Incorporating nonparametric statistics into Delphi studies in library and information science
Boryung Ju and Tao Jin
School of Library and Information Science, Louisiana State University, 267 Coates Hall, Baton Rouge, LA 70803, USA
Introduction
The Delphi method is one of the best known and most frequently used qualitative research methods throughout library and information science (LIS) and other social science disciplines. As a way to forecast, identify, or prioritize issues in a given field, it is commonly used to gather opinions from a panel of experts via iterative rounds of elicitation sessions to eventually produce a collective agreement among the experts. This method enables researchers to observe how experts discuss a complex problem through a structured communication process, as well as collate divergent responses into a convergent overview (Linstone and Turoff 1975; Müller et al. 2010). One drawback of the Delphi technique, however, is the lack of standard statistical tests, which may potentially entail issues of reliability and validity (Fischer 1978; Weingand 1989).
The general goal of this article is to explore how nonparametric statistical techniques could diminish this drawback and be incorporated into LIS Delphi studies. To achieve that goal, this article contains three parts: first, a synopsis of the Delphi method and its applications in librarianship and information science; second, some of the critical issues found when employing this methodology, specifically with the integration of the nonparametric statistical approach as a remedy to the aforementioned drawback; and finally, an example study illustrating how some nonparametric statistical techniques can be incorporated into the Delphi method. We argue that such incorporation may potentially enhance the rigour of the Delphi technique and add a new tool in the arsenal of researchers.
Characteristics of the Delphi method
The Delphi method was developed in 1953 at Rand Corporation by Dalkey and Helmer (Weingand 1989). It was initially devised to 'obtain the most reliable opinion consensus of a group of experts by subjecting them to a series of questionnaires in depth interspersed with controlled opinion feedback' (Dalkey and Helmer 1963: 458). Since then, the method has been extensively used in innumerable areas; therefore, many variants exist (Linstone and Turoff 1975; Schmidt 1997). Nonetheless, they all reduce to the administration of questionnaires either in-person, by mail, by phone, or in an electronic format. Most Delphi studies also share a few distinct characteristics, such as:
- Expert input. Delphi researchers traditionally use experts as the source of information, instead of a random sample of a specified population. Experts are defined as individuals with special skills or knowledge representing mastery of a particular subject. Hence, this approach often leads to a small sample size.
- Anonymity. The Delphi technique emphasizes the gathering and generating of collective intelligence by an indirect mode of communication. The participating experts would respond to a series of questionnaires individually. While they might be known to one another, their specific responses in the process would be treated anonymously.
- Iteration with controlled feedback. The Delphi technique usually requires several rounds of systematic solicitation of expert opinions until a group census is achieved (Agha and Akhta 1992; Eldredge et al. 2009; Fischer 1978; Goodman 1987; Weingand 1989). Between rounds, participating experts receive feedback regarding the outcome of each round. Orchestrating a Delphi process requires a modest commitment by all participating experts, but a more significant obligation falls to the researchers (Yarnal et al. 2009).
- Statistical group response. Many Delphi questionnaires ask respondents to rate or rank items on Likert-type scales. Thus, the research data are mostly ordinal by nature. After each round of data collection a few basic statistics for each item, such as the median and percentage scores, can be calculated as a statistical group response. This allows respondents to see where their opinions fall in the context of the group (Goodman 1987; Reilly 1970).
Previous Delphi studies in library and information science research
In the library and informaton research field, the earliest published Delphi study can be traced back to Borko (1970) and since then the use of this technique has drastically increased. Using Library, Information Science &Technology Abstracts, we identified eighty-seven empirical Delphi research papers published between 1971 and 2011. As shown in Table 1, nearly half (49.4%) of the papers dealt with the general topic of libraries and/or librarianship. This general cluster includes subjects such as books and reading (Du 2009), cataloguing (Smiraglia 2010), electronic information resources (Kochtanek and Hein 1999; Nicholson 2003), information literacy (Saunders 2009), library administration (Maceviciute and Wilson 2009), and reference services (Pomerantaz et al. 2003). These studies involve almost all types of libraries and archives, from academic (Harer and Cole 2005) and public (Lukenbill and Immroth 2009) to medical (Eldredge et al. 2009) and law (Missingham 2011).
