Análisis de metadatos de noticias para la extracción de información del código fuente. El software METADATOSHTML
María-José Baños-Moreno, Eduardo R. Felipe, Juan-Antonio Pastor-Sánchez, Gercina Lima, y Rodrígo Martínez-Bejar.
Introducción. Los objetivos de este trabajo son determinar qué esquemas se utilizan para título, resumen, palabras clave, autoría y periódico en prensa; conocer qué pautas siguen los periódicos en la implementación de dichos esquemas; y averiguar cómo esto afecta a la extracción de información.
Metodología. Para ello, se define una muestra de diarios y se analiza su código fuente, identificando esquemas utilizados y patrones de uso. Esto permite extraer valores de dato utilizando la aplicación MetadadosHTML.
Resultados. Se han detectado esquemas estándar, ad hoc y propios de los periódicos. Se han hallado diversas prácticas, como valores agrupados en una misma línea de código o por separado; ruido en un valor y errores al referir los nombres de los atributos de esquemas estándar. Estos problemas afectan a la extracción de datos basada en esquemas de metadatos y metadatos en MetadadosHTML
Conclusiones. Es necesario avanzar en el uso de esquemas estándar, como Dublin Core o schema.org, favoreciendo la implantación de estos (u otros) en los códigos fuente de noticias. También resulta imprescindible la adopción de buenas prácticas al explicitar datos y valores de datos. Sólo así es posible evolucionar en la interoperabilidad entre sistemas y en la recuperación y reutilización de información.
Introducción
Los metadatos son el conjunto de atributos y valores de dato que representan un recurso, facilitando su identificación (Felipe, 2016; Abbud Grácio and Fadel, 2010, pp. 10–11; AENOR, 2012; Hillman, 2005; Kallipolitis, Karpis, and Karali, 2012; Yaginuma, Pereira, and Baptista, 2003a). Más específicamente: ‘son descripciones estructuradas y codificadas que describen características y propiedades de objetos y recursos para facilitar su localización, recuperación, valoración, administración, persistencia e interoperabilidad’ (Pastor-Sánchez, 2011, p. 22). Los metadatos tienen como funciones facilitar el descubrimiento de recursos, así como su evaluación y consumo (Díaz, Granell, Beltrán Fonollosa, Llaves, and Gould, 2008).
Cuando esos metadatos se organizan en una estructura de elementos comunes (Pereira and Baptista, 2004; Yaginuma, Pereira, and Baptista, 2003b) se habla de esquemas de metadatos.Estas estructuras, como DC (Dublin Core), están orientadas a la descripción (normalizada) de documentos mediante conjuntos de atributos similares a los contemplados por las normas ISBD, entre otras, para la descripción bibliográfica en catálogos de bibliotecas (Ortiz-Repiso Jiménez, 1999). Es decir, pueden aplicarse para el análisis documental de documentos (Abadal and Codina, 2009; Baptista and Barbosa Machado, 2001; Kallipolitis et al., 2012; Yaginuma et al., 2003a, 2003b). Un enfoque, complementario a los anteriores, se centra en el descubrimiento de información a partir de metadatos descriptivos (Vallez, Rovira, Codina, and Pedraza-Jiménez, 2010; Rovira and Marcos, 2006; Vásquez Paulus, 2008; Ortiz-Repiso Jiménez, 1999). Así, (Guallar, Abadal, and Codina, 2016, 2012), entre otros, ofrecen indicadores para el análisis de los sistemas de consulta de hemerotecas de periódicos, teniendo en cuenta, entre otros, las opciones de acotación temporal, uso de índices (de autores, de personajes, etc.) y búsqueda por palabrasclave. Estos elementos no son más que metadatos asignados a artículos de prensa, que pueden ser recuperados gracias al uso de esquemas de metadatos en los sistemas de recuperación de información, aumentando su efectividad (Garshol, 2004; Vásquez Paulus, 2008).
Ahora bien, una recuperación de información exhaustiva, sólo es posible cuando los metadatos son computables, es decir, tratables por máquinas (Díaz et al., 2008), estandarizados y de uso generalizado, especialmente si se pretende la interoperabilidad entre sistemas. Esto aún no se ha producido, principalmente con las etiquetas meta de los encabezados HTML, cuya información muchas veces no describe el contenido real del documento web (Burgués, 2009, pp. 3–4). El trabajo actual pone el foco, precisamente, en cinco metadatos de descripción de artículos de prensa escrita: título, resumen, palabras clave, autor/a y medio, recogidos bien como etiquetas meta bien como atributos en otras etiquetas. Continúa así la investigación iniciada en (Baños-Moreno, Felipe, Pastor-Sánchez, Martínez-Béjar, Rodrigo, and Lima, 2015), donde se expone qué esquemas de metadatos existen en el ámbito periodístico desde dos perspectivas: bibliografía especializada y códigos fuente de una selección de periódicos. En esta publicación se destacan, entre otras: 1) Que existen diversos esquemas, generales y especializados, con distintos grados de implantación; 2) Que los especializados en prensa apenas son utilizados en los códigos analizados; 3) Que en la bibliografía apenas se referencia los esquemas visibles en los códigos fuente; 4) Todo ello dificulta la descripción unificada de recursos y, con ello, la recuperación y reutilización de información disponible en web.
Partiendo de estas cuestiones, y con vistas a la reutilización de información de actualidad para el modelado de una ontología de dominio (Baños-Moreno, Pastor-Sánchez, and Martínez-Béjar, 2013), se plantean tres objetivos: 1) determinar qué esquemas se utilizan para asignar los atributos indicados; 2) conocer qué pautas se siguen en el uso de dichos esquemas en etiquetas meta y atributos de etiquetas HTML; y 3) averiguar cómo la elección de esquemas y pautas de uso afectan a la extracción de valores de datos (data values). Para ello, se analizan los códigos fuente de una muestra de noticias, identificando tanto esquemas de metadatos como patrones de uso en los elementos de estudio. Para la extracción se emplea una aplicación desarrollada ad hoc que, basándose en los datos de las etapas previas, obtiene automáticamente valores de dato.
Metodos
Se definió una muestra de periódicos (Tabla 1) para la cual se dividió el mundo en 9 zonas, de acuerdo a características geopolíticas, históricas y socioeconómicas. En cada área se seleccionaron aquellos países con mayor Producto Interior Bruto (PIB). Después, se escogió el diario generalista más leído en cada país, de acuerdo a datos de accesos Web y compra de edición en papel de 4International Media and Newspaper (4IMN).
| Zona del mundo | País | Periódico | Código |
|---|---|---|---|
| Europa | Alemania | Süddeutsche Zeitung | 101 |
| Francia | Le Monde | 111 | |
| Reino Unido | The Daily Telegraph | 121 | |
| Financial Times | 122 | ||
| The Economist | 123 | ||
| Norteamérica | Estados Unidos | The New York Times | 201 |
| The Wall Street Journal | 202 | ||
| Latinoamérica | Brasil | O Globo | 301 |
| México | El Universal | 311 | |
| Ex-Repúblicas rusas | Rusia | Pravda | 401 |
| África Subsahariana | Nigeria | Nigerian Tribune | 501 |
| Sudáfrica | Independent Tribune | 511 | |
| Asia | China | China Daily | 601 |
| India | The Times of India | 611 | |
| Japón | Asahi Shimbun | 621 | |
| Oriente | Arabia Saudí | Arab News | 701 |
| Emiratos Árabes Unidos | Gulf News | 711 | |
| Israel | Yedioth Aharonot | 721 | |
| Turquía | Today's Zaman | 731 | |
| Oceanía | Australia | The Australian Financial Review | 801 |
| Norte de África | Egipto | The Daily News Egypt | 901 |
Los códigos de la columna Código de la Tabla 1 identifican los periódicos por: zona del mundo (primera cifra), país (segunda cifra) y periódico (tercera cifra). Estos códigos son utilizados a lo largo de este documento para simplificar el texto.
Para el análisis, se accedió a tres noticias por periódico en días diferentes durante enero y
febrero de 2016. Para la identificación de metadatos, se revisó el código fuente de los diarios, tanto de forma manual como utilizando el servicio de validación de marcado de contenidos web del W3C (Markup Validation Service).
