborate they want their profiles to be, submitting only the required information or adding more information. The profile can be updated at any time to revise and add information.
Step 2a) The actor fills in the required information.
When joining the collaboratory, the required information is name, contact information, research interests, and place of work or education.
Step 2b) The actor fills in additional information.
Voluntary information includes name and contact information of employer, advisor or other relevant contact (see Use case 7: Providing a recommendation letter for collaboratory member).
Step 3) The actor is notified that they have successfully joined the collaboratory.
Upon submitting the member profile information, a welcome message is displayed on screen and sent via e-mail to the contact information given in the collaboratory profile. The new member receives information about how to make the most of the collaboratory: how to use a wiki and wiki mark-up, and guidelines for sharing, finding, and using the collaboratory's data collection instruments.
Use case 2: Sharing a data collection instrument
In this use case the goal of the actor is to describe and submit a data collection instrument to the collaboratory. A challenge is enforcing the rule that members can only share data collection instruments that they themselves have created or have explicit permission from a creator to share.
The use case consists of four steps, two of them having extensions to capture alternative interactions. The potential ways for the actor to interact with the collaboratory in connection with each step are presented below.
- Goal: To submit a data collection instrument to the collaboratory by uploading a data collection instrument and creating a page for annotating the data collection instrument.
- Actor: a collaboratory member.
- Precondition: tThe actor is logged on to the collaboratory.
- Success condition: the actor has shared and annotated their data collection instrument.
- Failure condition: the actor has not successfully shared and annotated their data collection instrument.
- Trigger: the actor wants to share their data collection instrument in the collaboratory.
- Notes: only data collection instruments owned by the actor may be shared in the collaboratory, with the exception of having permission from the creator of the data collection instrument.
Step 1) The actor is presented with the option to share a data collection instrument directly after logging in to the collaboratory and chooses to go forward with this option.
Sharing data collection instruments is one of the core activities in the collaboratory. Therefore, this activity is clearly visible on the collaboratory main page as a box in which the actor can input a name of the data collection instrument to be shared (see Figure 1). Each data collection instrument requires a unique name. If a suggested name is already in use, the actor has to suggest another name.
Having submitted a name for the data collection instrument, the actor is directed to a page that can be used to describe the data collection instrument.
Step 2) The actor annotates the data collection instrument by applying metadata.
The actor can modify, add or remove metadata tags and content as she/he sees fit. The purpose of the metadata is to help others searching for data collection instruments to more easily find those instruments that best meet their needs. The page for describing the data collection instrument contains an editing box for adding (and correcting) information about the instrument. A guide on how to edit a wiki page is placed above the editing box as an aid for those who are new to working with wikis.
The editing box is pre-populated with suggestions for metadata to use in annotating the data collection instrument. The pre-populated metadata categories are: Creator; Type of data collection instrument (e.g., questionnaire, interview protocol, logging software); Information about the study (research topic, purpose of study, results); How the data collection instrument has been used (data collection method, study participant selection, reflections regarding the data collection instrument's quality, e.g., validity and reliability); Data analysis techniques used; Links to publications; Intellectual property attribution; and Link to data collection instrument file. The annotation can be modified at any time to incorporate any new information that might be relevant for collaboratory members contemplating using the data collection instrument.