Following libraries and/or librarianship, the second largest cluster was management information systems, which includes business intelligence (Müller et al. 2010), supply chains (Daniel and White 2005), information resources (McFadzean et al. 2011), system security (Gonzales et al. 2006), electronic commerce (Addison 2003) and computer software development (Dhaliwal and Tung 2000). The third biggest cluster is medical informatics, where the Delphi method has been used to explore health behaviour (Brouwer et al. 2008), to appraise certain medical systems (Ambrosiadou and Goulis 1999), and to establish a controlled vocabulary for nursing practice and research (Saranto and Tallberg 2003). It should be noted that most of the authors of the papers mentioned above are from the fields of management and business, medicine and nursing, or computing and engineering. Additionally, the Delphi method has been used extensively in studies on information science (Zins 2007), knowledge management (Holsapple and Joshi 2000), information policy (Meijer 2002), and library education and professionalism (Baruchson-Arbib and Brostein 2002; Weingand 1989).
Through previous Delphi literature, we also attempted to examine the motivations behind the researchers who selected the Delphi approach as their research method. The broad purposes identified in previous research suggest that this technique can be applied in a variety of research situations. After we examined the abstracts of all these papers and extracted their purpose statements, an analysis about these statements was conducted. Five broad purposes emerged, though they are not mutually exclusive: identification; prediction; evaluation; plan or policy development and refinement; and system conceptualization, development, and implementation (Table 1). We found over one third (37%) of the papers stated that the Delphi technique was used to identify something. The objects identified could be risks, factors, attributes, indicators, needs, challenges, opportunities, limitations, uncertainties, vagueness, or any issues relevant to the research problem. The second most common purpose specified was prediction. Almost 20% of the papers aimed to forecast some kind of trend in a given domain, which echoes the tradition of the method. Baruchson-Arbib and Bronstein (2002) remarked that the method is particularly suited to research areas 'for which hard data are either insufficient or inconclusive' (Baruchson-Arbib and Brostein 2002: 399). The third major identified application of the Delphi method in the eighty-seven studies was evaluation. About 18% of the studies intended to assess certain toolkits, standards, impacts, systems, frameworks, performances, or models. The word criteria was one of the most frequently seen terms in such papers. In addition, we found the Delphi method was often adopted in various system development projects, policy analyses and planning activities.
| Publication date | Main subjects involved | Main purposes of the studies | ||||||
|---|---|---|---|---|---|---|---|---|
| Date | Freq. | % | Subject term | Freq. | % | Purpose | Freq. | % |
| 1970s | 1 | 1.15% | Libraries and/or librarianship | 43 | 49.43% | Identification | 32 | 36.78% |
| 1980s | 3 | 3.45% | Management information systems | 15 | 17.24% | Prediction | 17 | 19.54% |
| 1990s | 8 | 9.20% | Medical informatics | 9 | 10.34% | Evaluation | 16 | 18.39% |
| 2000s | 57 | 65.52% | Information science | 6 | 6.90% | Plan or policy development and refinement | 13 | 14.94% |
| 2010s | 18 | 20.69% | Information policy | 4 | 4.60% | System conceptualization, development, and implementation | 11 | 12.64% |
| Library education and professionalism | 4 | 4.60% | ||||||
| Knowledge management | 2 | 2.30% | ||||||
| Others | 4 | 4.60% | ||||||
If we examine the methods used to conduct these Delphi studies more closely, several salient observations can be summarized. To begin, most of the studies only used a small sample of experts for the survey. Depending on the research questions, the total number of invited panellists or opinion leaders (N) ranged between 10 and 50, although a few studies initially distributed their questionnaires on a larger scale (e.g., Eldredge et al. 2009, N=1,064; Maceviciute and Wilson 2009, N=125; Baruchson-Arbib and Bronstein 2002, N=120). Second, most of the studies used only two or three rounds of iteration to obtain useful information. Only a few studies conducted the iteration process to four or more rounds (e.g., Weingand 1989). However, the studies' methodology rarely provides any descriptions or justifications for determining when to move to the next round and/or stop polling. Third, very few studies systematically used statistical techniques to present and explain how the group consensus was reached. Focusing on those works written by authors affiliated with libraries or informaton schools reveals that many of studies solely employed a qualitative approach to report their results related to the consensus mechanism and did not include any standard statistical analyses (e.g., Agha and Akhtar 1992; Kochtanek and Hein 1999; Saunders 2009; Smiraglia 2010; Weingand 1989; Westbrook 1997; Zins 2007). Even those few studies which provided statistical analyses were, quite often, limited to group means, medians, standard deviations, or simply percentages of distribution (e.g., Baruchson-Arbib and Bronstein 2002; Du 2009; Feret and Marcinek 1999; Harer and Cole 2005; Zhang and Salaba 2009). This huge gap has left nonparametric statistical techniques a crucial issue to cover. It merits mentioning that Maceviciute and Wilson (2009) employed the Spearman rank correlation test in their data analysis; which may suggest that some researchers have recognized this problem, and attempted to address it.
