A proposed methodology for the conceptualisation, operationalisation, and empirical validation of the concept of information need
Waseem Afzal
Introduction. The purpose of this paper is to propose a methodology to conceptualize, operationalize, and empirically validate the concept of information need.
Method. The proposed methodology makes use of both qualitative and quantitative perspectives, and includes a broad array of approaches such as literature reviews, expert opinions, focus groups, and content validation. It also involves sophisticated assessment of construct validity including substantive and structural aspects.
Analysis. Research on conceptualization and assessment of information need presents a rich tradition. To further enhance the scope of this, a methodology is proposed; a variant of the methodology proposed in this paper has been used in other disciplines with promising results.
Results. Ways in which this methodology can be applied to the concept of information need are demonstrated. Some challenges associated with this methodology are noted, such as significant investments of time and labour.
Conclusions. It is hoped that using this methodology in future studies will be an important step towards developing an empirically testable construct of information need. This approach will also be a useful addition to the methodological repertoire available to information researchers.
Introduction
Human information behaviour is of great significance in information research, and within human information behaviour research, the concept of information need is of particular importance (e.g., Case, 2012). Information need can be considered a precursor for a range of information behaviour types, including seeking, searching, and use. Information need has been defined as an anomalous state of knowledge (Belkin, Oddy, and Brooks, 1982), a gap in knowledge (Dervin and Nilan, 1986), or a feeling of uncertainty (Kuhlthau, 1991).
The importance attributed to information need may be caused by the user-centred nature of information research and the traditions of cognate disciplines. For instance, Naumer and Fisher (2010) noted that without information need, libraries and information systems would cease to exist. Similarly, it is nearly impossible to ignore the work done on need and information need in the disciplines of psychology, nursing, economics, and political science. However, despite its importance and long-standing presence in research, the concept is still contested (e.g., Case, 2012; Dervin and Nilan, 1986; Krikelas, 1983; Wilson, 1981, 1994). Not only are there divergent views about what comprises an information need, there is also a lack of consensus concerning the role of information need in shaping human information behaviour.
Numerous studies have examined information need in general, as well as the particular needs of individuals and of various user groups (e.g., Bertulis and Cheeseborough, 2008; Perley, Gentry, Fleming, and Sen, 2007; Shpilko, 2011). However, these studies do not create a coherent body of research on which a testable theory of human information behaviour could be developed. A possible reason for this is an apparent lack of conceptualisation and operationalization of constructs relevant to human information behaviour, including the construct of information need. The purpose of this paper is to attempt to partially fill this gap by proposing a methodology to conceptualise, operationalise, and empirically validate the concept of information need.
Significance of this methodology
According to Jaccard and Jacoby (2010), theory construction is central to the scientific process. They describe theory as a symbolic representation of an internal conceptual system. Greer, Grover, and Fowler (2007) state that theory enables us to describe, predict, and explain a phenomenon. The construction of theory usually requires abstraction of a phenomenon (known as conceptualisation) and then transfer of that abstraction to constructs that can be validated. Currently, there is a dearth of such constructs in human information behaviour, and by undertaking this step the current study will make an important contribution to any future testable human information behaviour theory.
The use of this methodological approach – based on the positivist paradigm, and involving assessment of substantive and structural aspects of constructs as espoused by Loevinger (1957) –as is proposed in this paper, has not been used in information research and thus will be a valuable addition to the methodological repertoire available to studies that aim to develop constructs. Variations of this approach have been used successfully in other social science disciplines, for example psychology (e.g., Wallander, Schmitt and Koot, 2001) and information systems (e.g., Moore and Benbasat, 1991), and two important examples of this approach in information research are McCay-Peet,Toms and Kelloway (2014), and O’Brien and Toms (2010). The application of this methodological approach in information research would enable researchers to develop formal constructs in human information behaviour research, focus on new research problems, and ask new kinds of research questions. Specifically, applying this methodology in future studies would be an important step towards developing a testable human information behaviour theory comprised of constructs based on rigorous conceptualisation, operationalisation, and empirical validation.
Background
Conceptualisation and operationalisation of information need in information research
There is a significant body of work in information research on the notion of information need. For example, studies have examined the concept of information need (e.g., Belkin, 1980, 1993; Belkin, Oddy, and Brooks, 1982; Cole, 2012; Derr, 1983; Dervin and Nilan, 1986; Kuhlthau, 1991; Line, 1974; Savolainen, 2012; Sundin and Johannisson, 2005; Taylor, 1962, 1968), its accidental precursors (e.g., Williamson, 1998), and broader information seeking and searching environments in which information need is developed or a pre-existing information need is satisfied (e.g., Bates, 2002). There is also a growing corpus of studies that have researched the processes involved in satisfying information needs (e.g., Odongo and Ocholla, 2003; Shenton and Dixon, 2004). Numerous studies have attempted to measure information need (e.g., Inskip, Butterworth, and MacFarlane, 2008; Perley et al., 2007; Pitts, Bonella, and Coleman, 2012; Shpilko, 2011). While none of this research has developed a testable construct, a number of authors have explored different aspects of information need. The following discussion considers some of the various dimensions of information need captured in the research literature.