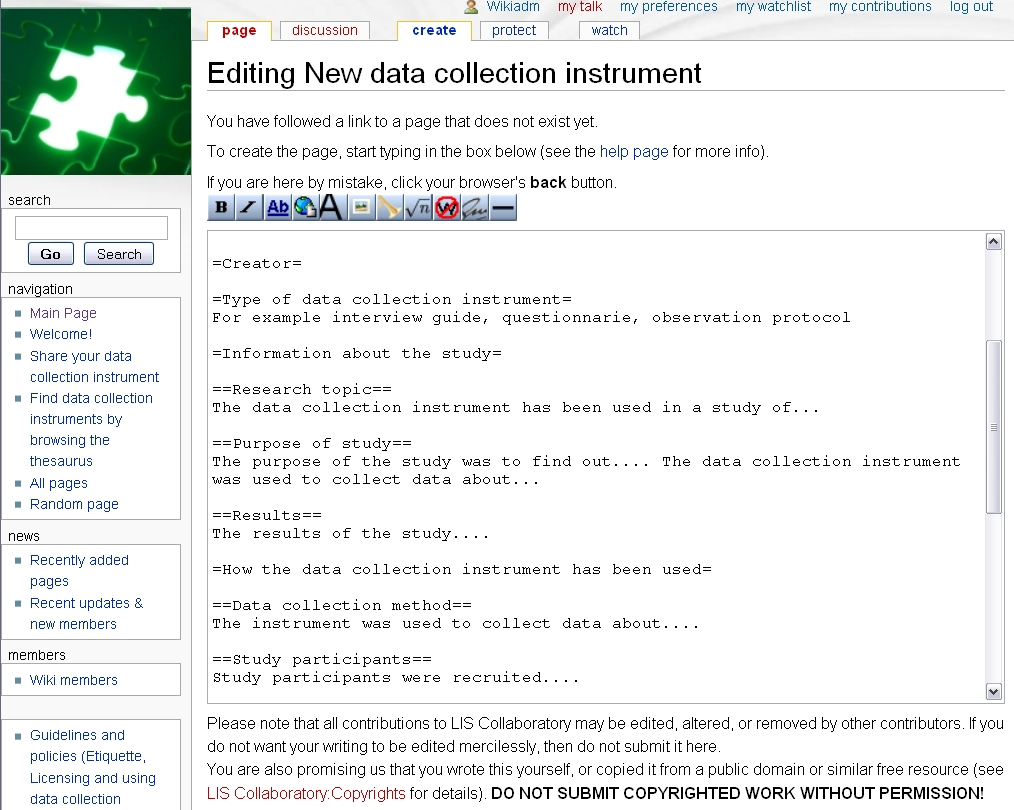
The actor may also add keywords to the description of the data collection instrument to increase the possibilities of others finding it. The keywords can be chosen from the collaboratory thesaurus, be assigned freely by the actor, or be a combination of the two. Using terms from the thesaurus will create a link between the data collection instrument and the thesaurus. This enables finding the data collection instrument by browsing the thesaurus, as well as by searching. Terms that are not included in the thesaurus are searchable but not supported in browsing the thesaurus. Terms that are not in the thesaurus may be added as they become highly used.
Branching action 2a) The proposed name of the data collection instrument is taken. The actor conducts a search to verify that another potential name is not yet taken.
Step 3) The actor provides intellectual property information for future use of the data collection instrument.
The actor can select an intellectual property license to specify restrictions and privileges for their data collection instruments. Guidelines for different types of licensing, including copyright, Science Commons and Creative Commons licenses, are provided in the prototype. The actor specifies a license by selecting or typing it next to the 'Intellectual property' heading in the editing box.
Step 4) The actor makes the data collection instrument available.
This can be achieved by uploading a file to the collaboratory, or by linking to an external source.
Step 4a) The actor makes the data collection instrument available in the collaboratory.
The actor can upload a file containing the data collection instrument using the File upload page and link to it from the data collection instrument page. File types that are currently allowed include txt, pdf, doc, gif, and jpg. Other supported file types can be added on request.
Step 4b) The actor makes the data collection instrument available at an external source.
The actor can link to a file containing the data collection instrument at a resource outside of the collaboratory. This could be used if the instrument is a software program that the actor wishes to disseminate via their own Website.