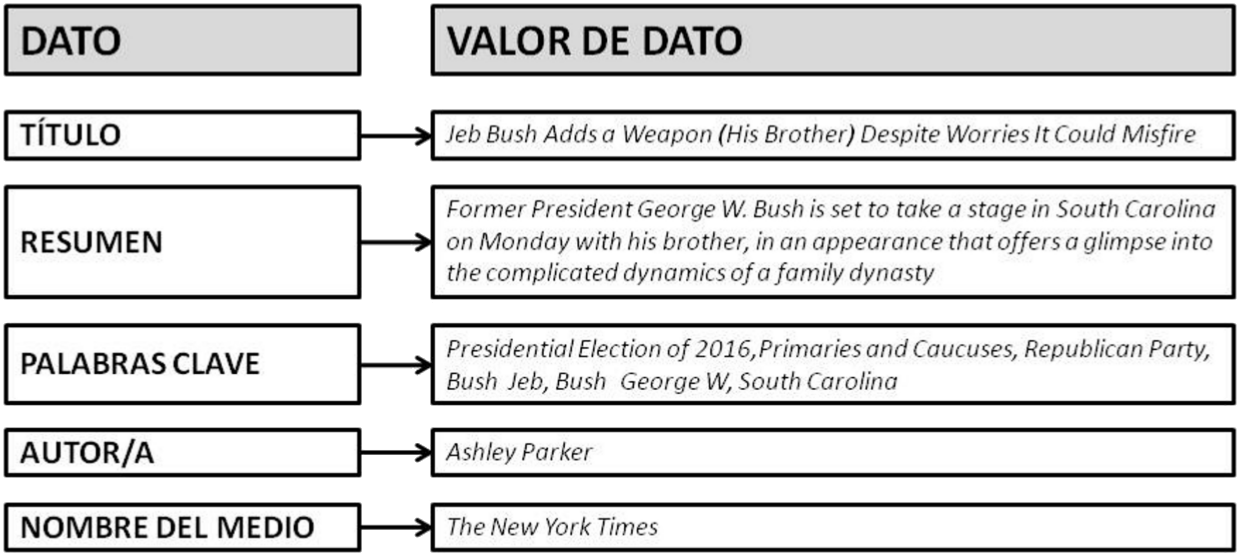
Figura 1: Datos y valores de datos para noticia redactada por (Parker, 2016)
Se tuvo en cuenta para ello tanto las etiquetas meta como los atributos que aparecen en el cuerpo de la página web (<body>), en función de las diferentes formas que pueden adoptar. En este sentido, un metadato está compuesto por pares de datos y valores de datos, de la forma en que se muestra en la Figura 1. No se tiene en cuenta en esta categorización aquellos atributos que tienen como único fin la separación en secciones de una página web. Por ejemplo, <div id="Title_e"> ó <div id="article_head">, utilizados por China Daily y Asahi Shimbun, respectivamente. Tampoco la información en scripts, aunque algunos medios aplican algunos de los esquemas nombrados anteriormente, como schema.org (The Wall Street Journal o Pravda.ru, entre otros).
A partir del análisis, se hallaron tres tipos de esquemas: estándares, ad hoc y propietarios, descritos en el apartado Resultados. Además, se identificaron una serie de características e incidencias para título, resumen, palabras clave, autor/a y nombre del medio.
Teniendo en cuenta estos aspectos se diseñó un algoritmo para la extracción de información. Implementado en MetadadosHTML, el algoritmo accede, extrae y almacena las descripciones de noticias de una muestra de más de 5500 noticias obtenidas de los diarios indicados en la Tabla 1. La idea es similar a (Burgués, 2009) que, en ausencia de un estándar de uso común, extrae la información de las etiquetas HTML, para luego generar un XML con el que indexar los documentos y reconoce problemas similares a los hallados en este trabajo, que se detallan a continuación. Otras aproximaciones, como (Bohannon et al., 2012) diseñan algoritmos que, entre otros elementos del código fuente, también emplean las meta-etiquetas para identificar el contenido de los documentos y sus atributos. Sin embargo, no se tienen en cuenta los estándares de metadatos, y asumen la presencia de ruido en la información extraída, contrarrestándola con reglas de aprendizaje automático para eliminarlo.
Resultados
El análisis de los esquemas identificados en los códigos fuente llevó a su clasificación en tres categorías, que se describen brevemente a continuación:
1. Esquemas externos y reconocidos internacionalmente (esquemas estándar)
Dentro de esta categoría están Open Graph Protocol (en adelante OG), Dublin Core (DC), Twitter Cards (TC), hAtom o schema.org (SC). También se incluyen algunas etiquetas meta de HTML, donde el atributo name indica el atributo, o tipo de dato y content el valor del dato. Estas etiquetas meta se refieren al contenido del documento y pueden considerarse ‘nombres de metadatos estándar’ (Hickson et al., 2014): <meta name="author" content=”...”>, <meta name="description" content=”...”> y <meta name=”keywords” content=”...”>. No incluye <meta name="title" content=”...”>.
En el caso de utilizar XHTML, uno de los usos de los atributos de metadatos, como property, es representar ‘el contenido del documento, ya que la misma cadena literal puede utilizarse para especificar tanto el contenido del documento como los metadatos’ (Axelsson et al., 2006). Así, <span property="dc:title" content="...">, de Nigerian Tribune (501), utiliza el esquema DC para referirse al título de una noticia.
En cuanto a schema.org (SC), usa microdatos para, mediante el atributo itemprop, referirse a una meta-información (Baños-Moreno et al., 2015). Este atributo se inserta habitualmente en las etiquetas del cuerpo (<body>), aunque también puede insertarse en las etiquetasmeta (Leithead, Pfeiffer, Navara, and O’Connor, 2012) (véase la Figura 2). Algo similar ocurre con el microformato hAtom 0.1., utilizado por The Daily News Egypt (901), que inserta meta información en <body> tal y como puede verse en la figura 2.

Figura 2. Etiquetas meta de The New York Times (201) con el atributo itemprop, sin valores de dato.
La figura 3 resume los esquemas estándar utilizados para título, resumen, palabras clave, autor y nombre del medio.
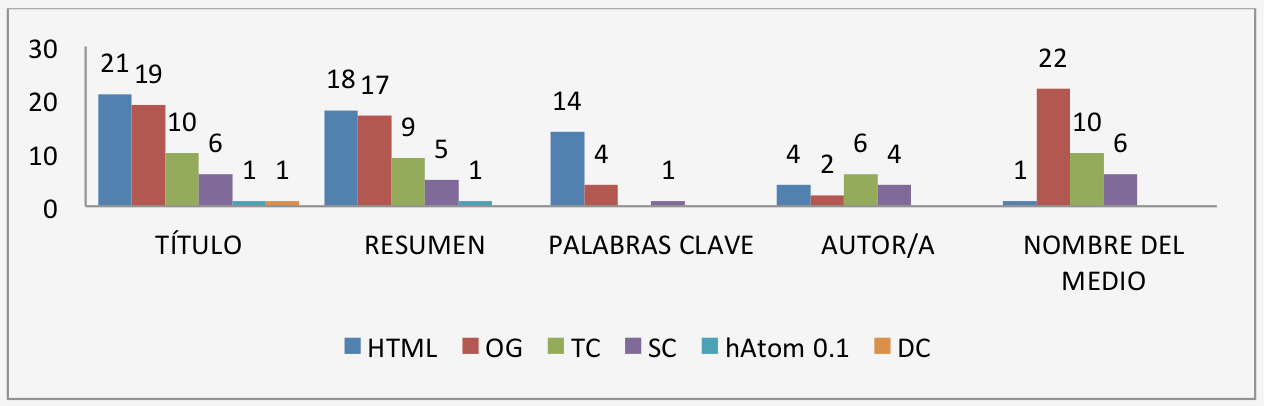
Figura 3: Frecuencia de esquemas estándar en la muestra de periódicos por tipos de metadatogure1: the conceptual framework
Para los atributos analizados, los estándares más utilizados, con diferencia son HTML (100%), OG (90%), TC (71%) y SC (52%), con distintos grados de implementación, especialmente en cuanto a título, resumen y palabras clave. La cifra más elevada (22 diarios) para el nombre del medio, en OG, se debe al uso de dos atributos: site_name y article:publisher, también ocurre con schema.org (SC).
Para algunos de estos esquemas estándar se han desarrollado validadores que analizan la corrección de las etiquetas y el uso de atributos, como Markup Validation Service, de la W3C, Card validator, de Twitter Cards, ó Structured Data Testing Tool, de Google.
2. Esquemas externos para un propósito concreto (esquemas ad hoc).
Se han identificado cuatro tipos (Sailthru, Bi3d, Parse.ly y dcsext). La figura 4 muestra algunos ejemplos de código, para tres de estos esquemas propietarios.