Taylor (1962) brought the relationship between question and information need into focus. He suggested that a question triggers an information need, and proposed four levels of information need. The first level represents the visceral need (the actual but unexpressed information need), and the fourth level represents the compromised need (the question as presented to the information system; p. 392). By proposing this hierarchical progression, Taylor implicitly demonstrated the dynamic nature of information need. His work shed light on the ways in which an information need develops, changes, and is influenced by factors like expectations, motivations, and information system attributes.
Lack of clarity around the concept of information need was noted by Line (1974). For instance, he observed that there had been an imprecise use of terms in the literature on information need. Specifically, studies claiming to be examining needs in fact examined uses or demands. Line differentiated the terms need, want, demand, and use, and suggested using the term requirement. He was of the opinion that requirement is a more inclusive category that includes need, want, and demand.
Derr’s (1983) work is important in understanding the concept of information need. He suggested that two conditions should be present to recognise information need: (1) a genuine or legitimate information purpose and (2) a judgment that the requisite information will be effective in meeting that information purpose. Derr also questioned the utility of the concept of information need and suggested instead using the concept of information want. However, he considered even that concept problematic and suggested the use of the term question. Although his work does not provide a conclusive conceptual scheme to use in future efforts, it is important for realising the challenges associated with the conceptualisation of information need.
Another important work on information need is Cole’s (2012), in which he recognised both the importance of information need and its conceptual complexity. He used perspectives from computer science (input–output) and information science (information–knowledge) to explain the concept of information need and develop his theory regarding it. In the input–output perspective, the purpose of an information need is to find an answer: the query represents an input and the answer represents an output from a system. The information–knowledge perspective represents a broader view presenting an information need as a gateway to the flow of information, which may or may not address the need at hand.
Savolainen (2012) highlighted the importance of contextual factors while conceptualising information need. He performed concept analysis of approximately fifty papers and books to come up with three major contexts influencing information and information need: (1) situation of action, (2) task performance, and (3) dialogue. According to Savolainen, the information need in each context can be understood differently. For example, in a situation of action, information need is a 'black-boxed trigger and driver of information seeking'; in task performance, information need is a 'derivative category indicating information requirements…'; and under the dialogue, information need is a 'jointly constructed understanding about the extent to which additional information is required to make sense of the issue at hand'.
Beyond the theoretical and conceptual work discussed above, information need has been assessed in numerous studies: for example, Inskip et al., (2008); Perley et al., (2007); Shpilko, (2011). Perley et al. assessed information needs of physicians, clinicians, and non-clinical staff at a large medical centre in a Midwestern US city. They used both quantitative and qualitative approaches, including self-administered questionnaires, telephone interviews, and focus group interviews. Examination of this study’s survey instrument reveals that the majority of questions aimed at getting information about accessing, searching, and using information sources. Although there were interview questions and focus group protocols to elicit more pertinent information about users’ information needs, the heavy focus on the use of library resources overshadowed the assessment of information need.
Inskip et al. (2008) analysed the information needs of users of a folk music library in London. They used the information needs framework proposed by Nicholas (2000) to conduct the needs assessment. Semi-structured interviews were used to collect data from four user groups. Based on analyses of the questions asked and data collected, it can be argued that the major focus of this study was on information uses and sources rather than information needs assessment. In another study, Shpilko (2011) studied the information seeking and needs of a university faculty teaching nutrition, food science, and dietetics at a state university in the USA. A survey questionnaire was sent to twenty-nine faculty members asking them about information sources they consulted, including the top five journals they used for current awareness, the top five journals they used for research and teaching, and the methods used by participants to find information. As was the case with Inskip et al. (2008), this study attempted to assess users’ information needs by examining the kinds of information sources they were accessing and using.
Many empirical studies purporting to assess information needs end up analysing users’ access to information sources. This observation was echoed by Spink and Cole (2006) in the case of research on information use assessment. They noted that in some information need and use research, there is a reliance on users’ accessing channels of information to measure information use.
Proposed methodology
The research problem in this paper requires the use of both qualitative and quantitative methods. For instance, the conceptualisation of a construct entails close examination of meanings, awareness of peoples’ everyday understanding of the concept, and analysis of the literature and relevant knowledge bases to determine the dimensions to be included in the construct. The operationalisation and empirical validation involve assessing validity and reliability through techniques such as exploratory factor analysis and reliability analysis. Keeping in view the objectives and the nature of the research problem, this research methodology draws on the positivist research paradigm and uses techniques involving both qualitative (substantive) and quantitative (structural) aspects (seen in Figure 1 and explained below).