Use case 3: Finding a data collection instrument
Collaboratory members can find data collection instruments by using the MediaWiki search feature and by browsing and searching the collaboratory's thesaurus. The thesaurus used in the prototype collaboratory is the ASIS&T Thesaurus of Information Science, Technology, and Librarianship (Redmond-Neal et al. 2005). This use case describes how an actor can find a data collection instrument using the thesaurus. It consists of five steps, with variations for interaction between the actor and the creator of a potentially interesting data collection instrument.
- Goal: to find a data collection instrument that the actor finds relevant to their needs.
- Actor: a collaboratory member.
- Precondition: the actor is logged on to the collaboratory.
- Success condition: the actor has found a data collection instrument in the collaboratory.
- Failure condition: the actor has not been able to find a relevant data collection instrument in the collaboratory.
- Trigger: The actor wants to find a data collection instrument to use and turns to the thesaurus to browse categories of data collection instruments.
Step 1) The actor scans the top categories of the thesaurus and finds a suitable category to follow further.
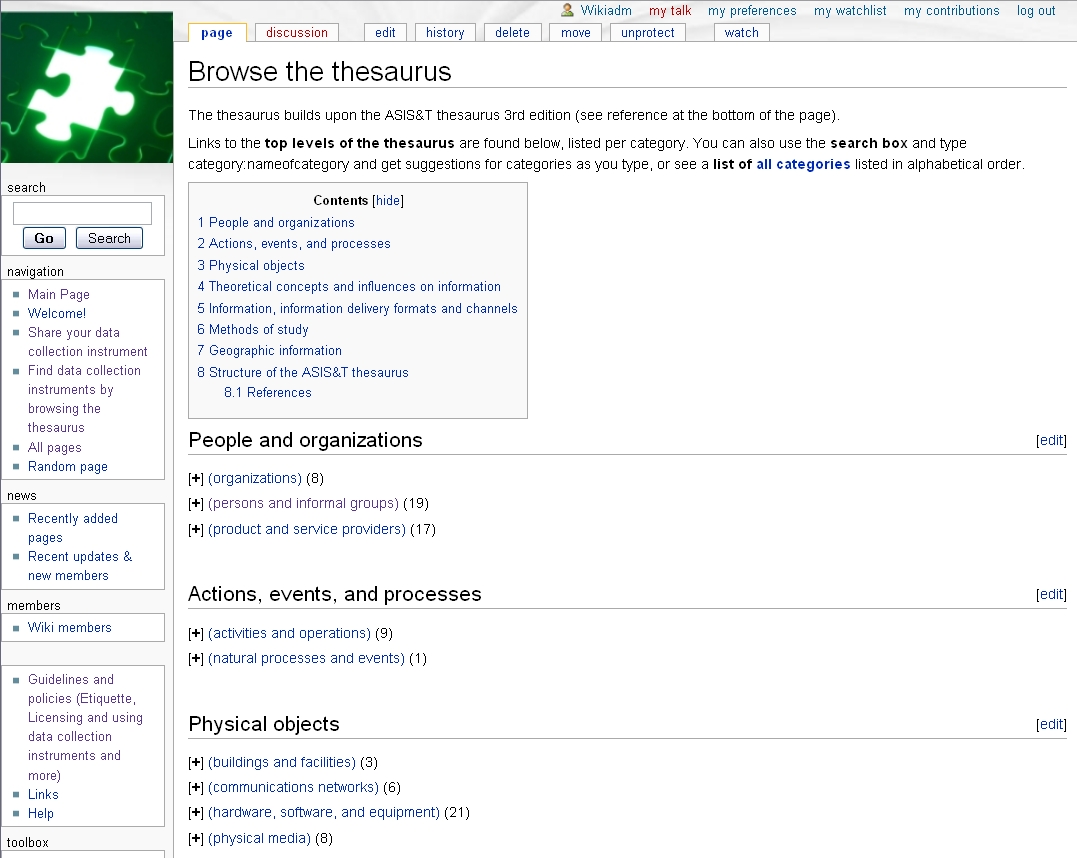
The thesaurus contains seven high-level categories: people and organizations; actions, events, and processes; physical objects; theoretical concepts and influences on information; information, information delivery formats and channels; methods of study; and geographic information (Redmond-Neal et al. 2005). The actor selects one of these categories to begin browsing the thesaurus.