Limitations of Delphi
There are two core limitations of the Delphi method: the vagueness of the concepts of expert and expertise; and the lack of elementary statistical analyses of data (Baruchson-Arbib and Bronstein 2002; Fischer 1978; Goodman 1987). The first limitation is directly related to the sampling procedures. Because the method relies heavily on the use of experts in gathering information, the qualifications of the experts and the quality of their input are essential in validating a given study. The researchers must develop a set of objective criteria to select experts and assess their expertise. Nevertheless, the actual selection process must still be somewhat arbitrary. The researchers are responsible for proving and justifying that the selected experts are competent and knowledgeable enough to 'yield significantly better and substantially different responses from non-experts' (Goodman 1987: 731).
The second limitation is the lack of standard statistical analyses, which arguably makes the method vulnerable to criticisms of its reliability and validity. Quite often some standard tests for statistical significance, such as standard errors of estimate and systematic correlations of items, are intentionally, or unintentionally, ignored by some Delphi researchers (Fischer 1978). Furthermore, due to its extensive applications, the Delphi method has evolved over time to include many variants. Some researchers, who justified their method as a Delphi variant, actually failed to make a sufficiently rigorous analysis, resulting in a more dramatic convergence than a strict statistical employment of the method (Goodman 1987). However, Fischer (1978) argued that '[if] Delphi is to be considered seriously as a reliable and valid method, then it must be evaluated by the same standards as other social science methodology' (Fischer 1978: 68).
Critical issues in Delphi procedures
Despite these limitations, the Delphi method is still a popular tool. Those interested in using this method in the future should consider incorporating techniques that can specifically compensate for the limitations. Moreover, these limitations raise some critical issues to consider. Correspondingly, we propose three critical aspects that need particular attention from the researchers: recruitment of experts; iteration of rounds for experts' input, and the range of identified issues and prioritization of those issues. Along with a series of techniques that researchers can use, we will elaborate each of the aspects below.
Recruitment of experts
One of the most important steps for conducting a Delphi study is to identify and solicit qualified individuals for valuable input. In their study, Okoli and Pawlowski (2004) detailed a procedure for selecting experts as follows:
- Step 1: prepare a worksheet that defines categories and knowledge levels of relevant disciplines, skills, individuals/organizations
- Step 2: populate the worksheet with names
- Step 3: contact experts and/or ask them to nominate other experts
- Step 4: rank and categorize experts based on their availability and qualification
- Step 5: invite experts according to the target panel size
The size and number of expert groups (or panels) are totally dependent on the nature of the study. Like other qualitative approaches, the Delphi method does not need to ensure the representativeness of statistic samples because this is a group decision mechanism for reaching a group consensus (Okoli and Pawlowski 2004; Ju and Pawlowski 2011). For this reason a relatively small sample size, twenty to forty-five participants per study, is justifiable, as has been shown in many previous studies (e.g., Keller 2001; Ludwig and Starr 2005; Neuman 1995; Westbrook 1997).
Iteration of rounds for experts' input
As mentioned earlier, iteration with controlled feedback is the most distinguished feature of the Delphi method. But how many rounds of solicitations would be sufficient? As Schmidt (1997) pointed out, one of the possible challenges faced by the researchers is the question of when to stop polling. Too few rounds may lead to an immature outcome, while too many rounds would require a burdensome commitment from the participating experts and the researchers conducting a Delphi study. Although no rules dictate how many rounds should be undertaken, it seems that most of the previous Delphi studies ran through two to three rounds of solicitations without additional justifications. The main issue for researchers is obtaining the most rigorous data while being considerate of the participating experts' time and efforts.