Figura 4. Etiquetas ad hoc de los esquemas de metadatos de Sailthru, Bi3d y Parse.ly
Sailthru, y su tecnología propietaria Horizon ‘realiza un seguimiento del comportamiento en el sitio, móvil y del correo electrónico para desarrollar un perfil de interés único para cada usuario final’ (Sailthru, 2013).
El esquema desarrollado por Bi3d (Believe in 3D) ‘desarrolla la próxima generación de interfaces humano-ordenador interactivos para la industria del marketing y el entretenimiento’ (BI3D, 2013). Parece que, en este momento, no está operativa.
Parse.ly es otra plataforma de análisis diseñada específicamente para los editores en línea y ofrece tres formas de incorporar estos datos a la página web: JSON-LD; repeated metadata; parsely-page. Parse.ly sigue el esquema NewsArticle de schema.org. The Daily Telegraph (121) utiliza la opción parsely-page, ya obsoleta y reemplazada por JSON-LD pero que aún puede ser rastreada (Parse.ly, s.f.).
Webtrends, otra empresa de análisis web, escanea el código fuente buscando parámetros de consulta Webtrends para añadir a los datos. En la muestra, The Daily Telegraph recurre a su espacio de nombre, DCSext para coleccionar datos.
En este grupo podría incluirse la etiqueta de Google, <meta name="news_keywords" content="..."> creada para que los periódicos indiquen las palabras más relevantes de una noticia (Google Inc., 2016).
El siguiente gráfico muestra los esquemas ad hoc utilizados para los datos analizados: título, resumen, palabras clave, autor y nombre del medio.
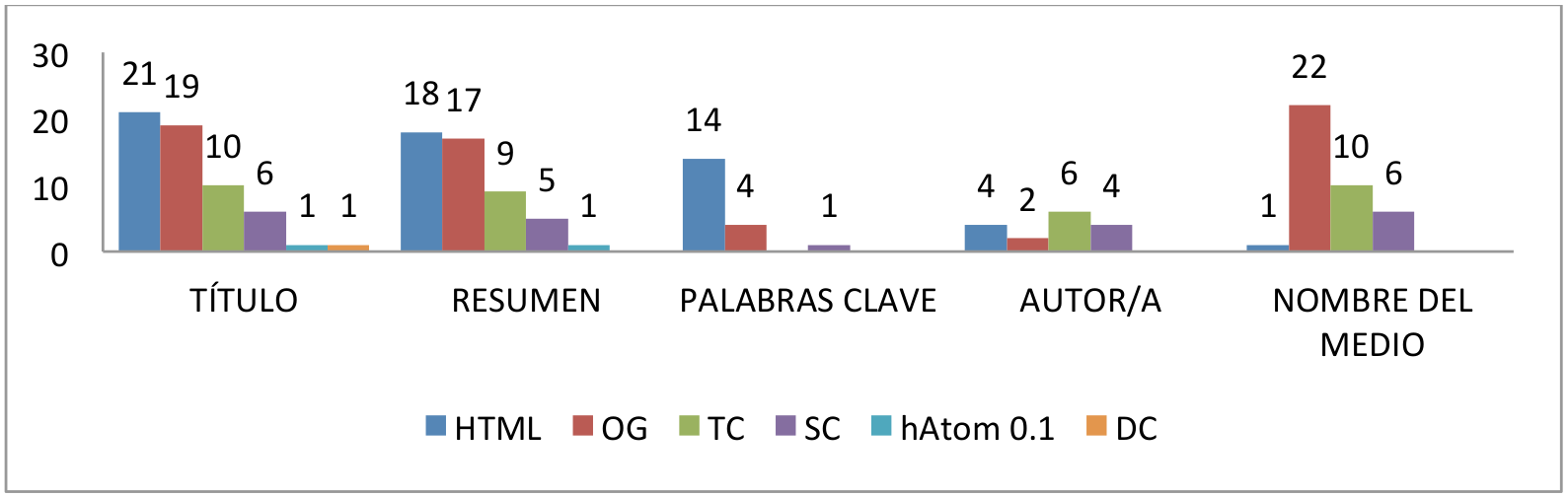
Figura 5. Frecuencia de esquemas estándar en la muestra de periódicos por tipos de metadato.
Tanto los esquemas externos de propósito específico como los propietarios son utilizados
de forma residual, por un sólo medio en cada caso (5%), a excepción de la etiqueta meta de Google, news_keywords (30% de la muestra).
3. Esquemas propios, desarrollados por el periódico (esquemas propietarios).
Se utilizan para la estructuración y categorización de sus artículos. Este tipo de esquema es el menosfrecuente, con presencia solamente en dos medios, The New York Times (201) y The Wall Street Journal (202), con dos esquemas propios por cada medio. La tabla 2 muestra algunos elementos del esquema de The New York Times.
| Campo | Significado | Correspondiencia |
|---|---|---|
| hdl | Headline | Titular |
| byl | Byline | Autor del artículo |
| lp | Lead Paragraph | Resumen |
| des | Subjects / Descriptive Terms | Palabras clave |
| per | People | Identificador para personas |
| org | Organizations | Identificador para organizaciones |
| geo | Geographic Locations | Identificador para lugares geográficos |
En ocasiones, también se pueden incrustar datos no visibles y personalizados (embedded custom non-visible data) gracias a HTML5. Tal y como puede verse en la figura 6 son atributos sin espacio de nombre cuyo name comienza con la cadena data- y tienen, al menos un carácter después del guión (Hickson et al., 2014) (ver Figura 4). Puesto que son elementos personalizables, se clasifican como esquemas propietarios.

Figura 6. Atributos data- para artículos en The New York Times y The Wall Street Journal, respectivamente
En relación al tipo de dato, los más asentados son título y resumen. Estos aparecen, mediante etiquetas meta o atributos, en todos los diarios de la muestra. Destaca la ausencia de metadatos, en cualquiera de las formas identificadas, en palabras clave (16%), nombre del medio (19%) y autoría (33%), pues todos son elementos básicos del análisis de contenido (palabras clave) y formal (autor y publicación) de un documento. En el ámbito específico de medios de comunicación impresa, (Yaginuma et al., 2003b), en el marco del proyecto Omnipaper, los califica de imprescindibles para la correcta representación de una noticia.
A continuación, se muestran las particularidades de las líneas de código para cada uno de los atributos objeto de este análisis.
Titular de la noticia
Para el titular, se utiliza, en todos los casos, la etiqueta <title>, que se refiere al título de una página web cualquiera y, en este caso, para titulares de noticias. Por el contrario, <meta name="title" content="..." /> está menos extendida. Además, se han identificado esquemas de los tres tipos indicados, aunque con un marcado incorrecto. Por ejemplo, en: <h1 itemprop="headline name">, de The Economist, aparece el atributo headline name, que no reconoce schema.org . También se han hallado atributos con diferente denominación para referirse a este elemento, como hdl, headline o article.origheadline (ver Tabla 3).
| Línea de código | Tipo de esquema | N |
|---|---|---|
| <title>...</title> | Estándar (HTML) | 21 |
| <meta property="og:title" content="..."> | Estándar (OG) | 19 |
| <meta name="twitter:title" content="..."> | Estándar (TC) | 10 |
| <h1 itemprop="headline">...</h1> <h1 itemprop="headline name">...</h1> <h3 itemprop="headline" class="headline">...</h3> <meta itemprop="name" content="..."/> | Estándar (SC) | 6 |
| <h1 class="entry-title">...</h1> | Estándar (hAtom 0.1) | 1 |
| <span property="dc:title" content="" class="..."> | Estándar (DC) | 1 |
| <meta name="sailthru.flytitle" content="..." /> | Ad hoc (Sailthru) | 1 |
| <meta name="bi3dArtTitle" content=" " /> | Ad hoc (Bi3D) | 1 |
| <meta name="parsely-page" content='{"title": "..." .../> | Ad hoc (Parse.ly) | 1 |
| <meta name="hdl" content="..." /> | Propietario (201) | 1 |
| <div id="..." aria-label="..." role="..." class="..." data-title="..."...>...</div> | Propietario (201) | 1 |
| <meta name="article.origheadline" content="..." /> <meta name="article.headline" content="..." /> | Propietario (202) | 1 |
| <li class="..." ... data-headline="...">...</li> | Propietario (202) | 1 |
En ocasiones, además, el texto incluye ruido, información que no es propiamente el titular. Por ejemplo: <title>Jeremy Corbyn tries to force public schools to open up music, arts, sport facilities to state schoolchildren - Telegraph</title>.
Resumen o descripción.
Este elemento cuando es una noticia, suele tratarse de un subtítulo o bien la entradilla, ‘un resumen lo suficientemente completo y autónomo como para que el lector conozca lo fundamental de la noticia sólo con leerlo’ (Lajusticia, 2000).