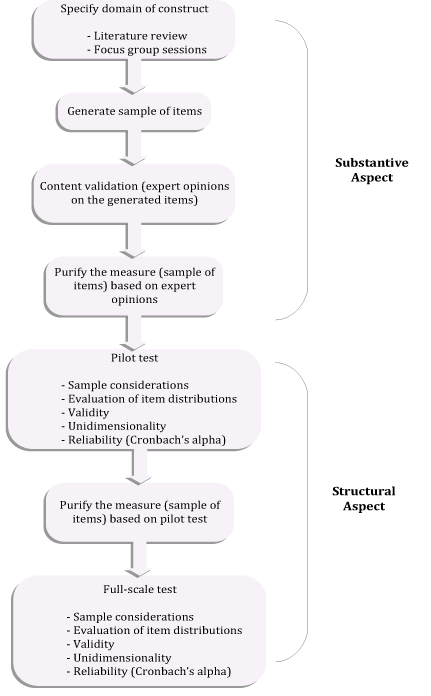
Figure 1: Proposed methodology
As noted earlier, the proposed methodological approach has been used in other disciplines, including psychology, marketing, and information systems. The work of Moore and Benbasat (1991) is an important example of the application of this approach in the information systems discipline. Their work examined the concepts of relative advantage, compatibility, complexity, observability, and trialability. Those concepts were proposed by Rogers (1983), who argued that they influence the adoption of any innovation. Moore and Benbasat developed a validated instrument to measure perceptions of the concepts. They started with a review of the literature relating to the concepts and examined instruments that had been used in previous attempts to operationalise them. Following this phase, three additional steps were taken: (1) items creation, (2) instrument development, and (3) instrument testing. After the first step, content and construct validity were assessed. Following those assessments, the initial instrument operationalising the concepts was refined and pilot tested. Finally, the instrument was re-tested through a full-scale test that included validity and reliability assessment. Agarwal and Prasad (1997) noted that Moore and Benbasat subjected their instrument ‘to an intensive validation procedure to determine reliability and validity’ (p. 567).
Moore and Benbasat’s work has had a far-reaching impact on the research in the domain of information systems and beyond, and has been used extensively in subsequent research. For example, their approach has been used in a variety of research settings, including the study of online auction users (Turel, Serenko, and Giles, 2011) and mobile banking adoption (Lin, 2011), and in developing a unified view of user acceptance of information technology (Venkatesh, Morris, Davis, and Davis, 2003).
The current paper also relies heavily on the works of Loevinger (1957), Churchill (1979), Clark and Watson (1995), DeVellis (2003), and Worthington and Whittaker (2006) to develop the overall methodological approach, and various additional works such as Hair, Black, Babin, Anderson and Tatham (2006), Field (2005), Hattie (1985), and Lawshe (1975) have been consulted to develop empirical guidelines pertaining to different phases of the proposed methodology. Drawing on the work of Loevinger (1957), it can be argued that the proposed methodological approach has two main aspects: substantive and structural. The substantive aspect deals with the identification of content relevant to the concept under study, whereas the structural aspect deals with the choice of items from the content. According to Loevinger, the identification of content should be informed by the theory relevant to the concept, and the choice of items should be based on empirical considerations. The purpose of assessing both of these aspects is to ensure the validity of a construct operationalising a concept. DeVellis (2003) also recommended careful identification of the content domain to ensure correspondence between items and a concept. Churchill (1979), Clark and Watson (1995), and DeVellis presented step-by-step processes to develop and validate an instrument. This paper follows these proposed steps with some modifications to accommodate the contextual requirements of the current research. The modifications include guidelines provided by Clark and Watson to assess structural validity.
The various phases of the proposed methodology are discussed below. The substantive aspect of the methodology is outlined in the first five phases (specify domain of construct, focus group session, generate sample of items, content validity of items, and purify the measure and data collection), and the structural aspect of the methodology is addressed in another five phases (sample considerations, evaluation of item distribution, validity, unidimensionality and reliability).
Phases involved
Substantive aspect
The substantive aspect pertains to the conceptualisation of a construct and the development of an initial item pool. Conceptualisation involves identification of the ways in which a concept has been defined, described, and used in previous research. Furthermore, constructs that are closely and distantly associated with the target construct should be identified to inform the conceptualisation. According to Clark and Watson (1995), development of a precise and detailed conception of the target construct is an important initial step in conceptualising a construct. DeVellis argued for having clear thinking about the construct and ample knowledge of theory related to the concept under measurement (DeVellis, 2003, p. 60). Fleming-May (2014) noted the lack of clarity around key concepts in library and information science and suggested using conceptual analysis for identifying a concept’s characteristics and clarifying their meaning. Furner (2004) explored the concept of evidence using such an analysis, and suggested that the technique should be used to understand other concepts in the field of archival science. This technique has also been used in the nursing discipline to study the concept of information need (e.g., Timmins, 2006). The steps noted above should help to specify the domain of the target construct, that is, what is included in it and excluded from it.
Churchill (1979) recommended consulting the literature when specifying the boundaries of a construct. This consultation should include seminal papers pertaining to the target construct, studies involving description and/or measurement of the construct, and studies attempting to understand the construct in different contexts. Following this consultation, items capturing the domain of a construct can be generated. Different techniques can be used to inform the items generation phase including focus group sessions, experience surveys, and insight-stimulating examples (Selltisa et al. as cited in Churchill, 1979, p. 67). These items should be content validated, pilot tested, and then purified before a full-scale test. The steps in the substantive phase are described below:
Specify domain of construct
Specifying the domain of a construct entails identifying and reviewing the relevant literature and delineating what is included in, and what is excluded from, the definition of a construct. In other words, in this phase the boundaries of a construct are identified. For this purpose, a literature review should include any previous attempts to conceptualise and measure the target construct; furthermore, the review should even include studies of less immediately related constructs to clearly describe the boundaries of the target construct (Clark and Watson, 1995). In the construct development process, precise and detailed conception of the target construct and its theoretical context is a crucial first step (see e.g., Churchill, 1979; Clark and Watson, 1995; DeVellis, 2003). Accurate conceptual specification enables a researcher to identify the construct-relevant content. The literature review should also identify constructs that are closely and distantly associated with the target construct. Furthermore, it should examine any previous attempts to conceptualise the target construct.