Step 2) The actor browses the thesaurus until they find a category that matches their needs, and gets a list of data collection instruments that belong to the particular category.
The thesaurus allows browsing through a tree structure (see Figure 3). The numbers in parenthesis after each item in Figure 3 indicate the number of data collection instruments that have been described with that particular descriptor. To expand a category in order to see more specialized terms, the actor clicks the plus sign next to a term. A list of the data collection instruments described with that term is presented.
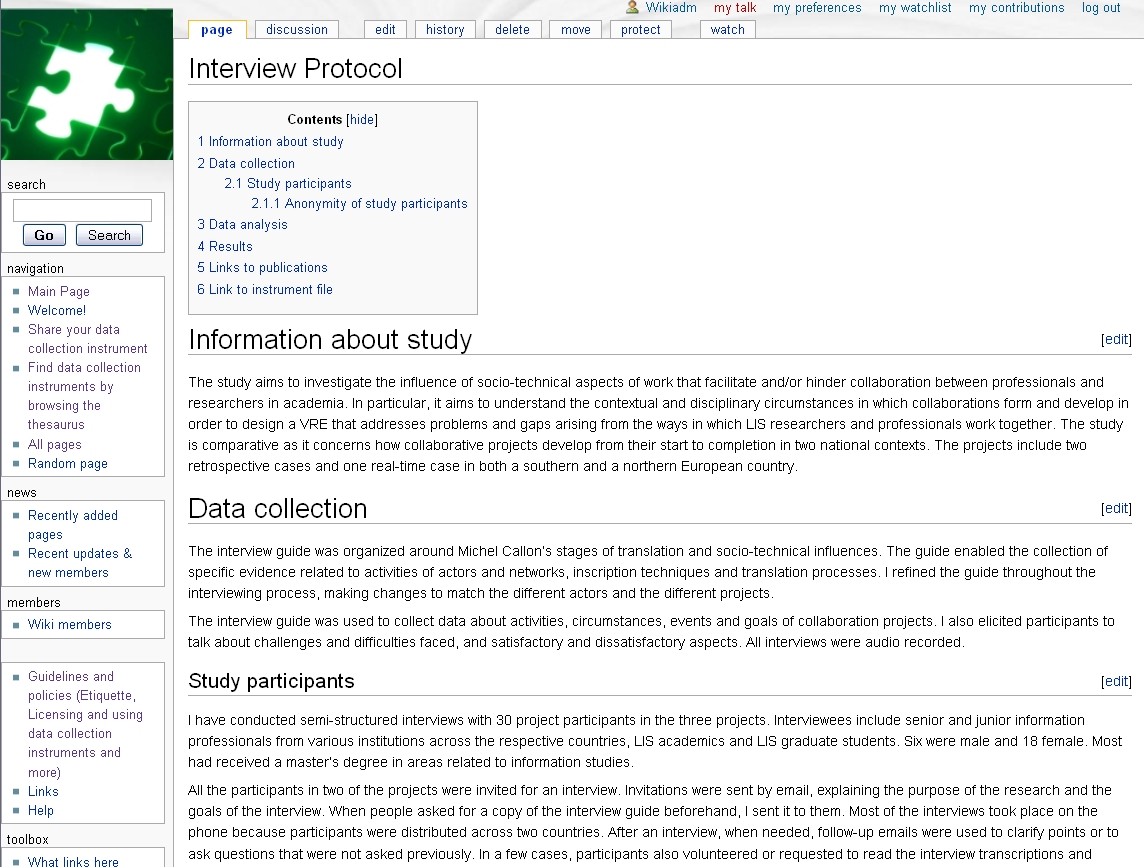
Step 3) The actor reads about the data collection instruments that are of potential interest.