Se han identificado esquemas de los tres tipos indicados (tabla 4) pero, como con el titular, con un marcado incorrecto. Así, en <p class="article entry-summary>, de Süddeutsche Zeitung (101), el atributo class="article entry-summary" no se corresponde con el definido por el esquema de hAtom, en el que parece estar basado, siendo class="entry-summary" el correcto.
| Línea de código | Tipo de esquema | N |
|---|---|---|
| <meta name="description" content="..."> | Estándar (HTML) | 18 |
| <meta property="og:description" content="..." /> | Estándar (OG) | 17 |
| <meta name="twitter:description" content="..."> | Estándar (TC) | 9 |
| <h2 class="..." itemprop="description">...</h2> <meta itemprop="description" name="..." content="..." /> | Estándar (SC) | 5 |
| <p class="article entry-summary">...</p> | Estándar (hAtom 0.1) | 1 |
| <meta name="lp" content="..." /> | Propietario (201) | 1 |
| <div id="..." aria-label="..." role="..." class="..." data-description="..." ...>...</div> | Propietario (201) | 1 |
| <meta name="article.summary" content="..." /> | Propietario (202) | 1 |
| <li class="..." ... data-summary="...">...</li> | Propietario (202) | 1 |
A veces, también el texto incluye ruido. Por ejemplo, El Universal comienza el texto con su perfil de Twitter: <meta name="description" content="metropoli@eluniversal.com.mx ..." />.
Palabras clave.
Las palabras clave son términos que, en su conjunto, representan el contenido de un documento. En general, se utilizan dos formas para referirse a este elemento: keywords y tag. En la tabla 5
muestra el código a extraer, de qué esquema y en qué periódicos aparece.
| Línea de código | Tipo de esquema | N |
|---|---|---|
| <meta name="keywords" content="..."> | Estándar (HTML) | 14 |
| <meta property="article:tag" content="..." /> | Estándar (OG) | 4 |
| <meta itemprop="keywords" content="..." /> | Estándar (SC) | 1 |
| <meta name="sailthru.tags" content="..." /> | Ad hoc (Sailthru) | 1 |
| <meta name="parsely-page" content='{...,"tags": ["..."]}'/> | Ad hoc (Parse.ly) | 1 |
| <meta name="news_keywords" content="..."> | Ad hoc (Google) | 7 |
| <meta name="DCSext.cmsSect" content="... " /> | Ad hoc (DCSext) | 1 |
| <meta name="org" content="..." /> <meta name="des" content="..." /> <meta name="geo" content="..." /> <meta name="per" content="..." /> | Propietario (201) | 1 |
Para este dato, destacan algunos aspectos que influyen en la extracción de información a partir
del código fuente:
- Campos repetibles: Casi todos los medios incluyen en una misma línea el conjunto de
palabras clave que representa el contenido de un artículo. Algunos periódicos, sin
embargo, repiten la meta etiqueta con valores diferentes, tantas veces como palabras
clave refiera, como se muestra en las tablas 6 y 7.
| Línea de código | Repiten etiqueta | No la repiten | Total |
|---|---|---|---|
| <meta name="keywords" content="..."> | 1 | 13 | 14 |
| <meta property="article:tag" content="..." /> | 3 | 1 | 4 |
| <meta name="org" content="..." /> <meta name="des" content="..." /> <meta name="geo" content="..." /> <meta name="per" content="..." /> |
203 | --- | 1 |
- Mismo propósito, información diferente: The New York Times (201) muestra las
palabras clave en distintas etiquetas meta y rompe el patrón de otros esquemas, pues no
recoge la misma información, aunque el fin del esquema es el mismo. - Escasa categorización: The New York Times es el único diario que en un esquema
propio, el tipo de palabras clave (tabla 7): des → descriptores; org → organización;
per → persona; geo → lugar.
| Tipo de esquema | Línea de código fuente |
|---|---|
| Estándar (OG) | <meta property="article:tag" content="Presidential Election of 2016" /> <meta property="article:tag" content="Republican Party" /> <meta property="article:tag" content="Cruz, Ted" /> <meta property="article:tag" content="Primaries and Caucuses" /> <meta property="article:tag" content="Iowa" /> |
| Propietario | <meta name="des" content="Presidential Election of 2016" /> <meta name="org" content="Republican Party" /> <meta name="per" content="Cruz, Ted" /> <meta name="des" content="Primaries and Caucuses" /> <meta name="geo" content="Iowa" /> |
| Estándar (HTML) | <meta name="keywords" content="Presidential Election of 2016,Republican Party,Cruz Ted,Primaries and Caucuses,Iowa" /> |
| Ad hoc (Google) | <meta name="news_keywords" content="Iowa" /> |
- Ruido en el valor de dato: Como en los casos de titular y resumen, a veces se incluye en esta etiqueta información que no corresponde a este espacio. Por ejemplo:
- En <meta name="news_keywords" content="VW, Matthias Müller, Volkswagen, Wirtschaft">, Süddeutsche Zeitung (101) incluye el nombre del autor del artículo. También lo hace The Daily Telegraph (121).
- En <meta name="keywords" content="israel, news, yedioth, ahronoth, english, ..., breaking news, jew, jews, www.ynetnews.com"> Yedioth Aharonot (721) incluye el nombre del medio, la sección de la noticia y la URL del medio.
- Arab News (701) repite la etiqueta <meta name="keywords" content="..."/>: la primera vez hace referencia a la sección en la que se ha clasificado la noticia; la segunda recoge las palabras clave (figura 7).

Figura 7. Etiquetas meta estándar (HTML) usadas por Arab News (7011) para sección y las palabras clave
- Código fuente con fines publicitarios: Finalmente, se puede destacar la orientación a cuestiones publicitarias de algunos elementos de descripción de noticias, habitualmente mediante Javascripts. Este aspecto no se ha tenido en cuenta en este trabajo.
Todos los periódicos recogen en su código fuente líneas para palabras clave, con tres excepciones: Le Monde (111), Nigerian Tribune (501) e Independent Online (502).
Autor de la noticia.
Autor/a es la persona o personas que han escrito una noticia y en los códigos fuente suele aparecer con dos denominaciones: author ó creator (tabla 8).
Para este dato, destacan estos aspectos:
- Mismo propósito, información diferente: el valor de dato de la etiqueta meta no siempre se corresponde con el nombre de quien ha redactado el artículo. Por ejemplo, <meta name="author" content="...">, de Süddeutsche Zeitung (101), muestra el nombre del medio. Algo similar sucede con <meta name="twitter:creator">, de The Economist (122), que indica como valor la sección en que se publica la noticia. Otros utilizan esta misma línea para hacer referencia al perfil de Twitter del medio
- Errores de marcado: The Daily Telegraph (121) marca incorrectamente el atributo de OG para el objeto article en <meta property="article:authorName" content="..." />, en lugar de article:author.
- Dos atributos, mismo valor: The New York Times (201) hace referencia a autor y creador en la misma línea, con el mismo valor ([Web Hypertext Application Technology Working Group (WHATWG)], 2016a): <span ... itemprop="author creator" ...>.
- Campos repetibles: Cuando una noticia ha sido escrita por varios autores, habitualmente se repiten las líneas de código.
- Otros medios recogen este dato como una palabra clave de la noticia o bien lo que aparece es un enlace al conjunto de noticias redactadas por la misma persona.
| Línea de código | Tipo de esquema | N |
|---|---|---|
| <meta name="author" content="..."> | Estándar (HTML) | 4 |
| <meta property="article:authorName" content="..." /> <meta property="article:author" content="..." /> | Estándar (OG) | 2 |
| <span itemprop="author" class="...">...</span> <div class="..." itemprop="author" ...>...</div> <b itemprop="author" ...>...</b> <span class="byline" itemprop="author creator" itemscope itemtype="http://schema.org/Person" itemid="...">...</span> | Estándar (SC) | 4 |
| <meta name="twitter:creator" content="... " /> | Estándar (TC) | 6 |
| <meta name="parsely-page" content='{...,"authors": ["..."]}'/> | Ad hoc (Parse.ly) | 1 |
| <meta name="DCSext.author" content="..." /> | Ad hoc (DCSext) | 1 |
| <meta name="byl" content="..." /> | Propietario (201) | 1 |
| <div id="..." aria-label="..." role="..." class="..." data-shares="..." ... data-author="..." ...>...</div> | Propietario (201) | 1 |
| <li class="..."... data-authors="...">...</li> | Propietario (202) | 1 |
Para este dato no se identificó ningún metadato en Pravda (401), Nigerian Tribune (501), China Daily (601), The Times of India (602), Asahi Shimbun (603), Arab News (701) ni en Yedioth Aharonot (721).
