BOOK AND SOFTWARE REVIEWS
Hansen , Derek, Shneiderman, Ben, and Smith, Marc A. Analyzing social media networks with NodeXL: insights from a connected world.. Massachusetts: Morgan Kaufmann, 2010. xv, 304 p. ISBN 978-0-12-382229-1. $44.95
The last decade has seen intense interest among researchers and other groups in both analysing and visualizing social networks. The concept of social networks is not new - from time immemorial, people have used affiliations to live in communities and carry out endeavors from hunting for food and arranging marriages to running businesses. In our times, digital technologies, and especially the Internet, have given completely new meaning to social interaction. Millions of people across the globe are using social media sites like Facebook, YouTube, Flickr, discussion boards, blogs, and other online platforms to meet new friends, keep in touch with current friends, organize political rallies, share videos and photos, discuss the launch of a new product, rate an existing product, or simply communicate. In 2009, the overall traffic from online social networking sites surpassed that of e-mail, ushering in a new era of social media that was here to stay. So, what do we do with the enormous amount of data emerging online?
Tools to analyse social relationships have been around since the 1990s. However, the relatively long learning curve associated with such software has kept most practitioners from using the applications. In addition, the majority of these software tools do not yet have the functionality to procure and analyse online data resulting from the explosion in social media space. Launched around December 2009, NodeXL (earlier known as .Netmap) for the first time made it possible for users to directly import live data from sites like Twitter, YouTube, and Flickr. Its open source availability as a template for Excel 2007 and Excel 2010 made it appear, from day one, to be a familiar software application. NodeXL has been adopted as the preferred tool for a number of network analysis courses.
This book is one of the few software tutorial books written by authors who are part of the group that developed the software. Hence, software and book are inseparable. According to the authors, the aim is to "substantially lower the barrier to entry for social media network analysis while at the same time raising the power offered to users seeking network insights" (p. ix).
The book assumes no previous knowledge of network analysis and is written with both practitioners and researchers in mind. The book will benefit researchers in the field of information sciences as well as practitioners as they try to improve the value of their social media endeavours.
The authors describe the organization of the book as a tree consisting of three parts - root (getting started), trunk (NodeXL tutorial), and branches (case studies). The three parts follow a clear sequence: First, readers learn the theory, then they learn about the tool, and finally they apply the tool to analyse real social media content. In all, there are fifteen chapters, each chapter having an outline, an introduction, a practitioners' summary, and a researchers' agenda. The book concludes with detailed references and a list of additional resources that readers may find useful. The practitioners' summary is the usual end-of-chapter summary. The authors labelled it a practitioners' summary to indicate that practitioners who do not have enough time to read the entire chapter can still learn the essence by reading the summary. Throughout the book, "advanced topics" text boxes provide advanced theoretical, technical, and historical detail
Part One (Chapters 1 through 3) introduces the reader to the world of social network analysis and social media by describing their historical and fundamental concepts. It also discusses various social media tools that people use to communicate with one another and formal network analysis techniques that can explain those communications. Chapter 1 is comparatively small and covers topics like the historical perspective, the rise of social media as consumer applications, and the application of social media to national priorities. Discussion of these topics provides a high-level overview of network science and social media initiatives and explains how juxtaposing the two could explain the emergence, structure, and dynamics of social media. In Chapter 2, the authors define social media as "a set of online tools that supports social interaction between users" (p. 12).
I like this succinct definition, which says virtually everything about social media in just eleven words. As implied in the definition, social interaction is what makes social media different from media such as television.
In Chapter 3, the authors lay out a design framework for comparing social media tools. The framework has six dimensions: size of producer and consumer population, pace of interaction, genre of basic elements, control of basic elements, types of connections, and retention of content. This framework provides an excellent way to classify and compare social media tools. One table divides social media into eleven types, replete with examples of sites on the Web, including unfamiliar types such as idea generation and mobile-based service. The chapter provides in-depth discussion of the design space of social media tools and the type of connections they create. I think this chapter is one of the most complete primers on social media I have ever read. The authors also describe social network analysis from the perspective of social media. Global features of networks, such as diameter, geodesic distance, degree distribution, density, centralization, community structures, components, and local features such as centrality measures (degree, closeness, betweenness, page-rank, and eigen vector), and clustering coefficient of a vertex help readers understand the overall structure of the network. Graph metrics reveal key people who control communications in the network. The Stanford Network Application Platform is used in NodeXL for the calculation of certain metrics. How networks grow, change, or fail is detected by analysing the network from the temporal perspective. Several advanced-topic text boxes pop up in this chapter, indicating the abstract nature of the subject. Practitioners may want to skip this chapter, but I strongly advise they go through it in its entirety, as it establishes the foundation for the next two parts of the book - learning how to use NodeXL and NodeXL applications.