During this phase, the domain of information need can be specified from the review of the literature and relevant knowledge base, and from expert guidance (i.e., consultations with relevant information scholars). The review of literature can include research on need and information need in the disciplines of psychology, economics, social psychology, nursing, and information research. This knowledge and expert guidance will enable a researcher to specify the domain of the construct of information need, which then can be used to develop a protocol for the second step, the focus group sessions.
Focus group sessions
The second step in the procedure for developing a construct is to operationalise it. Focus group sessions can be very helpful at this stage as they can help to understand peoples’ everyday understanding of the concept and its varied dimensions. Furthermore, having feedback from participants of different walks of life can lead to items (questions) that will be over-inclusive of the construct domain, an essential objective of construct operationalisation (see e.g., Clark and Watson, 1995). With this purpose in mind, a focus group session can be organised with a small but diverse group of participants. Participants’ different backgrounds (e.g., student, plumber, teen, senior citizen) help in developing a rich description of a concept. Effort should be made to guide the participants to talk about information need and its different aspects. Specific probes can be used to facilitate the discussion. The data from the focus group will help in understanding various aspects of information need. The focus group will also inform the step associated with the generation of an items pool.
A set of questions about the concept of information need can be prepared and then presented to a focus group session. Participants should be recruited from a variety of settings (e.g., academic and non-academic) to give a broad understanding of information need. Questions, for example, about information need, its different aspects, and its role in life can be asked to better understand its different dimensions. Data from this session can then be content analysed to identify major themes. This analysis will lead to the identification of the major dimensions of information need.
Generate sample items
The next step is to generate items that capture the domain of the construct of information need as specified in the previous steps. Based on the review of the literature and relevant knowledge base, expert advice, and feedback from the focus group session, a sample of items operationalising the concept of information need can be generated. The emphasis in this stage should be on generating items that could touch upon each of the dimensions of information need. This stage is very important to the construction of any measurement scale; Clark and Watson emphasised its centrality and noted that it is imperative to have the right items because deficiencies in items cannot be remedied by any existing data analysis technique. Towards the end of this phase, all items should be reviewed to ensure their wording is precise.
Based on the literature review, expert advice, and focus group session, dimensions of the concept of information need can be identified and labelled, for instance as (1) the nature of information need, (2) ensuing processes, (3) the role of information need in life, (4) its relationship with other needs, and (5) quality. Then the next step is to write items covering each of these five dimensions, and the content of each item, according to DeVellis (2003), must be sampled carefully to reflect every dimension. It is recommended to have at least three items representing each dimension (see e.g., Cook et al., 1981; Field, 2005). Items representing the dimension of (3), for example, can include statements such as ‘decisions always require information’ and ‘I need information whenever I face a new problem’.
Content validity of items
Haynes, Richard, and Kubany (1995) defined content validity as ‘the degree to which elements of an assessment instrument are relevant to and representative of the targeted construct for a particular assessment purpose’ (p. 238). Some authors (e.g., Gable, 1986), argue that the content validity of items should receive the most attention during the instrument development process. Content validity is an important aspect of the overall validity and demonstrates the observational meaningfulness of a concept (Bagozzi, 1980). According to Srite (2000), content validity shows the relationship between a concept and its operationalisation. Worthington and Whittaker (2006) considered content validation as one of the practices most important to scale development.
A technique developed by Lawshe (1975) can be used to assess the content validity of generated items. According to Lawshe’s technique, items could be sent to domain experts researching information need that ask them to rate each item on a scale from 1 (it is not necessary) to 3 (it is essential). The responses from all domain experts can then be pooled and the number indicating essential can be determined for each item. Lawshe noted that 'any item, performance on which is perceived to be "essential" by more than half of the panelists [domain experts], has some degree of content validity’ (p. 567). Based on the ratings of domain experts, a content validity ratio is calculated for each item, which then leads to the calculation of a content validity index for the whole item pool. Depending on this evaluation the initial sample of items can be purified.
It is important to note that items shouldn’t be chosen solely on empirical grounds (e.g., content validity index). There can be instances in which, despite domain experts’ rating down an item, the researcher may still decide to keep that item on purely theoretical grounds. For instance, McCay-Peet et al. (2014) identified five dimensions of the concept of serendipity and developed forty-three items representing these dimensions. They sent these items to domain experts for content validation and reduced the total number of items, based on experts’ feedback and using their own judgement, to thirty-five.
All items operationalising the concept of information need can be sent to domain experts. Based on Lawshe’s approach these experts can be asked to rate each item on a scale from 1 to 3. The responses will be pooled to determine the number indicating essential for each item. Using pooled data and theoretical motivations the items can be further refined, resulting in modification in and deletion of some items.