The actor can read about each data collection instrument in the chosen category by clicking the name of the instrument. As described in the use case Sharing a data collection instrument, information about data collection instruments may include: creator; type of data collection instrument; information about the study (research topic, purpose of study, results); how the data collection instrument has been used (data collection method, study participants, validity, reliability); data analysis techniques used; links to publications; intellectual property attribution; and link to data collection instrument file. The actor can also find relevant information about the data collection instrument among comments and questions in its discussion section. Figure 4 displays information about an interview data collection instrument.
Step 3a) The actor posts a public question or comment about the data collection instrument.
Questions and comments can be posted in the discussion section of each data collection instrument. This is described in the section Posting a comment or question about a data collection instrument.
Step 3b) The actor poses a question directly to the creator of the data collection instrument.
In their collaboratory profile, members can indicate how they would prefer to be contacted regarding their shared data collection instrument, for example via e-mail or by communicating through the collaboratory message module.
Step 4) The actor chooses to download a data collection instrument.
The actor agrees to adhere to the intellectual property license chosen by the creator of the chosen data collection instrument. In accordance with the collaboratory guidelines, the actor posts a comment in the discussion section of the data collection instrument notifying that they will use it. The actor downloads the data collection instrument.
Step 5) The actor attributes the creator of the data collection instrument according to the creator's request, and acknowledges the use of the data collection instrument in the collaboratory as well as in any publications stemming from its use.
When the actor has used the data collection instrument in their study, they leave a comment on the page of the data collection instrument stating how they have used the instrument, including details about the study it was used in, what is was used for, if and how it was modified in any way, and providing references to publications based on using the data collection instruments as per the collaboratory guidelines.
Use case 4: Posting a comment or question about a data collection instrument
Posting questions and comments in the discussion section of a data collection instrument page is a good way to start discussions among collaboratory members. Such discussions may lead to comparative studies using a common data collection instrument or to the development of a new data collection instrument in collaboration with other members. These possibilities of discussing and developing research resources in collaboration are in line with Black's (2008) suggestions that wikis can be a quick way of developing knowledge in academic disciplines. This use case consists of three steps.
- Goal: to post a comment or question about a data collection instrument in the collaboratory.
- Actor: a collaboratory member.
- Precondition: the actor is logged on to the collaboratory.
- Success condition: tThe actor has posted a question or comment about the data collection instrument.
- Failure condition: the actor has not been able to post a comment or question about the data collection instrument.
- Trigger: the actor has found an interesting data collection instrument they have questions about.
Step 1) The actor reads the description of a data collection instrument and posts a comment about it in the discussion section of the description.
Each data collection instrument page has a discussion section where questions and comments can be posted, and discussions can be held.
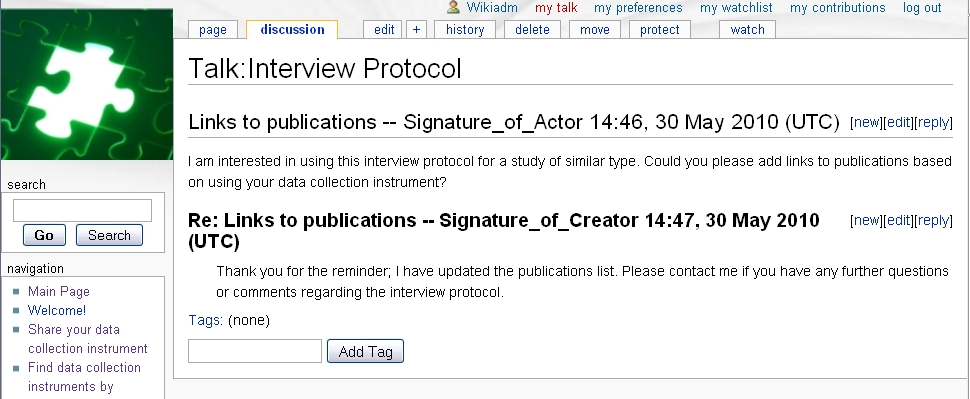
Step 2) The creator of the data collection instrument is notified that a comment or question has been posted in the discussion section.