HTML5 permite expresar la autoría mediante la etiqueta rel=”author”, Este atributo, escaso en la muestra, no se ha tenido en cuenta en este trabajo, ya que HTML5 aún no se ha asentado.
Nombre del periódico
El medio es el que canaliza y publica los artículos de sus periodistas, agencias e invitado/as. Esta información es susceptible de ser expresada en diversos campos, pues el periódico es, normalmente, el propietario del sitio web que recoge los artículos, dueño del copyright de la información que publica, tiene uno o varios perfiles en redes sociales, etc.
Para este dato, destacan estos aspectos:
- Diferentes atributos para un mismo tipo de información. Existen varios atributos que, aunque en principio están destinados a fines diferentes, suelen mostrar el nombre del medio: publicador (publisher), copyright, nombre del sitio web (site name), etc.
- Mismo atributo, diferentes valores de dato. Un aspecto a destacar es el uso de códigos para identificar el medio, como hacen O Globo (301) o The Daily Telegraph (121), de quien es esta etiqueta meta: <meta property="article:publisher" content="143666524748" />; Otros, como The Economist (122), The Wall Street Journal (202), The Australian Financial Review (801) o Daily News Egypt (901), lo completar con la URL de su perfil en Facebook.
- Otros datos como ruido en la etiqueta meta o atributo correspondiente. En ocasiones, este metadato es declarado en las etiquetas donde debería aparecer como valor de dato el nombre del autor de un artículo, aún cuando en la noticia aparece una persona con nombre y apellidos.
- Nombre del medio como ruido en otros datos. Es frecuente encontrar el nombre del medio entre las etiquetas <Title> y </Title>, complementando al título, e incluso entre las palabras clave de la noticia. No se han tenido en cuenta en la Tabla 9. Por otro lado, como se ha indicado en el bloque anterior, Süddeutsche Zeitung (101) recoge este dato en la etiqueta meta de autor, contabilizándose en la Tabla 10, por lo que no se tiene en cuenta en este punto. Lo mismo sucede con <meta name="twitter:creator" content="..." />, usada por O Globo (301).
- Etiquetas que no son estándar o han dejado de ser utilizadas. Entre las etiquetas meta, las cuatro vistas anteriormente son consideradas estándar (Hickson et al., 2014; WHATWG, 2016b). No ocurre así con <meta name="copyright" content="...">, que podría ser sustituida por dcterms.rights, entre otras posibilidades. Sólo es utilizada por Süddeutsche Zeitung (101) y no se recoge en la Tabla que sigue. También se ha encontrado un caso de uso de la etiqueta <acronym title="...">...</acronym>, por The Financial Times (123), dónde el valor del atributo “title” es el nombre del medio. Esta etiqueta ya no es soportada en HTML5 y ha sido reemplazada por <abbr>, sin uso en la muestra.
- Finalmente, The New York Times (201), como con el autor de la noticia, usa una misma línea para hacer referencia a tres atributos, poseedor del copyright de la noticia, proveedor de la noticia y organización fuente, con el mismo valor (WHATWG, 2016a): <span itemprop="copyrightHolder provider sourceOrganization" itemscope itemtype="http://schema.org/Organization" itemid="...">.
La tabla 9 resume los esquemas identificados para el nombre del medio.
| Línea de código | Tipo de esquema | N | |
|---|---|---|---|
| <acronym title="...">...</acronym> | Estándar (HTML) | 1 | |
| <meta property="og:site_name" content="..."> | Estándar (OG) | 16 | 22 |
| <meta property="article:publisher" content="..." /> | 6 | ||
| <span id="publisher" itemprop="Publisher" ...>...</span> <meta itemprop="publisher" content="..."> <div class="logo" itemscope itemprop="publisher" itemtype="http://schema.org/Organization">...</div> |
Estándar (SC) | 4 | 6 |
| <span itemprop="copyrightHolder provider sourceOrganization" itemscope itemtype="http://schema.org/Organization" itemid="...">...</span> <div itemscope itemprop="copyrightHolder" itemtype="http://schema.org/Organization">...</div> <meta itemprop="name" content="..."> |
2 | ||
| <meta name="twitter:site" content="..." /> <meta name="twitter:site" value="..." /> |
Estándar (TC) | 10 | |
| <meta name="DC.publisher" content="..."> | Estándar (DC) | 1 | |
| <meta name="cre" content="..." /> | Propietario (201) | 1 | |
| <meta name="page.site" content="wsj" /> | Propietario (201) | 1 | |
Igual que ocurre con el autor, existe un atributo rel=”publisher”, que indica que el dato que aparece en la etiqueta, habitualmente una página web o el perfil de alguna red social del medio, se refiere a un publicador. Véase, por ejemplo, <a href="https://plus.google.com/+arabnews" rel="publisher" ...>, de Arab News (701). No se ha tenido en cuenta en la tabla anterior.
Para este metadato no se identificó ningún metadato en Nigerian Tribune (501), China Daily (601), Arab News (701) ni en Gulf News (711).
El software MetadadosHTML.
Dada la diversidad de notaciones identificadas para los distintos datos, se desarrolló un software para la extracción de información de la muestra de noticias en HTML, almacenadas inicialmente en una hoja de cálculo. Para la base de datos se utilizó Microsoft Access. De esta forma, esposible mantener disponible en el tiempo la información extraída para su consulta. Para la construcción del algoritmo se utilizó el lenguaje Object Pascal. La primera etapa consistió en la construcción de una base de datos, compuesta por tres Tablas (tabla 10), que facilitara la relación entre sus elementos. En esta etapa también se importaron los datos de la hoja de cálculo a la Tabla URL.
| Nombre de la tabla | Objetivo |
|---|---|
| URL | Almacenar las direcciones (URLs) de las noticias |
| Tags | Almacenar las etiquetas meta y atributos que se desean extraer |
| Metadados | Almacena el contenido de las etiquetas meta y atributos de la Tabla Tags |
Posteriormente, a partir del análisis previo, se registraron etiquetas meta y atributos en la tabla Tags. Este proceso conlleva un importante esfuerzo pues, como ya se ha indicado, los periódicos optaron por notaciones diferentes, sin seguir un patrón, a veces, en formato propietario. Con esta infraestructura, se inició el desarrollo propiamente dicho del software.
MetadadosHTML tiene tres funcionalidades:
- Acceso al código fuente de las URLs contenidas en la hoja de cálculo inicial. Debido al gran número de URLs, se descargaron todos los códigos HTML de las noticias en local, de forma que su análisis fuera realizado sin necesidad de acceder de nuevo a las páginas web. De esta forma se favorece la independencia de la conexión de datos y mayor velocidad de procesamiento posterior.
- Definición de las etiquetas meta y atributos de cada medio, teniendo en cuenta sus particularidades y formatos. Esta realiza el análisis del documento para la extracción de los valores de dato deseados. Debido a la ausencia de patrones de notación en parte del corpus seleccionado, hubo una dificultad adicional para la extracción de información. La estrategia adoptada para resolver este problema fue, junto a las etiquetas meta y atributos de la Tabla Tags, la inclusión de los marcadores de inicio y fin de cada elemento. El objetivo es relacionarlos en el algoritmo por el nombre. Esto sería suficiente para documentos bien formados y válidos según la notación W3C.
- Extracción del contenido de los códigos fuente, exportación a una hoja de cálculo y almacenamiento para su consulta y análisis posterior.
La figura 8 muestra una captura de pantalla de la aplicación MetadadosHTML.