Purify the measure and collect data
After content validation of the items, a questionnaire can be developed and, for example, sent to a few participants for comments on the overall layout and content. The questionnaire can then be revised according to the comments and pilot tested with a sample. Results of the pilot test can help to further purify the questionnaire. Purification at this stage generally entails examination of (a) comments by respondents, (b) correlation of an item with its respective dimension, and (c) inter-item correlation. This analysis can lead to the deletion and/or refining of items with poor loadings, cross loadings, and poor reliability values. The purpose of such purification is to increase the correspondence between the conceptualisation of a concept (e.g., information need) and its operationalisation. The purpose of purification is to further refine an instrument by including only those items that are a good representation of a concept. Purification is done both at the end of a pilot test and also the full-scale test. Furthermore, purification of a scale should be based on both theoretical and statistical considerations. Specifically, items shouldn’t be deleted solely based on correlations and other statistical estimates, as it is possible that an item faring poorly on statistical grounds still warrants retaining for theoretical reasons, as discussed above.
During this phase, items representing each dimension of information need should be inspected for their loadings and cross-loadings. Loadings represent the strength of relationship between an item and its respective dimension. If items of any dimension of the construct, for example, information need’s dimension, nature of information need, correlate with another dimension then there will be a need to further refine the content of those items. This will ensure that the items accurately represent the underlying dimension of the construct.
Purification entails paying attention to both substantive and structural aspects; a description of the latter follows.
Structural aspect
The structural aspect entails the selection of items from the sample of items generated and validated during steps three to five above and their psychometric evaluation. The purpose of this phase is to ensure that items are empirically valid and correspond to the theoretical basis developed during the substantive phase. When discussing the structural validity of newly created items, Clark and Watson (1995) suggested a set of guidelines that should be followed to assess the validity and reliability of the items, thereby ensuring that requirements of the structural aspect are met. The guidelines include (a) sample consideration, (b) evaluation of item distribution, and (c) assessment of unidimensionality. In addition to these guidelines, two specific procedures should also be used, namely, exploratory factor analysis and coefficient alpha, sometimes referred to as Cronbach’s alpha (Cronbach, 1951). Exploratory factor analysis can be used to assess convergent and discriminant validity, two important aspects of validity (Campbell and Fiske, 1959, p. 81) and coefficient alpha can be used to assess reliability. Two tests can be done: (1) a pilot test with a small sample of the population and (2) a full-scale test with a larger sample. All three guidelines should be followed during both tests. A description of the guidelines and issues of validity and reliability is provided below.
Sample considerations
Sample size is important for many reasons. For example, it is important because the statistical power of a test to detect significance increases with the increase in sample size; the detrimental effects of non-normality are reduced with a large sample (Hair et al., 2006); and patterns of covariation among items become stable (DeVellis, 2003). Statistical techniques such as exploratory factor analysis require a certain number of observations for every item to produce reliable results (see e.g., Field, 2005; Hair et al., 2006). According to DeVellis, using a small sample can pose some risks including (1) inaccurate assessment of internal consistency and (2) non-representation of the population for which the measurement instrument is intended. Clark and Watson (1995) recommended using a sample of 100–200 participants to pilot test the new item pool, and a minimum sample of 300 participants for a full-scale test.
Evaluation of item distributions
Clark and Watson (1995) recommended eliminating any items with highly skewed and unbalanced distributions and retaining items depicting a broad range of distributions. This attribute, a broad range of distribution, is considered by DeVellis (2003) as a valuable quality of a scale item. As far as elimination of items with highly skewed distribution is concerned, Clark and Watson provide three reasons for their recommendation: (1) Likert scale questions where respondents are likely to provide similar responses are likely to be highly skewed items and, therefore, convey little information; (2) limited variability in such items will cause a weak correlation between these items and the other items on a measurement scale, which will pose problems for further analysis; and (3) items with skewed distributions can produce highly unstable correlational results (p. 315). Concerning their recommendation to retain items with a broad range of distribution, Clark and Watson (p. 315) argue that,
most constructs are conceived to be—and, in fact are empirically shown to be—continuously distributed dimensions, and scores can occur anywhere along the entire dimension. Consequently, it is important to retain items that discriminate at different points along the continuum.
It can therefore be suggested that items operationalising the construct of information need should have relatively high variance. Items inviting identical responses should be avoided because such items will provide minimal information regarding participants’ understanding of the concept of information need and its different aspects.
Validity
The concept of validity is at the heart of measurement. Cook and Campbell (as cited in Bagozzi, 1980, p. 421) stated that validity represents the degree of accuracy in measuring a concept through operationalisation. According to Hair et al., (2006, p. 3) ‘validity is the extent to which a measure [item] or set of measures correctly represent the concept of study’ . Validity represents the appropriateness of a measure and indicates whether it is appropriately measuring a construct or not. To demonstrate the validity of a construct it is important that, in addition to content validity and reliability, convergent and discriminant validity also be assessed. According to Straub, Boudreau and Gefen (2004, p. 21), 'Convergent validity is evidenced when items thought to reflect a construct converge, or show significant, high correlations with each other, particularly when compared to the convergence of items relevant to other constructs, irrespective of method'.
Convergent validity is evident when terms thought to measure a concept represent a higher correlation with each other as compared with the correlations with other concepts. Exploratory factor analysis can be used to assess the convergent validity of items proposed to be operationalising the concept of information need. Discriminant validity represents the degree to which the measures (items) that ought to reflect a concept are distinct. An indication of the existence of a concept is that its measures should be distinct from those that are not believed to represent that concept (Straub et al., 2004).