Members can subscribe to notifications of updates or posted comments on any data collection instrument. Notifications can be sent to a member's personal inbox in the collaborator and/or to the e-mail address in their collaboratory profile. Posts are threaded so that replies and comments made to an initial post are indented. This allows for a quick reading to get an overview of the topics discussed and the question that might be of particular interest.
Step 3) The actor is notified when their question or comment has been replied to.
Similarly to step 2, the actor can choose how to get notifications about replies to comments and questions. The issue at hand might be resolved by one round of questions and answers, or the discussion may continue and engage other members as well.
Use case 5: Creating a new version of a data collection instrument
A data collection instrument designed for a particular context and group of study participants might be useful for another research study, if modified. This use case illustrates how members can create a new version of an existing data collection instrument. The use case consists of two steps and centres on communication between the actor, who wishes to modify and use a data collection instrument, and the data collection instrument's creator.
- Goal: to modify and create a new version of a data collection instrument.
- Actor: a collaboratory member.
- Preconditions: the actor is logged on to the collaboratory. A data collection instrument that partially fits the actor's needs is available in the collaboratory. The intellectual property licensing allows others to modify the data collection instrument allows for non-profit use.
- Success conditions: the actor has communicated his/her intentions to the creator of the data collection instrument, shared the modified version of the data collection instrument, given credit to, and notified the creator of the original data collection instrument.
- Failure condition: tThe actor has not shared their modified version of the data collection instrument, or has not attributed the creator of the original data collection instrument.
- Trigger: the actor decides to modify and use a data collection instrument originally created and shared by another collaboratory member.
Step 1) The actor notifies the creator of the original data collection instrument that they are considering using it in a modified version.
Notifying the creator of a data collection instrument of the intention of modifying and using it is an encouraged practice and part of the collaboratory guidelines. The collaboratory supports several ways to communicate between members, see the section Posting a comment or question about a data collection instrument.
Step 2) The actor shares their modified version of the data collection instrument in the collaboratory, attributes the creator according to chosen intellectual property license, and notifies the creator that the new version is available.
When sharing the new version, the actor follows the steps of the use case Sharing a data collection instrument, and adds the relevant metadata about the data collection instrument, including a description of how they have modified the instrument, a motivation to the modifications, and a link to the original instrument.
Use case 6: Volunteering to become a reviewer
Members can support the collaboratory in many ways. For example, they can contribute feedback on the collaboratory design; volunteer to review data collection instruments; or volunteer as an editor of the collaboratory. In this use case, volunteering to become a reviewer of data collection instruments is the success condition. There are three steps of the use case.
- Goal: to become a collaboratory reviewer.
- Actor: acollaboratory member.
- Precondition: the actor is a member of the collaboratory.
- Success condition: the actor is accepted as a collaboratory reviewer.
- Failure condition: the actor is not accepted as a collaboratory reviewer.
- Trigger: the actor wishes to become a collaboratory reviewer.
Step 1) The actor contacts the editorial board and volunteers to become a reviewer.
While the organizational structure of a library and information science collaboratory needs to be investigated further, one of the potential constituents is an editorial board with similar functions and responsibilities to boards of academic journals. The actor contacts a relevant member of the editorial board to indicate their interest in reviewing specific types of data collection instruments for the collaboratory. All data collection instruments will not go through a review process, but the ones that have been through a review process will be listed in the review section of the collaboratory.
Step 2) The actor's qualifications are evaluated by the editorial board.
Step 2a) The actor's collaboratory profile contains the information needed to evaluate the credentials.