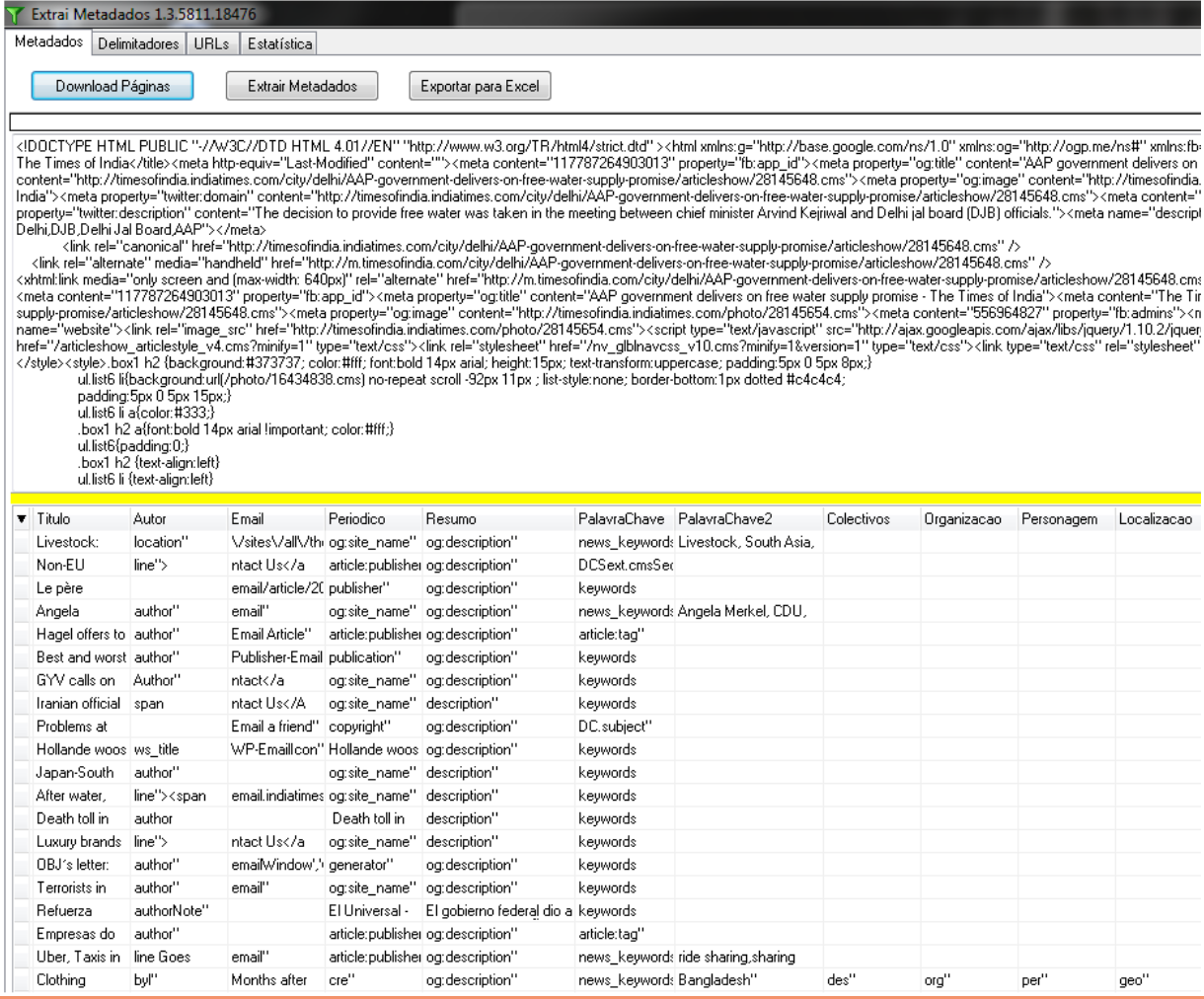
Los datos extraídos reflejan la variabilidad de la problemática descrita anteriormente, con campos vacíos, porque no son utilizados por un periódico, o ruido informativo por la inclusión de datos que no corresponden al metadato que se analiza.
| Orden | Línea de código | Medios de dónde extraer | Nota |
|---|---|---|---|
| 1 | <meta name="keywords" content=""> | 101; 121; 123; 202; 311; 401; 601; 602; 603; 701; 711; 721 | Para 201 se utiliza 4, 5, 6 y 7 Campo repetible en 701 |
| 2 | <meta name="news_keywords" content=""> | 122; 731; 801 | Para 201 se utiliza 4, 5, 6 y 7 |
| 3 | <meta property="article:tag" content="" /> | 301; 901 | Campo repetible |
| 4 | <meta name="des" content=”" /> | 201 | Palabras clave |
| 5 | <meta name="org" content=”" /> | 201 | Organizaciones |
| 6 | <meta name="per" content=”" /> | 201 | Personas |
| 7 | <meta name="geo" content=”" /> | 201 | Lugares |
Una posible solución pasa por establecer un orden de extracción, en el que se defina, en cada periódico, qué esquema utilizar y con qué condiciones (repetición del proceso, por ejemplo). La tabla 11 indicaría el orden de extracción para las palabras clave.
Conclusiones.
La literatura sobre estructuras para la descripción de documentos y sobre cómo aplicarlos en sistemas de información es abundante (véanse las numerosas referencias sobre ISBD, MARC, FRBR, EAD y DC, por ejemplo (Chen and Ke, 2013; Hillman, 2005). Sin embargo, son pocos los trabajos que, como (Rovira and Marcos, 2006), analizan el uso de estos esquemas, menos en los códigos fuente de documentos web. Tampoco abundan las aportaciones que ahondan en las prácticas de aplicación de estos esquemas, como el ya citado (Rovira and Marcos, 2006), ó (Chuttur, 2014), que destaca la reducción del número de errores cuando, en la asignación de metadatos se usan códigos de buenas prácticas. Ya en el área de medios de comunicación impresa, (Valdés Pérez, Alemán Jiménez, and García Rivas, 2016), entre otras cuestiones, analizan la descripción de sitios de prensa cubana con metadatos y subrayan que, menos de un tercio de los portales analizados utilizan meta-etiquetas correctamente. Este trabajo aporta nuevas evidencias sobre el estado actual de la descripción de noticias web mediante metadatos. Asimismo, puede resultar útil para mejorar la precisión en la recuperación de noticias web en sistemas de información y su detección por web crawlers, programas de rastreo de páginas web a través de sus enlaces que actúan sobre el código fuente de las páginas web (Blázquez Ochando, 2013).
La variedad de esquemas de metadatos hallados en los códigos fuente puede considerarse ligada a los distintos propósitos por los que se desarrollan y utilizan: 1) Facilitar la interoperabilidad entre sistemas mediante elementos puestos en común, como schema.org (SC) o Dublin Core (DC); 2) Optimizar la búsqueda y recuperación de información en motores, como las etiquetas meta keywords, news_keywords o los esquemas de The New York Times, The Wall Street Journal; 3) Mejorar la visualización de la información a través de redes sociales (esencialmente Facebook y Twitter); 4) Realizar acciones de seguimiento y analítica web, como Sailthru o Webtrends. Esta variedad de esquemas, con distintos grados de aplicación, muestra que ningún estándar ha logrado la aceptación global. Por tanto, sigue siendo necesario avanzar hacia ‘estándares para que los datos estén disponibles en distintos formatos, que hagan más versátil su reutilización’ (Pastor Sánchez, 2016). La evolución en la implantación de esquemas de metadatos o, mejor aún, su uso generalizado, es una de las cuestiones que marcará el camino hacia el intercambio y recuperación de información en y entre sistemas, sin importar el cambio
de tecnología. Para ello, se debe trabajar en que los metadatos sean: únicos, estables, seguros, de acceso público y persistentes (Vásquez Paulus, 2008). En este sentido, (García-Marco, 2013) destaca dos esquemas fundamentales como candidatos: a) schema.org, cuyo uso va extendiéndose en la descripción física y semántica de documentos web; b) Dublin Core (DC), bien asentado en la comunidad científica, ya utilizado para diversos tipos de documentos, como revistas científicas (Felipe, 2016), el más estable y extendido, y aspirante preferente para la descripción de recursos digitales (Piedra et al., 2015; Vásquez Paulus, 2008).
Una segunda conclusión tiene que ver con la calidad de los metadatos, esto es, con la forma de expresar los valores de datos. Se han encontrado prácticas divergentes como el uso de una o varias líneas de código, la inclusión de un valor en un dato que no corresponde (nombre del medio entre las palabras clave, por ejemplo). Esto, de nuevo, dificulta la extracción de información, por cuanto es necesario no sólo conocer esquemas y atributos para cada tipo de información y periódico, también qué prácticas sigue cada medio. Además, se ha observado que algunos periódicos cometen errores al referir los nombres de los atributos de esquemas estandarizados, lo que impediría la extracción de información siguiendo los esquemas. Resulta, por tanto, imprescindible la adopción de buenas prácticas en el marcado de las noticias, en la forma en que los estándares lo indican. Una buen comienzo sería explicitar qué esquemas de metadatos utilizan los periódicos, documentando qué se utiliza y cómo, con textos explicativos y espacios de nombre. En definitiva, se trata de crear una cultura de metadatos (Vásquez Paulus, 2008).