Range of identified issues and prioritization
Given the natural tendency of the Delphi to centralize opinions, an important question is how to prioritize those identified issues appropriately in each round, and, likewise, 'how many items to carry over to the subsequent rounds' (Schmidt 1997: 764). To address these questions, researchers must make many decisions. The first set of decisions should include: the number of items study participants should respond to in the initial round; if the initial questionnaire has too many items, how many of them should be carried over to the next rounds; and how can the researchers eliminate less meaningful items from the list?
As suggested previously, the primary role of iteration in the Delphi process is to achieve a high degree of consensus. This leads to yet another important decision: how to operationally define the concept of 'degree of consensus'. Few studies provided a clear definition of this notion and, in most cases, the boundaries between high and adequate agreements among the study participants were vague; different researchers used different statistical elements to represent the boundaries. Some studies used rankings and percentages of agreement or disagreement (Ludwig and Starr 2005), while others used mean ratings and standard deviations (Neuman 1995; Zhang and Salaba 2009; Westbrook 1997). Notably, the rated or ranked items in these studies represent the ordinal scale data, measurement of order (rank order), not a relative size of data. Hence, the application of standard deviation to ordinal level data does not produce a valid interpretation (Schmidt 1997; Stevens 1946). Instead, the rates of agreement using statistics such as Kendall's coefficient of concordance (W) or the standard Pearson correlation coefficient (r) could be considered to ensure the most rigorous assessment of ratings. Since most of the Delphi studies employ a small sample size, with no assumptions regarding the nature of probability distribution, using a nonparametric statistic such as Kendall's W, is a preferred method for result interpretation at each round of a Delphi study.
In order to demonstrate how the above three aspects can be addressed, a study using the ranking-type Delphi method is presented in the following section. This example will illustrate how data were collected and analysed by using nonparametric statistics, as well as the general design of the study. We hope it will provide some insights for the future application of this method.
An example study
The aim of the example study is to investigate the barriers and challenges encountered by scientists when they use information and communication technologies (information and communication technologies) (e.g. collaboration software, video conferencing, and instant messaging tools) for their distributed research collaboration activities (Ju and Pawlowski 2011). A step-by-step procedure is demonstrated.
This study addresses two research questions:
- What are the types of barriers and challenges to the use of information and communication technologies by scientists in the distributed environment of collaboration over the cyber infrastructure?
- Are there any major differences or commonalities in the barriers and challenges to the use of information and communication technologies by research domain (science and engineering vs. social and behavioural sciences)?
Selection of panel members
The identification and selection of qualified individuals is one of the most fundamental processes when conducting a Delphi study. For this study, the concept of 'expert panellists is defined as researchers who have extensive experience in communicating and collaborating with colleagues at other universities (geographically distributed) for research. Each panellist also uses at least one communication technology, such as email, telephone/Skype, Wikis, video conferencing, Listservs, instant messaging, blogs, or collaboration software suites such as SharePoint (see Appendix).
Initial panel members were identified by the investigators' personal contacts, as well as by recommendations from the investigators' colleagues in other departments at a national, research-oriented university in the United States. In order to solicit initial panel members to participate for the study, investigators explained the purpose of the study, eligibility of participants, time frame for each round, and the basic structure of the Delphi survey (Figure 1). Once experts agreed to participate, invitations went out to their collaborators at other universities or research centres. Twenty-four researchers from five research-oriented universities in four states (Florida, Georgia, Louisiana, and Ohio) were invited to participate in the Delphi survey. This was a purposeful sample using a snowball sampling method due to the availability of eligible participants.