Most of the information in members' collaboratory profiles is optional. A rich collaboratory profile, and/or links to other resource that holds additional information (e.g., LinkedIn, Academia.edu or a person's home page) could aid in the evaluation processes.
Step 2b) The editorial board asks the actor for more information.
For example research interests, academic degrees, job position, data collection instrument expertise, references to publications or reports that shows their experiences.
Step 3) The actor is notified whether they have been approved as a collaboratory reviewer.
Use case 7: Providing a recommendation letter for collaboratory member
Rewarding members who contribute to the collaboratory may be used as an incentive mechanism to encourage and recognize individuals who support the collaboratory in various ways. This makes the contributions of the collaboratory members more visible to others. In this use case, the reward mechanism is providing a recommendation letter for a collaboratory member, such as might be useful for a job application,, tenure position, or award. Other rewards include e-mailing a collaboratory member's employer stating that their contributions to the collaboratory are highly appreciated and explaining how they have contributed. These types of rewards may complement the traditional reward system of academia. This use case consists of three steps.
- Goal: to provide a recommendation letter for a collaboratory member.
- Actor: a collaboratory editor.
- Precondition: the collaboratory member has contributed to the collaboratory in a way that can be validated and is substantial enough for a recommendation letter.
- Success condition: the actor provides a recommendation letter.
- Failure condition: the actor does not provide a recommendation letter.
- Trigger: a collaboratory member asks an editor for a recommendation letter describing their contributions to the collaboratory.
Step 1) The actor is asked by a collaboratory member to provide a recommendation letter.
Contact information to the collaboratory's editorial board is linked from the main page. To optimize the process, the collaboratory member should state which type of recommendation letter they are requesting.
Step 2) The actor finds data about the collaboratory member's contributions to the collaboratory.
The actor can base the recommendation letter on the community member's profile page. Each collaboratory member has a profile page which lists their personal information and their contributions to the collaboratory.
Step 3) The actor provides the recommendation letter for the collaboratory member.
The actor sends the recommendation letter to the collaboratory member.
Limitations
The design of the prototype collaboratory presented in this paper has not yet been evaluated by actors in the context of the everyday work. Studies employing a socio-technical approach often are designed as longitudinal and iterative evaluative studies (Beaudouin-Lafon&Mackay 2003). We have conducted walkthroughs of the scenarios and prototype, and a summative evaluation will be a future endeavour of this research project. Future work is needed to ascertain the usability and utility of the collaboratory. Usability studies, and later on, surveys, usage statistics and interviews, can provide data to improve the collaboratory.
A second limitation is that the use cases are not customized for different categories of actors. The use case actors in this paper could be anyone who is a member of the collaboratory. However, data from our empirical study and related research (e.g., Finholt 2002 and Sonnenwald 2007) suggest that creating use cases for different types of actors would enhance human-system interaction. Examples of such specialized use cases include: an information professional searching for a data collection instrument to use when conducting a patron survey; and a professor searching for data collection instruments to include in teaching research methods. In the case of the patron survey, the information professional may focus on finding a data collection instrument used in a specific type of library. In the case of teaching research methods, the professor may focus on finding several data collection instruments that can be critiqued and compared based on their having a common research topic. Future research is needed to generate interfaces to explore possible requirements for different categories of users.
Conclusion
This paper has presented the design of a prototype collaboratory to support sharing of library and information science research data collection instruments across distances. The design was presented as use cases which were developed based on socio-technical design features that emerged from a literature review and synthesis, and an empirical study that included interviews with library and information science researchers, students and professionals. The use cases identify interactions between actors and the collaboratory system. They provided a mechanism to synthesize users' requests and concerns. That is, we synthesized very practical task-based requests, such as how to share and find a data collection instruments, and social concerns, such as rewards for contributing to the collaboratory, discussion among members, and protection of members' intellectual property. We propose that this synthesis is critical in creating systems that will be useful and compatible with actors' goals and values.