En cuanto a MetadadosHTML, en su estado actual, está limitado por posibles cambios en los códigos fuente de los medios. Si un periódico redefine alguna de sus etiquetas meta o comienza a utilizar un nuevo esquema, el software no puede aprovecharlas, lo que obliga a una continua revisión. Por otro lado y, en relación con las conclusiones antes indicadas, ejemplifica la dificultad de recoger todos los metadatos de códigos fuente, pues no siempre están disponibles, no se (re)conocen los esquemas utilizados o no siguen pautas comunes en la adición de los valores de dato. De acuerdo con esto, se debería definir una política de indización común entre los periódicos, que esté alineada con los principales estándares de metadatos. Es evidente que la simple adopción de metadatos no es suficiente para el descubrimiento y accesibilidad de los documentos. En muchos sistemas de recuperación de información dichos documentos no serán objeto de análisis ni de indización. Los resultados iniciales llevan al establecimiento de un orden de preferencia en la extracción de valores de datos de unos esquemas frente a otros. Ello modificaría el software teniendo en cuenta frecuencia de uso de los esquemas y el grado de normalización de las prácticas de cada medio. El propósito es asegurar la correcta extracción y mayor cantidad de valores de datos con el menor número de procesos.
Sobre los autores
María-José Baños-Moreno, becaria predoctoral en el Doctorado en Gestión de la Información y de la Comunicación en las Organizaciones, Departamento de Ingeniería de la Información y las Comunicaciones, Facultad de Informática de la Universidad de Murcia, Campus de Espinardo, C.P. 30100, Murcia, + 34 868888787, mbm41963@um.es. ORCID No. orcid.org/0000-0001-9137-1330
Eduardo R. Felipe, mestrado em Ciências da Informação, Escola de Ciência da Informação, Universidade Federal de Minas Gerais, da UFMG, Avenida Antônio Carlos, 6627 - Pampulha, Belo Horizonte - MG, 31270-901, Brasil, +55 31 3409-5249, erfelipe@hotmail.com
Gercina Lima, professor adjunto da Universidade Federal de Minas Gerais e Coordenadora do Programa de Pós Graduação em Ciência da Informação da ECI/UFMG, Escola de Ciência da Informação, Universidade Federal de Minas Gerais, da UFMG, Avenida Antônio Carlos, 6627 - Pampulha, Belo Horizonte - MG, 31270-901, Brasil, +55 31 34095232, glima@eci.ufmg.br. ORCID No. orcid.org/0000-0003-0735-3856
Juan Antonio Pastor-Sánchez, profesor contratado doctor del Departamento de Información y Documentación de la Universidad de Murcia, Facultad de Comunicación y Documentación de la Universidad de Murcia, Campus de Espinardo, C.P. 30100, Murcia, pastor@um.es, +34 868 887252. ORCID No. orcid.org/0000-0002-1677-1059
Rodrigo Martínez-Béjar, Catedrático, Departamento de Ingeniería de la Información y las Comunicaciones, Facultad de Informática de la Universidad de Murcia, Campus de Espinardo, C.P. 30100, Murcia, + 34 868888787, rodrigo@um.es. ORCID No. orcid.org/0000-0002-9677-7396
Introduction.The objectives of this work are to determine which schemes are used for title, abstract, keywords, authorship and newspaper in press; to know what guidelines newspapers follow in the implementation of these schemes; and to find out how this affects the extraction of information.
Methodology. For this purpose, a newspaper sample is defined and its source code is analysed, identifying the schemas used and usage patterns. This allows us to extract data values using the MetadadosHTML application.
Results. Standard, ad hoc and newspaper schemes have been detected. Various practices have been found, such as values grouped in the same line of code or separately; noise in a value; and errors when referring to the names of the attributes of standard schemas. These issues affect data extraction based on metadata and metadata schemas in MetadadosHTML
Conclusions. It is necessary to make progress in the use of standard schemas such as Dublin Core or schema.org, favouring the implementation of these (or others) in the news source codes. It is also imperative to adopt good practices in making explicit data and data values. Only in this way is it possible to evolve interoperability between systems and the retrieval and reuse of information.
References
- Abadal, E., & Codina, L. (2009). Bases de datos documentales. Características, funciones y método. Madrid: Síntesis.
- Abbud Grácio, J. C., & Fadel, B. (2010). Estratégias de preservação digital. In Gestão, mediação e uso da informação (pp. 58–83). São Paulo: Editora UNESP; Cultura Acadêmica. Retrieved from http://books.scielo.org/id/j4gkh/pdf/valentim-9788579831171-04.pdf (Archived by WebCite® at http://www.webcitation.org/6mIsBSOPu)
- AENOR. (2012). Información y documentación. Metadatos para la gestión de documentos. Parte 3: Método de auto-evaluación. UNE-ISO/TR 23081-3. AENOR.
- Axelsson, J., Birbeck, M., Dubinko, M., Epperson, B., Ishikawa, M., McCarron, S., Pemberton, S. (Eds.). (2006). XHTML 2.0 (W3C Working Draft 26 July 2006). W3C. Retrieved from http://www.w3.org/TR/2006/WD-xhtml2-20060726. (Archived by WebCite® at http://www.webcitation.org/6mItkzTcv)
- Baños-Moreno, María-José, Felipe, E. R., Pastor-Sánchez, J. A., Martínez-Béjar, Rodrigo, & Lima, G. (2015). Metadatos en noticias: un análisis internacional para la representación de contenidos en periódicos. Presented at the II Congreso ISKO España y Portugal / XII Congreso ISKO, Facultad de Comunicación y Documentación, Universidad de Murcia, Murcia (España). Retrieved from http://www.iskoiberico.org/wp-content/uploads/2015/11/43_Ba%C3%B1os.pdf (Archived by WebCite® at http://www.webcitation.org/6mItul0Zm)
- Baños-Moreno, M. J., Pastor-Sánchez, J. A., & Martínez-Béjar, R. (2013). Propuesta de actualización de macro-tesauros a partir de noticias de divulgación científico-tecnológica. In Informação e/ou Conhecimento: as duas faces de Jano (pp. 99–112). Porto (Portugal): Faculdade de Letras da Universidade do Porto / CETAC.MEDIA. Retrieved from http://hdl.handle.net/10760/20684 (Archived by WebCite® at http://www.webcitation.org/6mIu20sMG)
- Baptista, A. A., & Barbosa Machado, A. (2001). Metadata usage in an online journal - an application profile. In A. Hübler, P. Linde, & J. W. . Smith (Eds.), Electronic Publishing ’01 - 2001 in the Digital Publishing Odyssey (pp. 59–64). Kenterbury, UK: University of Kent. Retrieved from http://elpub.scix.net/cgi-bin/works/Show?200106 (Archived by WebCite® at http://www.webcitation.org/6mIu9aivT)
- BI3D. (2013). Believe in 3D! [Video de Youtube]. Retrieved from https://www.youtube.com/user/BelieveIn3D (Archived by WebCite® at http://www.webcitation.org/6nnp1tX1b)
- Blázquez Ochando, M. (2013). Nuevos retos de la tecnología web crawler para la recuperación de información. MÉI: Métodos de Información, 4(7), 115–128. Retrieved from https://dialnet.unirioja.es/servlet/articulo?codigo=4767039 (Archived by WebCite® at http://www.webcitation.org/6mKsd4M3a)
- Bohannon, P., Dalvi, N., Filmus, Y., Jacoby, N., Keerthi, S., & Kirpal, A. (2012). Automatic Web-scale Information Extraction. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data (pp. 609–612). New York, NY, USA: ACM.
- Burgués, M. (2009, February 20). Obtención automática de metadatos de páginas Web para mejorar la ordenación de los resultados de una búsqueda. Rosario (Argentina). Retrieved from http://rephip.unr.edu.ar/xmlui/handle/2133/3252 (Archived by WebCite® at http://www.webcitation.org/6mKssmHLz)
- Chen, Y. N., & Ke, H. R. (2013). FRBRoo-based approach to heterogeneous metadata integration. Journal of Documentation, 69(5), 623–637.
- Chuttur, M. Y. (2014). Investigating the effect of definitions and best practice guidelines on errors in Dublin Core metadata records. Journal of Information Science, 40(1), 28–37.
- Díaz, L., Granell, C., Beltrán Fonollosa, A., Llaves, A., & Gould, M. (2008). Extracción semiautomática de metadatos: hacia los metadatos implícitos. In Actas de las II Jornadas de SIG Libre. Girona, Spain: Mar. Retrieved from http://hdl.handle.net/10256/1160 (Archived by WebCite® at http://www.webcitation.org/6mKt8U3Ax)
- Felipe, E. R. (2016). A importância dos metadados em bibliotecas digitais da organização à recuperação da informação. In Biblioteca digital hipertextual. Caminhos para a Navegação em Contexto (pp. 159–180). Rio de Janeiro: Interciência.