Part Two consists of four chapters (Chapters 4 through 7). It is a learning-by-doing guide on operating the software. Unlike other software like Pajek, which uses a matrix, NodeXL uses just an edge list to construct relationships. This section of the book is similar to the how-to guides for learning software that we find in our local bookshops. Because NodeXL is a software utility and not a computer programming language, the authors did right to limit the section size and not unnecessarily bloat it. Part Two starts by guiding the user on how to download, install, and run the software. Actual screen captures and an informal style of writing help the user feel as if a personal tutor is present. One of the first network diagrams is shown using a simple friendship network. Authors use datasets, which users can download from the book's Website, to illustrate the calculation of graph metrics and the visualization of networks (see Figures 2 and 3). Again, a large dataset retrieved from blog posts and discussions on the seriouseats.com Website are used to illustrate how data preparation and filtering can provide meaning and sense to dense networks. Part Two concludes with an extensive discussion on clustering and grouping.

Figure 1. Visualization of the centre of my e-mail network, following the instructions in the book.
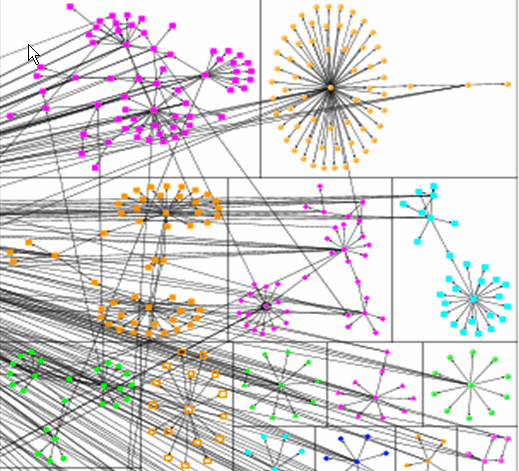
Figure 2. Some of the clusters in my e-mail network.
Clustering and grouping help in segregating the network into smaller groups based either on vertex attribute or certain established community structure detection algorithms (see Figure 3). The 2007 US Senate voting pattern dataset (a now famous example used by several network analysis software applications to demonstrate the efficacy of their software) is used in the book to identify clusters of senators who are grouped together based on similar voting patterns.
Although it should not take more than eight to ten hours for users to learn the basics of NodeXL and start producing these graphs, applying NodeXL to real-world problems could take significant effort and time.
Part Three contains chapters that the authors refer to as branches of the book. This part includes eight chapters (Chapters 8 through 15), each covering in detail one form of social media (e.g., e-mail, thread networks, WWW hyperlink networks, Facebook, Flickr, Twitter, YouTube, and Wiki networks). Having each social medium covered in a separate chapter is a great way to help the reader understand the related system, its nature, and the types of analysis that can be carried out to identify influential individuals, documents, or groups. Such classification also helps readers who may be interested in analysing only a certain social medium (e.g., Twitter) to zoom in directly to the chapter. Case studies are written by twelve different authors, many of whom are part of the NodeXL development team. How data from social media sites like Twitter, Facebook (slight extra work needed), and WWW hyperlink networks (using VOSON) can be imported directly into NodeXL is demonstrated. I think directly importing online data will be among the most important reasons you consider using NodeXL in the first place.
The book ends with an appendix for programmers.
I had been using NodeXL before reading this book, and I must say that the software itself took on new meaning for me after I finished it. Having NodeXL software installed on your computer without having access to this book is like having all the ingredients in your kitchen to make a pudding but no cookbook with the recipe.
NodeXL software itself is updated virtually every month. A few features have been added that are not described in the book (e.g., placing groups in separate boxes). Some old features became redundant and disappeared in the new version (e.g., Schemes). Hence, I would suggest the writers of this book plan a new edition by the end of this year or early next year to incorporate all the new features of the software.
This book is a must-read for anyone who wants new insight into the many ways NodeXL can be used to analyse social media. I also strongly recommend that network researchers take a break from UCINET and Pajek and add knowledge of yet another network analysis software to their arsenal of tools. The simple style of this book will get them up and going in no time.