A set of items developed to operationalise the construct of information need cannot claim to represent this construct unless empirical assessment identifies a common dimension underlying these items. Exploratory factor analysis can be used for such empirical assessment, encompassing discriminant and convergent validity. This analysis will also aid in identifying any sub-dimensions represented by the items operationalising information need’s construct. It is, however, important to note that, in addition to empirical considerations, theoretical underpinnings should also be considered when identifying, describing, and explaining dimensions identified through exploratory factor analysis.
Unidimensionality
According to Hattie (1985, p. 157), ‘unidimensionality can be defined as the existence of one latent trait underlying the data’. In other words, a measure is said to be unidimensional when it measures only the trait for which it was developed; emphasising the centrality of unidimensionality, Hattie stated, ‘one of the most critical and basic assumptions of measurement theory is that a set of items forming an instrument all measure just one thing in common’ (p. 139). It is customary to assess unidimensionality using Cronbach’s alpha; however, many psychometricians question this practice (see e.g., Boyle, 1991). According to Clark and Watson (1995) it is important to distinguish between internal consistency and unidimensionality. They noted that ‘internal consistency refers to the overall degree to which the items make up a scale are intercorrelated, whereas… unidimensionality indicate[s] whether the scale items assess a single underlying factor or construct’ (p. 315). Subsequently, they suggested a few guidelines to assess unidimensionality, including (1) examining the inter-item correlation mean, (2) examining the range and distribution of those correlations, (3) ensuring individual inter-item correlations fall somewhere in the range of 0.15 to 0.50, and (4) ensuring that inter-item correlations cluster narrowly around the mean value. These four guidelines must be followed to ascertain the unidimensionality of the information need scale items.
Reliability
Unidimensionality alone, however, is not enough to ensure the usefulness of a scale (Gerbing and Anderson, 1988); it is also essential to ascertain the scale’s reliability, the next step in the empirical validation of an information need measurement scale. Reliability is ‘the degree to which measures are free from error and therefore yield consistent results’ (Peter, 1979, p. 7). A reliable measure represents a substantial correlation with itself (Peter, 1981) and provides an opportunity to replicate studies and validate measures. Internal consistency [reliability] is concerned with the homogeneity of observations (Bagozzi, Yi, and Phillips, 1991). Reliability represents the ability of items in measuring a construct consistently over repetitive instances using similar participants under the same or different approaches.
Following these analyses (i.e., exploratory factor analysis, unidimensionality analysis, and reliability analysis) the items should be refined further; that is, items with lower than standard inter-item correlations should be deleted. This process will lead to a scale of information need that will be further tested. For the full-scale test, a survey can be distributed to a large sample population (at least 300). Responses from this survey will be again analysed for discriminant and convergent validity (using exploratory factor analysis), unidimensionality, and reliability (using Cronbach’s alpha).
The steps discussed above will be used in an on-going research project to develop a refined scale, ready for use in studies aiming to empirically examine the concept of information need. It is hoped that adherence to the proposed steps (see Figure 1) will lead to rigorous assessment of substantive and structural aspects of constructs and will enable us to develop theoretical networks applicable to a wide range of human information behaviour.
Conclusion
Information need is central to our professional practice and is important to understanding users and their information behaviour. However, despite its centrality, there is still lack of understanding as to what really information need is and what its dimensions are. There is a significant body of research on information needs, including its assessment in different user populations, processes involved in satisfying user needs, and analyses of research on information needs. However, there is a need to go beyond the approaches used thus far. Specifically, there is a need for a construct of information need that is not only well understood (conceptualised) but also operationalised. The construct needs to be linked with a set of rigorous measurement techniques or procedures so that it can be empirically validated in different settings and with different research problems. This is important because without having testable constructs, a parsimonious, methodologically rigorous, and empirically robust theory of human-information behaviour will remain in its infancy.
This paper has used the concept of information need as a starting point to propose a methodology. Steps of this methodology have been explained and the ways in which these steps can be applied to the concept of information need are also suggested. This methodology can be used to conceptualise, operationalise, and empirically validate the concept of information need, notwithstanding that its application will require a significant investment of time. This methodology, in its application, can be very laborious as there are multiple steps involved and some steps may require repetition to attain accuracy. Furthermore, an advanced level of expertise in certain qualitative and quantitative methods will be essential to ensure correspondence between theoretical underpinnings and operational representation of any construct. It is hoped that the application of this methodology will lead to the development of a testable construct of information need. This approach makes a valuable addition to the methodological repertoire available to studies that aim to develop a construct, and hence will also contribute to the overall theory development process in information research.
Acknowledgements
I want to thank SIG-USE ASIS&T for supporting this research by awarding me the Elfreda Chatman Research Award. I am also grateful to the Charles Sturt University School of Information Studies for supporting this research by awarding me the sabbatical leave.
I am grateful to Professor Donald Case for giving valuable advice on various aspects of this research. Professor Lisa Given and Professor Annemaree Lloyd also provided very helpful feedback on earlier drafts of this paper. I would like to thank the anonymous reviewers and the Regional Editor for their helpful feedback and suggestions for improvements to this paper. Finally, thanks go to Shoaib Tufail for his research assistance.
About the author
Waseem Afzal is a faculty member at the Charles Sturt University School of Information Studies with an MBA and a PhD from the Emporia State University. His research interests focus on human information behaviour, information need and its role in shaping perception; distributional properties of information, and economics of information.