The synthesis was achieved using an analytic approach to scenario design (Carroll and Rosson 1992), as we developed potential future scenarios of interactions. We combined a narrative description of the interactions and formal use case elements (including goal, actor, precondition, success condition, failure condition, trigger, and task completion steps). This combination challenged and enriched each scenario. The narratives initially guided the construction of formal use case elements which, in turn, often illuminated missing or incomplete ideas presented in the narrative. Refined narratives helped to further define formal use case elements, which aided us in keeping the goals and conditions of the use cases in mind while creatively writing the narratives. This iterative process, alternating between creating narrative descriptions and formal use case elements, yielded scenarios that were more complete and robust than might otherwise had been possible, and which made implementing the prototype easier.
Since the use cases were not tightly coupled with a technology, the choice of prototype system was not predetermined and potentially limited by a particular technology. This is one of the strengths of use cases, as suggested by Kamalrudin et al. (2010). In our design process this came into play when we described the future scenarios of interaction as: The actor makes the data collection instrument available in the collaboratory, instead of an alternative: The actor uses the upload file feature of the wiki which would determine the technology of the prototype collaboratory implementation.
Furthermore, the narratives facilitated understanding of the collaboratory design for persons who are not well versed in systems development terminology and methodology. This could lead to more potential actors being able to review and critique the use cases and identify any missing interaction steps.
A limitation of using an analytic approach to scenario design as the sole design method is that the internal validity can be difficult to verify; there is uncertainty about whether all steps in the use cases have been included. This limitation can be moderated by conducting usability tests, for example different types of walkthroughs. Our use of narratives has enabled potential actors, e.g., colleagues and students, to conduct walkthroughs.
The MediaWiki software provided extensive flexibility in the implementation of the collaborator prototype; only a few of the identified design features have not been implemented (e.g., a feature to create new survey instruments by combining questions from several other surveys which could be distributed via the collaboratory has not been implemented). Further investigation is needed to determine whether available MediaWiki survey extensions are stable and secure enough for collecting research data. However, in sum MediaWiki offers a good balance between features related to repository functionality (i.e., sharing, finding, and discussing resources) and social functionality (i.e., a discussion section for each data collection instrument, and means of communication between members).
Another benefit of the MediaWiki software is that the interface is well known to many, thanks to its similarities with Wikipedia. A potential barrier for prospective members of the collaboratory could be the use of wiki mark-up, which might be difficult to use in the beginning. An intermediate solution to collaboratory members who are not used to wiki mark-up is to prepopulate a new page for describing a data collection instrument with example headings and other formatted text. Future research includes testing a WYSIWYG editor extension.
The goal of the prototype collaboratory and this paper is to put forward new ideas regarding how digital research data collection instruments could be shared among researchers of all types. We propose that sharing data collection instruments across organizations, geographic distances, research roles and time may ultimately improve research quality and quantity.
Acknowledgements
Our thanks to the study participants and to Amanda Cossham for excellent support in the copy-editing process. This research was funded by the Swedish National Graduate School of Language Technology.
About the authors
Monica Lassi is a lecturer and a Ph.D. candidate at the Swedish School of Library and Information Science. She teaches Web communication, social media
and social interaction, knowledge organization, and content management. She is conducting a Ph.D. research project on collaboration in library and information science. She is also a member of the Swedish National Graduate School of Language Technology, University of Gothenburg. She can be contacted at: monica.lassi@hb.se
Diane H. Sonnenwald is Professor, Chair of Information and Library Studies, at the School of Information and Library Studies at University College, Dublin, Ireland and an Adjunct Professor in computer science at the University of North Carolina at Chapel Hill. She conducts research on collaboration and collaboration technology in a variety of contexts, including inter-disciplinary, inter-organizational and distributed collaboration in emergency healthcare, academia and industry. She served as President of ASIS&T in 2011-2012, and is currently serving as Immediate Past President. She can be contacted at: diane.sonnenwald@gmail.com.