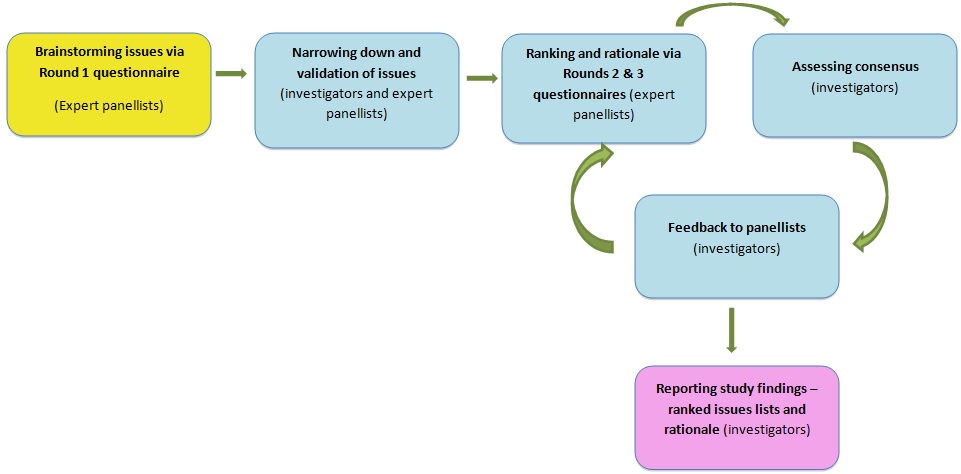
(Variation for the current study: Rounds 1 and 2 - Combined science and engioneering/social and behavioural sciences panel; Round 3 - Separate ranking by the science and engioneering panel and the social and behavioural sciences panel)
To address the research question of whether or not major differences exist in barriers and challenges experienced by scientists using information and communication technologies, two panels were structured and members were recruited. The science and engineering panel consisted of researchers from the fields of mathematics, computer science, engineering and medicine, while the social and behavioural sciences panel consisted of researchers from psychology, political science, business and geography. In total, twenty-four panellists participated in the study. All of them hold PhD degrees or higher (post-doctoral) and have experience in conducting one or more multi-site research projects by using at least one of the information and communication technologies listed above.
Data collection and analysis for each round
The online survey (e-Delphi) was administered to elicit opinions from the expert panellists throughout three rounds: Round 1 was the identification of issues by brainstorming among the panellists; Round 2 was ranking identified issues and assessing consensus among all panel members; and Round 3 was re-ranking the shortlisted issues by two different panels. The data analysis was done by following the step-wise method developed by Schmidt (1997) for the attempt to mitigate the weaknesses seen in other ranking-type Delphi approaches.
Round 1
Goal The goal of Round 1 was to identify and elicit the key issues regarding the use of information and communication technologies from the panel members.
Data collection The survey was delivered using online survey software to all twenty-four panel members. The survey asked the panellists to list as many major issues (e.g., challenges, constraints or conflicts, barriers) as possible in the use of information and communication technologies for distributed research collaboration. The issues could be of any type, such as technical, social, procedural, financial, organizational or cultural. Panellists were allowed to list issues in a bullet format or list with elaborate explanations and/or examples in order to help the investigators' understanding. Other questions in the survey included the kind of information and communication technologies they used, the size of collaboration (number of collaborators), the multi-disciplinary aspects of the research projects they engaged in, the panellists' research domain, and their name and email address for the following surveys. Additional comments were also allowed. After gathering the participation agreements from the twenty-four panellists (twelve from the science and engioneering panel and twelve from the social and behavioural sciences panel), the online survey was delivered and participants were given two weeks to return their answers. The expected time for any given respondent to complete the form was fifteen minutes. E-mail reminders were distributed once in order to boost the response rate.
Analysing responses The goal of Round 1 was to identify and elicit the key issues regarding the use of information and communication technologies from the panel members.
| Issues identified | Example input | |
|---|---|---|
| 1 | Annoyances caused by some features of tools or tool use | Annoying aspects of Skype, for example, one cannot turn off the notification that appears on the screen every time a contact comes online |
| 2 | Confidentiality concerns | Potential break of confidentiality |
| 3 | Cost of software, equipment or services | Financial or who will foot the bill |
| 4 | Data management issues - lack of centralized control | Version control for collaborators outside university or department |
| 5 | Differences in participants' preferences and choices of collaboration tools | Using the same type of collaboration technologies (e.g. some use Skype, WebEx, Yahoo) |
| 6 | Differential levels of competence or experience with technologies | Varying levels of technological savvy among collaborators |
| 7 | Difficulty capturing and maintaining online meeting proceedings and other data about collaborative activities | Ability to record, playback or summarize |
| 8 | Difficulties facilitating and making contributions to online group discussion | Facilitating the raising and expression of questions by remote audiences remains tough |
| 9 | Discomfort of some individuals related to mediated communication (affective states, styles of work, etc.) | 'I don't think everyone is comfortable with viewing people or having people view oneself on screen (e.g. videoconferencing, Skype)...creating an unbalanced group from the standpoint of affective state.' |
| 10 | Technology-mediated communication is less effective or productive (vs. in-person, face-to-face communication) | 'Very few information and communication technologies can replace face-to-face communication, even if we see each other. I don't believe we behave the same way when communicating through information and communication technologies as we would face-to-face.' |
Round 2
Goal The goal of Round 2 was to rank issues and assess consensus from all panel members.