References
- Agarwal, R. & Prasad J. (1997). The role of innovation characteristics and perceived voluntariness in the acceptance of information technologies. Decision Sciences, 28(3), 557-582.
- Bagozzi, R.P. (1980). Causal models in marketing. New York, NY: John Wiley and Sons.
- Bagozzi, R.P., Yi, Y. & Phillips, L.W. (1991). Assessing construct validity in organisational research. Administrative Science Quarterly, 36(3), 421-458.
- Bates, M.J. (2002). Toward an integrated model of information seeking and searching. The New Review of Information Behaviour Research, 3, 1-15.
- Belkin, N.J. (1980). Anomalous states of knowledge as a basis for information retrieval. Canadian Journal of Information Science, 5, 133-143.
- Belkin, N.J. (1993). Interaction with texts: Information retrieval as information-seeking behavior. In Information Retrieval '93, Von der Modellierung zur Anwendung (pp. 55-66). Konstanz, Germany: Universitätsverlag Konstanz.
- Belkin, N.J., Oddy, R.N. & Brooks, H.M. (1982). ASK for information retrieval: part I. Background and theory. Journal of Documentation, 38(2), 61-71.
- Bertulis, R. & Cheeseborough, J. (2008). The Royal College of Nursing's information needs survey of nurses and health professionals. Health Information and Libraries Journal, 25(3), 186-197.
- Boyle, G.J. (1991). Does item homogeneity indicate internal consistency or item redundancy in psychometric scales? Personality and Individual Differences, 12(3), 291-294.
- Campbell, D.T. & Fiske, D.W. (1959). Convergent and discriminant validation by the multitrait-multimethod matrix. Psychological Bulletin, 56(2), 81-105.
- Case, D.O. (2012). Looking for information: a survey of research on information seeking, needs, and behavior. Amsterdam, The Netherlands: Academic Press.
- Churchill, G.A. (1979). A paradigm for developing better measures of marketing constructs. Journal of marketing Research, 16(1), 64-73.
- Clark, L.A. & Watson, D. (1995). Constructing validity: basic issues in objective scale development. Psychological Assessment, 7(3), 309-319.
- Cole, C. (2012). Information need: a theory connecting information search to knowledge formation. Medford, NJ: Information Today Inc.
- Cook, J.D., Hepworth, S.J., Wall, T.D. & Warr, P.B. (1981). The experience of work. San Diego, CA: Academic Publications.
- Cronbach, L.J. (1951). Coefficient alpha and the internal structure of tests. Psychometrika, 16(3), 297-334.
- Derr, R.L. (1983). A conceptual analysis of information need. Information Processing and Management, 19(5), 273-278.
- Dervin, B, & Nilan, M. (1986). Information needs and uses. Annual Review of Information Science and Technology, 21, 3-33.
- DeVellis, R.F. (2003). Scale development: theory and applications. (2nd ed.). Thousand Oaks, CA: Sage Publications.
- Field, A. (2005). Discovering statistics using SPSS. (2nd ed.). London: Sage Publications.
- Fleming-May, R.A. (2014). Concept analysis for library and information science: exploring usage. Library & Information Science Research, 26(3-4), 203-210.
- Furner, J. (2004). Conceptual analysis: a method for understanding information as evidence, and evidence as information. Archival Science, 4(3-4), 233-265.
- Gable, R. K. (1986). Instrument development in the affective domain. Boston, MA: Kluwer-Nijhoff.
- Gerbing, D.W. & Anderson, J.C. (1988). An updated paradigm for scale development: incorporating unidimensioanlity and its assessment. Journal of Marketing Research, 25(2), 186-192.
- Greer, R.C., Grover, R.J. & Fowler, S.G. (2007). Introduction to the library and information professions. Westport, CT: Libraries Unlimited.
- Hair, J.F., Black, W.C., Babin, B.J., Anderson, R.E. & Tatham, R.L. (2006). Multivariate data analysis. (6th ed.). Upper Saddle River, NJ: Pearson Prentice Hall.
- Hattie, J. (1985). Methodology review: assessing unidimensionality of tests and items. Applied Psychological Measurement, 9(2), 139-164.
- Haynes, S.N., Richard, D.C.S. & Kubany, E.S. (1995). Content validity in psychological assessment: a functional approach to concepts and methods. Psychological Assessment, 7(3), 238-247.
- Inskip, C., Butterworth, R. & MacFarlane, A. (2008). A study of the information needs of the users of a folk music library and the implications for the design of a digital library system. Information Processing and Management, 44(2), 647-662.
- Jaccard, J. & Jacoby, J. (2010). Theory construction and model-building skills. New York, NY: Guilford Press.
- Krikelas, J. (1983). Information-seeking behavior: patterns and concepts. Drexel Library Quarterly, 19(2), 5-20.
- Kuhlthau, C.C. (1991). Inside the search process: information seeking from the user’s perspective. Journal of the American Society for Information Science, 42(5), 361-371.
- Lawshe, C.H. (1975). A qualitative approach to content validity. Personnel Psychology, 28(4), 563-575.
- Lin, H-F. (2011). An empirical investigation of mobile banking adoption: the effect of innovation attributes and knowledge-based trust. International Journal of Information Management, 31(3), 252-260.
- Line, M.B. (1974). Draft definitions: information and library needs, wants, demands and uses. Aslib Proceedings, 26(2), 87.