- García-Marco, F. J. (2013). Schema.org: la catalogación revisitada. Anuario ThinkEPI, 7(0), 169–172.
- Garshol, L. M. (2004). Metadata? Thesauri? Taxonomies? Topic Maps! Making sense of it all. Journal of Information Science, 30(4), 378–391.
- Google Inc. (2016). Ayuda para editores: Palabras clave y consultas de búsqueda. Retrieved from https://support.google.com/news/publisher/answer/68297?hl=es (Archived by WebCite® at http://www.webcitation.org/6mKtPjoPL)
- Guallar, J., Abadal, E., & Codina, L. (2012). Hemerotecas de prensa digital. Evolución y tendencias. El Profesional de La Información, 21(6), 595–605. Retrieved from http://hdl.handle.net/10760/18199 (Archived by WebCite® at http://www.webcitation.org/6mKtVH1I9)
- Guallar, J., Abadal, E., & Codina, L. (2016). Hemerotecas digitales de prensa. In Calidad en sitios web. Método de análisis general, e-Commerce, imágenes, hemerotecas y turismo (pp. 129–152). Barcelona: UOC.
- Harris, J. (2007, October 23). Messing around with metadata. [Web log entry]. New York Times. Retrieved from http://open.blogs.nytimes.com/2007/10/23/messing-around-with-metadata/ (Archived by WebCite® at http://www.webcitation.org/6mKtbX12J)
- Hickson, I., Berjon, R., Faulkner, S., Leithead, T., Navara, E. D., O’Connor, E., & Pfeiffer, S. (Eds.). (2014, October 28). HTML5. A vocabulary and associated APIs for HTML and XHTML (W3C Recommendation 28 October 2014). W3C. Retrieved from https://www.w3.org/TR/html5/document-metadata.html#the-meta-element (Archived by WebCite® at http://www.webcitation.org/6mKtfYne4)
- Hillman, D. (2005, November 7). Using Dublin Core (DCMI Recommended Resource). Retrieved from http://dublincore.org/documents/usageguide/ (Archived by WebCite® at http://www.webcitation.org/6mKtmZzXl)
- Janes, D. (2013, August). hAtom 0.1 [Draft Specification]. Retrieved from http://microformats.org/wiki/hatom (Archived by WebCite® at http://www.webcitation.org/6mKtpzT0k)
- Kallipolitis, L., Karpis, V., & Karali, I. (2012). Semantic search in the World News domain using automatically extracted metadata files. Knowledge-Based Systems, 27(1), 38–50.
- Lajusticia, M. R. B. (2000). Estructura textual, macroestructura semántica y superestructura formal de la noticia. Estudios sobre el mensaje periodístico, (6), 239–258. Retrieved from http://dialnet.unirioja.es/servlet/articulo?codigo=184782 (Archived by WebCite® at http://www.webcitation.org/6mKu5H6vL)
- Leitlhead, T., Pfeiffer, S., Navara, & O’Connor, E. (Eds.). (2012, August 22). HTML5. A vocabulary and associated APIs for HTML and XHTML (Editor’s Draft 22 August 2012). W3C. Retrieved from http://dev.w3.org/html5/spec-preview/Overview.html#contents
(Archived by WebCite® at http://www.webcitation.org/6mKuAh69j) - Ortiz-Repiso Jiménez, V. (1999). Nuevas perspectivas para la catalogación: Metadatos Versus Marc. Revista española de Documentación Científica, 22(2), 198–219. Retrieved from http://redc.revistas.csic.es/index.php/redc/article/view/338/546 (Archived by WebCite® at http://www.webcitation.org/6oFpBAdwG)
- Parker, A. (2016, February 14). Jeb Bush adds a weapon (his brother) despite worries it could misfire. New York Times. Retrieved from http://www.nytimes.com/2016/02/15/us/politics/jeb-bush-uses-secret-weapon-his-brother-despite-worries-it-could-misfire.html (Archived by WebCite® at http://www.webcitation.org/6mKuKYdDY)
- Parse.ly. (s.f.). Technical documentation. The metadata tag. Retrieved from https://www.parsely.com/docs/integration/metadata/jsonld.html (Archived by WebCite® at http://www.webcitation.org/6mKuP2ZJI)
- Pastor Sánchez, J. A. (2016, January 29). Quince años de web semántica: de las tecnologías a las buenas prácticas. IWETEL. Retrieved from https://listserv.rediris.es/cgi-bin/wa?A2=IWETEL;4919cf48.1601E (Archived by WebCite® at http://www.webcitation.org/6mKuU29rd)
- Pastor-Sánchez, J. A. (2011). Tecnologías de la web semántica (Edición: 1). Barcelona: Editorial UOC, S.L.
- Pereira, T., & Baptista, A. A. (2004). Incorporating a semantically enriched navigation layer onto an RDF metadatabase. In J. Engelen, S. M. S. Costa, & A. C. S. Moreira (Eds.), Building digital bridges: linking cultures, commerce and science. Brasília. Retrieved from http://repositorium.sdum.uminho.pt/handle/1822/604 (Archived by WebCite® at http://www.webcitation.org/6mKuZsoDv)
- Piedra, N., Chicaiza, J., Quichimbo, P., Saquicela, V., Cadme, E., López, J., … Tovar, E. (2015). Marco de Trabajo para la Integración de Recursos Digitales Basado en un Enfoque de Web Semántica. RISTI - Revista Ibérica de Sistemas e Tecnologias de Informação, (spe3), 55–70.
- Rovira, C., & Marcos, M. C. (2006). Metadatos en revistas-e de Documentación de libre acceso. Retrieved from http://eprints.rclis.org/9343/ (Archived by WebCite® at http://www.webcitation.org/6mKujdb0h)
- Sailthru. (2013, October 1). Custom Horizon Tags. Retrieved from http://getstarted.sailthru.com/site/horizon-overview/custom-horizon-tags/ (Archived by WebCite® at http://www.webcitation.org/6mKumGv3m)
- Valdés Pérez, H. L., Alemán Jiménez, Y., & García Rivas, D. (2016). Evaluación de la prensa digital cubana respecto a la optimización de motores de búsqueda. Serie científica, 9(5), 58–60. Retrieved from http://publicaciones.uci.cu/index.php/SC/article/view/1766 (Archived by WebCite® at http://www.webcitation.org/6mKwNpd00)
- Vallez, M., Rovira, C., Codina, L., & Pedraza-Jiménez, R. (2010). Procedimientos para la extracción de palabras clave de páginas web basados en criterios de posicionamiento en buscadores. Hipertext.net, 8. Retrieved from http://www.upf.edu/hipertextnet/numero-8/extraccion_keywords.html (Archived by WebCite® at http://www.webcitation.org/6mKuy6oWw)
- Vásquez Paulus, C. (2008). METADATOS: Introducción e historia. Retrieved from https://users.dcc.uchile.cl/~cvasquez/introehistoria.pdf (Archived by WebCite® at http://www.webcitation.org/6mKv1WyKU)
- Web Hypertext Application Technology Working Group (WHATWG). (2016a, February 4). Microdata. Retrieved from https://html.spec.whatwg.org/multipage/microdata.html#names:-the-itemprop-attribute (Archived by WebCite® at http://www.webcitation.org/6mKv6eQSe)
- Web Hypertext Application Technology Working Group (WHATWG). (2016b, February 4). Standard metadata names. Retrieved from https://html.spec.whatwg.org/multipage/semantics.html#standard-metadata-names (Archived by WebCite® at http://www.webcitation.org/6mKvAG02K)
- Yaginuma, T., Pereira, T., & Baptista, A. A. (2003a). Design of metadata elements for digital news articles in the omnipaper project. In S. M. de Souza Costa, J. A. Carvalho, A. A. Baptista, & A. C. Santos Moreira (Eds.), From information to knowledge: 7th ICCC/IFIP International Conference on Electronic Publishing (pp. 132–139). Minho, Portugal: Universidade do Minho. Retrieved from http://repositorium.sdum.uminho.pt/handle/1822/170 (Archived by WebCite® at http://www.webcitation.org/6mKvFExb7)
- Yaginuma, T., Pereira, T., & Baptista, A. A. (2003b). Metadata elements for digital news resource description. In Proceedings CLME’2003 - 3o Congresso Luso-Moçambicano de Engenharia (pp. 1317–1326). Maputo. Retrieved from http://repositorium.sdum.uminho.pt/handle/1822/279 (Archived by WebCite® at http://www.webcitation.org/6mKvJVT2w)