Data collection The survey questionnaire presented to the panel members consisted of the twenty-seven-issue list with a short definition or explanation of each item, a glossary of terminologies used in the study, and a copy of their responses to the first round questionnaire. According to Schmidt (1997), ranking around twenty items is considered reasonable at an early stage of Delphi. In this round, each panellist was asked to rank the listed items by importance, where one equalled the most important and twenty-seven the least. No two items were allowed the same ranking. A time frame of two weeks was given, and fourteen out of twenty-four panellists returned their responses.
Analysing responses The rankings provided by the fourteen panellists were recorded, and the mean ranks were calculated for each item. Table 3 shows the list of items with mean rank, variance of rank (D2), Kendall's W, and chi-squared (χ2). From this table, items on the top in the mean rank column are rated important by panellists. As seen in the table, there is no obvious top group of items in terms of mean ranking, and the investigators had a difficult time setting a cut-off point. To assess the group consensus, Kendall's W was calculated and a low level of agreement (W = 0.103) was found. In the nonparametric statistical approach, a strong agreement or consensus exists for W>= 0.7; a moderate agreement for W= 0.5; and a weak agreement for W< 0.3 (Garcia-Crespo et al. 2010). This was somewhat expected considering that individual panellists come from a variety of research domains, and used different tasks and tools. This assumption prompted the investigators to consider the association, if any, between the two research domains (science and engioneering vs. social and behavioural sciences). As indicated in the previous studies (Kendall and Gibbons, 1990; Schmidt 1997) Kendall's T (rank order correlation coefficient) can be used to find the agreement between two groups. In this case, our calculation for T resulted in -0.009 (approximately zero), which means that there was no association between the two groups' rankings. Consequently, the investigators decided to separate the full panel into two independent groups for the next round of data collection. By calculating the differences between the mean rank and the grand means, variance of rank was measured to assess how each item was dispersed. Chi-squared values were also calculated to demonstrate the level of association between the issues and ranks; this relationship was found statistically significant.
| Issue number | Mean rank | D2 |
|---|---|---|
| 26 | 7.64 | 40.45 |
| 25 | 10.57 | 11.76 |
| 10 | 11.18 | 7.95 |
| 27 | 11.64 | 5.57 |
| 20 | 11.71 | 5.24 |
| 3 | 11.93 | 4.28 |
| 23 | 12.14 | 3.46 |
| 8 | 12.36 | 2.69 |
| 1 | 12.71 | 1.66 |
| 6 | 12.86 | 1.3 |
| 24 | 12.89 | 1.23 |
| 13 | 13.25 | 0.56 |
| 9 | 13.36 | 0.41 |
| 5 | 13.57 | 0.18 |
| 11 | 13.86 | 0.02 |
| 14 | 14.82 | 0.67 |
| 21 | 15.57 | 2.46 |
| 19 | 15.64 | 2.69 |
| 12 | 15.68 | 2.82 |
| 18 | 15.89 | 3.57 |
| 17 | 15.93 | 3.72 |
| 22 | 15.93 | 3.72 |
| 16 | 16.04 | 4.16 |
| 15 | 16.5 | 6.25 |
| 7 | 16.96 | 8.76 |
| 4 | 18.5 | 20.25 |
| 2 | 18.86 | 23.62 |
| Totals | 377.99 | 169.5 |
| Grand means | 14.00 | |
| W | χ2 | |
| 0.103 | 37.657 |
Round 3
[Goal] The goal of Round 3 was to re-rank issues and examine the differences by research domains.
[Data collection] In this round, the investigators decided to reduce the number of items to be ranked from twenty-seven to fourteen. Based on the mean ranks for each item we produced a list of fourteen items with mean ranks for each and item descriptions in the order of importance, rather than a random or alphabetical order. As a result, two different lists of items were sent to the two groups/panels (science and engioneering and social and behavioural sciences groups) separately. The panellists were again asked to rank these issues by importance. Seventeen panellists (nine from the science and engioneering panel and eight from social and behavioural sciences panel) returned their responses.
[Analysing responses] The most important fourteen items were decided based on the mean ranks (mean rank <13.5). The decision of the cut-off point was made by the investigators considering the wide gaps in mean ranking. This was a natural 'breaking point' which halved the original number of twenty-seven. Then Kendall's W was calculated separately for each panel. As a result, Kendall's W for the science and engioneering panel was 0.207, and 0.120 for the social and behavioural sciences panel. They were slightly higher than the previous round but still in the lower range.