- Loevinger, J. (1957). Objective tests as instrument of psychological theory. Psychological Reports, 3(3), 635-694.
- McCay-Peet, L., Toms, E.G. & Kelloway, E.K. (2014). Development and assessment of the content validity of a scale to measure how well a digital environment facilitates serendipity. Information Research, 19(3), paper 630. Retrieved from http://www.informationr.net/ir/19-3/paper630.html#.VdFDsUZKXec (Archived by WebCite® at http://www.webcitation.org/6qc8Ti1GE)
- Moore, G.C. & Benbasat, I. (1991). Development of an instrument to measure the perceptions of adopting an information technology innovation. Information Systems Research, 2(3), 192-222.
- Naumer, C.M. & Fisher, K.F. (2010). Information needs. In M.J. Bates & M.N. Maack (Eds.), Encyclopedia of library and information sciences (3rd ed.) (pp. 2452-2458). London: Taylor & Francis.
- Nicholas, D. (2000). Assessing information needs: tools, techniques and concepts for the Internet age. London: ASLIB.
- O’Brien, H.L. & Toms, E.G. (2010). The development and evaluation of a survey to measure user engagement. Journal of the American Society for Information Science and Technology, 61(1), 50-69.
- Odongo, R.I. & Ocholla, D.N. (2003). Information needs and information-seeking behavior of artisan fisher folk of Uganda. Library and Information Science Research, 25(1), 89-105.
- Perley, C.A., Gentry, C.A., Fleming, A.S. & Sen, K.M. (2007). Conducting an information needs assessment: the Via Christi Libraries’ experience. Journal of the Medical Library Association, 95(2), 173-181.
- Peter, J.P. (1979). Reliability: a review of psychometric basics and recent marketing practices. Journal of Marketing Research, 16(1), 6-17.
- Peter, J.P. (1981). Construct validity: a review of basic issues and marketing practices. Journal of Marketing Research, 18(2), 133-145.
- Pitts, J., Bonella, L. & Coleman, J. (2012). We built it, why didn't they come? In F. Baudino & C. Johnson (Eds.), Brick and click libraries: an academic library symposium (pp. 141-151). Maryville, MO: Northwest Missouri State University.
- Rogers, E.M. (1983). Diffusion of innovations (3rd ed.). NY: The Free Press.
- Savolainen, R. (2012). Conceptualising information need in context. Information Research, 17(4), paper 534. Retrieved from http://informationr.net/ir/17-4/paper534.html (Archived by WebCite® at http://www.webcitation.org/6qc9Qhx7k)
- Shenton, A.K. & Dixon, P. (2004). The nature of information needs and strategies for their investigation in youngsters. Library and Information Science Research, 26(3), 296-310.
- Shpilko, I. (2011). Assessing information-seeking patterns and needs of nutrition, food science, and dietetics faculty. Library and Information Science Research, 33(2), 151-157.
- Spink, A., & Cole, C. (2006). Human information behaviour. Integrating diverse approaches and information use. Journal of the Association for Information Science and Technology, 57(1), 25-35.
- Srite, M. (2000). The influence of national culture on the acceptance and use of information technologies: an empirical study. Unpublished doctoral dissertation, Florida State University, Tallahassee, FL, USA.
- Straub, D.W., Boudreau, M.C. & Gefen, D. (2004). Validation guidelines for IS positivist research. Communications of the Association for Information Systems, 13(1), 380-427.
- Sundin, O. & Johannisson, J. (2005). The instrumentality of information needs and relevance. In F. Crestani & I. Ruthven (Eds.), Proceedings of the 5th International Conference on Conceptions of Library and Information Sciences, CoLIS 2005 (pp. 107-118). Berlin: Springer.
- Taylor, R.S. (1962). The process of asking questions. American Documentation, 13(4), 391-396.
- Taylor, R.S. (1968). Question-negotiation and information seeking in libraries. College and Research Libraries, 29(3), 178-194.
- Timmins, F. (2006). Exploring the concept of ‘information need’. International Journal of Nursing Practice, 12(6), 375-381.
- Turel, O., Serenko, A. & Giles, P. (2011). Integrating technology addiction and use: an empirical investigation of online auction users. Management Information Systems Quarterly, 35(4), 1043-1061.
- Venkatesh, V., Morris, M.G., Davis, G.B. & Davis, F.D. (2003). User acceptance of information technology: toward a unified view. MIS Quarterly, 27(3), 425-478.
- Wallander, J.L., Schmitt, M. & Koot, H.M. (2001). Quality of life measurement in children and adolescents: issues, instruments, and applications. Journal of Clinical Psychology, 57(4), 571-585.
- Williamson, K. (1998). Discovered by chance: the role of incidental information acquisition in an ecological model of information use. Library & Information Science Research, 20(1), 23-40.
- Wilson, T.D. (1981). On user studies and information needs. Journal of Documentation, 37(1), 3-15.
- Wilson, T.D. (1994). Information needs and uses: fifty years of progress? In B.C. Vickery (Ed.), Fifty years of information progress: a Journal of Documentation review (pp. 15-51). London: Aslib.
- Worthington, R. L. & Whittaker, T. A. (2006). Scale development research: a content analysis and recommendation for best practices. The Counseling Psychologist, 34(6), 806-838.