Presentation of findings
The findings of a Delphi study can be presented in any format: list of items, categories or tables with related statistics or narratives. Table 4 lists the final findings of the example study, which includes fourteen top issues that were identified by the science and engioneering and social and behavioural sciences panels respectively. The items are ranked in descending order by their final mean ranks.
| science and engioneering GROUP | social and behavioural sciences GROUP | ||||
|---|---|---|---|---|---|
| Issue # | Issue | Issue Type | Issue # | Issue | Issue Type |
| 20 | Quality issues (audio/video) | Tool or technology | 24 | Time or effort to learn | Individual |
| 25* | Unreliability of technology | Tool or technology | 6* | Differential competence or experience | Individual |
| 26* | Usability issues | Tool or technology | 27* | Variance in tool availability | Resources |
| 23 | Technology infrastructure limitations | Tool or technology | 25* | Unreliability of technology | Tool or technology |
| 16 | Limitations of collaboration tools | Tool or technology | 8 | Difficulties facilitating or contributing | Collaboration process |
| 11 | Incompatibility of technologies | Tool or echnology | 26* | Usability issues | Tool or technology |
| 6* | Differential competence or experience | Individual | 10* | Information technology-mediated communication less effective | Collaboration process |
| 1 | Annoyances - tools | Tool or technology | 3* | Cost | Resources |
| 27* | Variance in tool availability | Resources | 19 | Negative impact on motivation | Collaboration process |
| 10* | Information technology-mediated communication less effective | Collaboration process | 21 | Scheduling or time zone issues | Logistics |
| 12 | Information overload | Collaboration process | 14 | Lack of willingness to adopt or learn | Individual |
| 3* | Cost | Resources | 5 | Differences in tool preferences or choices | Individual |
| 22 | Security and security policy | Tool or technology | 9 | Discomfort with mediated communication | Individual |
| 13 | Insufficient technical support | Resources | 17 | More misunderstandings | Collaboration process |
As mentioned previously, the Delphi technique is highly conducive to producing a consensus among group members through several rounds of opinion solicitations. Hence, the presentation of Delphi results should reflect this convergence process. As illustrated in the above example study, Tables 2, 3 and 4 profile how the group consensus for this given topic was eventually achieved.
It is also recommended that the demographics of experts be provided so that the readers have a glance of the panel members' qualification and skill levels, which supports the relevance and reliability of respondents to a specific topic (Brancheau and Wetherbe 1987; Schmidt 1997).
Discussion: concerns and limitations
While the strengths of the Delphi method are evident, its challenges are also well perceived. A couple of concerns and limitations encountered in the course of conducting this study drew our attention.
Number and range of identified issues and homogeneity of panel members: Twenty-four study participants were recruited into two different domain groups (social and behavioural sciences vs. science and engioneering) in order to examine whether or not differences exist in the barriers/challenges perceived by them using information and communication technologies. Each panellist was asked to generate at least ten major issues. The collected inputs were then collated and categorized by the investigators into a list of identified issues. It turned out that the spectrum and numbers of the identified issues were as broad as the diversity of the participants' domain areas in this study. The types of identified issues ranged from tool/technology, collaboration process, logistics and resources to individual experience or perception (see Table 4 for the identified issues in detail). The wide-ranging of the issues might have led to the lower agreement among the participants.
Agreement rate among experts (panel members) for reliability:Given the characteristics of the Delphi method, applying nonparametric techniques is considered to be preferred for several reasons. First, in practice, we may often encounter data that comes from a non-normal distribution which skewed, highly peaked, highly flat, etc., and is not covered by parametric methods. In such situations, nonparametric techniques should be used, because they do not assume a particular population probability distribution. In contrast, parametric statistical approaches, 'hypothesis testing and the confidence interval rely on the assumption that the population distribution function is known, or a few unknown parameters' (Conover 1999: 115). Most parametric methods are based on the normality assumption, in which data are normally distributed and the 'parameters,' such as means, standard deviations and proportions, provide important clues to understanding the shape or spread of the probability distribution. Secondly, thanks to their distribution-free nature, nonparametric techniques 'are valid for data from any population with any probability distribution' (Conover 1999: 116). Therefore, the data from a biased, non-random sample, like the Delphi's sample of experts, would still be valid using nonparametric methods with a good statistical power to data analysis. Third and most important, nonparametric techniques are equipped to handle ordinal data. They are 'often the only [methods] available for data that simply specify order (ranks)' (Sprent and Smeeton 2000: 5). As described previously, the Delphi methods depend heavily on iterative elicitations from respondents who are repeatedly asked to identify and rank items. Nonparametric methods include a family of statistical procedures used to analyse the ranked data, such as the Friedman test and Kendall's W; these can be used to test for evidence of consistency between the respondents who assign the ranking. Delphi researchers could consider these procedures useful to track consensus in a rigorous, statistical manner. Finally, when the study sample size is very small (Siegel and Castellan 1988) nonparametric statistics are more appropriate, in order to retain the same statistical power to test null hypotheses.
With all above-mentioned characteristics of nonparametric statistics, some specific methods were considered for application in our example study. One of the focal points of using the Delphi method is to elicit and shape a group consensus. The degree of agreement achieved among raters (experts/panel members) must be substantial for researchers to make their decisions regarding the optimal number of iterations. Ensuring a certain degree of agreement is directly related to the reliability and validity of the data collected and consequently analysed from each round of inquiries. Moreover, as mentioned earlier, few of the previous Delphi studies specified their adequate level of agreement. The majority of Delphi studies used descriptive statistics, such as average, percentile or standard deviation, with ill-defined cut-off points for the agreement rates. To remedy this, our sample study sought a more sound and consistent way to demonstrate degree of agreement rates by calculating Kendall's W. An analysis of participant rankings indicated that the mean ranks are relatively flat and widely dispersed among the identified issues. This could be due to the different issues (challenges and conflicts) emphasized by the individual panellists, and could be considered for future endeavour.
Conclusions
The Delphi method is a popular method used by researchers to investigate a variety of research questions in the field of library and information science. Often the Delphi method is not considered as rigorous as other research methods. This is primarily due to a lack of standard statistical tests which would ensure the validity and reliability of the research. Without such statistical tests, it would then be hard to accurately define the optimal number of iterative rounds for data collection. It also would be not statistically rigorous to designate consistent cut-off points for the level of agreement among the panel members. In order to address these critical issues, the authors attempted to explore the applicability of nonparametric statistics as one of the possible solutions, via an illustrative study. More specifically, in our sample study, research attempts were made to identify the source of the challenges encountered by collaborative researchers, and to understand the interrelations among the identified issues.
There are two advantages to our nonparametric statistics approach. One is that, when using a small sample size, our approach provides rigorous and reliable statistics regarding the degree of consensus among the panellists. Another advantage is the justification for setting the cut-off point for each iteration. In most of the previously conducted LIS Delphi studies, explanations about the levels of consensus (or agreement) among panellists at each round are under-emphasized, creating a lack of support for the underlying logic. For example, using percentages or the standard deviation of agreement among panellists, or collecting only the descriptive characteristics of data from each round, does not ensure a level of consensus has been achieved, and results are less predictable. Using our approach could respond to the criticism of this method being 'not a statistically rigorous methodology for predicting the future' (Ludwig and Starr 2005: 316).
We propose our approach with one proviso. As discussed, when the homogeneity of the panel of experts is not guaranteed and Delphi researchers have to deal with a variety of broad and complex topics, which need to be identified in their study, then the approach presented in our example study would not be well served. Therefore, the choice of the method should be made carefully with consideration for the many tenets that define good, basic research. That having been said, the Delphi method with our nonparametric statistical approach can, potentially, be an excellent tool for LIS researchers.
Acknowledgements
Authors would like to thank referees, the editor (North American editor), and the copyeditor for valuable feedback and constructive suggestions to improve this manuscript. We also appreciate Rachel Gifford for her time and effort to read and edit our manuscript.
About the author
Boryung Ju is an Associate Professor in the School of Library and Information Science, Louisiana State University, USA. She received her Master's degree in Library and Information Science from Indiana University and her PhD in Information Studies from the Florida State University, USA. She can be reached at: bju1@lsu.edu.
Tao Jin is an Assistant Professor in the School of Library and Information Science, Louisiana State University, USA. He received his Master's degree in Library and Information Science, and PhD in Information Studies from McGill University, Canada. He can be reached at: taojin@lsu.edu.


